本文最后更新于12 天前,其中的信息可能已经过时,如有错误请发送邮件到big_fw@foxmail.com
学习目标:
- 熟悉 Advanced RAG的基本作用
- 熟悉 前索引优化方式
- 熟悉 查询优化方式
- 熟悉 后索引优化方式
一. Advanced RAG概述
Advanced RAG重点聚焦在检索增强,即优化Retrieval阶段。增加了Pre-Retrieval预检索和Post-Retrieval后检索阶段。
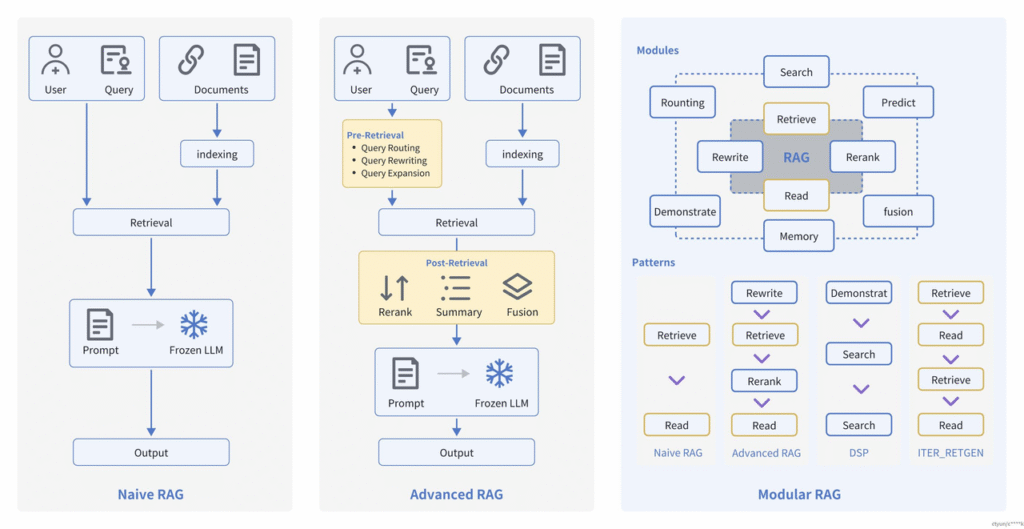
基于朴素RAG,高级RAG主要通过预检索策略和后检索策略来提升检索质量。
预检索过程
高级RAG着重优化了索引结构和查询的方式。优化索引旨在提高被索引内容的质量,包括增强数据颗粒度、优化索引结构、添加元数据、对齐优化和混合检索等策略。查询优化的目标则是明确用户的原始问题,使其更适合检索任务,使用了查询重写、查询转换、查询扩展等技术。
后检索过程
对于由问题检索得到的一系列上下文,后检索策略关注如何优化它们与查询问题的集成。这一过程主要包括重新排序和压缩上下文。重新排列检索到的信息,将最相关的内容予以定位标记,这种策略已经在LlamaIndex2、LangChain等框架中得以实施。直接将所有相关文档输入到大型语言模型(LLMs)可能导致信息过载,为了缓解这一点,后检索工作集中选择必要的信息,强调关键部分,并限制了了相应的上下文长度。
二. Pre-Retrieval预检索-优化索引
1. 摘要索引
1.1 痛点分析
在处理大量文档时,如何快速准确地找到所需信息是一个常见挑战。摘要索引可以用来处理半结构化数据,比如许多文档包含多种内容类型,包括文本和表格。这种半结构化数据对于传统 RAG 来说可能具有挑战性,文本拆分可能会分解表,从而损坏检索中的数据;嵌入表可能会给语义相似性搜索带来挑战。
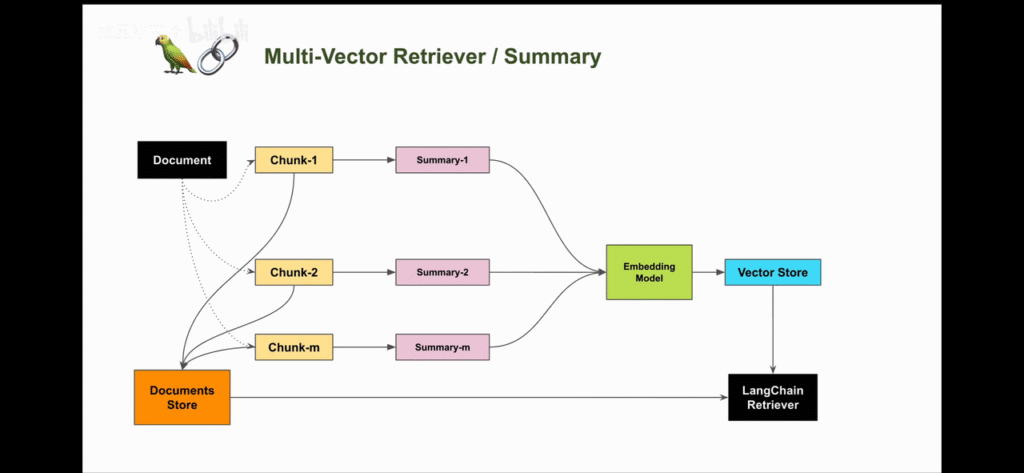
1.2 解决思路:
- 让LLM为每个块生成summary,并作为embedding存到summary database中
- 在检索时,通过summary database找到最相关的summary,再回溯到原始文档中去
- 将原始文本块作为上下文发送给LLM以获取答案
1.3 整体代码
from langchain.storage import InMemoryByteStore
from langchain_chroma import Chroma
from langchain_community.document_loaders import UnstructuredWordDocumentLoader, WebBaseLoader
from langchain_ollama import OllamaEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai.chat_models import ChatOpenAI
from langchain.retrievers import MultiVectorRetriever
import uuid
from langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableMap
from langchain_huggingface import HuggingFaceEmbeddings
import os
url = "https://news.pku.edu.cn/mtbdnew/15ac0b3e79244efa88b03a570cbcbcaa.htm"
# 初始化文档加载器列表(加载多个文本文件)
loaders = [
UnstructuredWordDocumentLoader("mianshi.docx"),
WebBaseLoader(url)
]
# 加载并合并所有文档
docs = []
for loader in loaders:
docs.extend(loader.load())
# print(docs)
# 初始化递归文本分割器(设置块大小和重叠)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024, chunk_overlap=100)
docs = text_splitter.split_documents(docs)
# print(docs)
llm = ChatOpenAI(api_key="1",
base_url="http://127.0.0.1:11434/v1",
model='qwen3:8b')
# 创建摘要生成链
chain = (
{"doc": lambda x: x.page_content}
| ChatPromptTemplate.from_template("总结下面的文档:\n\n{doc}")
| llm
| StrOutputParser()
)
# 批量生成文档摘要(最大并发数5)
summaries = chain.batch(docs, {"max_concurrency": 5})
# print(summaries)
# 初始化嵌入模型(用于文本向量化)
embeddings_model = OllamaEmbeddings(
model="embeddinggemma:latest",
base_url="http://localhost:11434"
)
# 初始化Chroma实例(用于存储摘要向量)
vectorstore = Chroma(
collection_name="summaries",
embedding_function=embeddings_model
)
# 初始化内存字节存储(用于存储原始文档)
store = InMemoryByteStore()
# 初始化多向量检索器(结合向量存储和文档存储)
id_key = "doc_id"
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
byte_store=store,
id_key=id_key,
)
# 为每个文档生成唯一ID
doc_ids = [str(uuid.uuid4()) for _ in docs]
# 创建摘要文档列表(包含元数据) metadata可以用来关联原始文档和摘要文档会自动找到匹配关系
summary_docs = [
Document(page_content=s, metadata={id_key: doc_ids[i]}) for i, s in enumerate(summaries)
]
# 将摘要添加到向量数据库
retriever.vectorstore.add_documents(summary_docs)
# 将原始文档存储到字节存储(使用ID关联)
retriever.docstore.mset(list(zip(doc_ids, docs)))
# 执行相似性搜索测试
sub_docs = retriever.vectorstore.similarity_search("病假的请假流程?")
print("-------------匹配的摘要内容--------------")
print(sub_docs[0])
# 获取第一个匹配摘要的ID
matched_id = sub_docs[0].metadata[id_key]
# 通过ID获取原始文档
original_doc = retriever.docstore.mget([matched_id])
print("-------------对应的原始文档--------------")
print(original_doc)
prompt = ChatPromptTemplate.from_template("根据下面的文档回答问题:\n\n{doc}\n\n问题: {question}")
# 生成问题回答链
chain = RunnableMap({
"doc": lambda x: retriever.get_relevant_documents(x["question"]),
"question": lambda x: x["question"]
}) | prompt | llm | StrOutputParser()
# 生成问题回答
query = "病假的请假流程?"
answer = chain.invoke({"question": query})
print("-------------回答--------------")
print(answer)
retrieved_docs = retriever.invoke(query)
print("-------------检索到的文档--------------")
print(retrieved_docs)1.4 数据准备
- 使用 TextLoader 加载本地的文本文件
from langchain.storage import InMemoryByteStore
from langchain_chroma import Chroma
from langchain_community.document_loaders import UnstructuredWordDocumentLoader, WebBaseLoader
from langchain_ollama import OllamaEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai.chat_models import ChatOpenAI
from langchain.retrievers import MultiVectorRetriever
import uuid
from langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableMap
from langchain_huggingface import HuggingFaceEmbeddings
import os
url = "https://news.pku.edu.cn/mtbdnew/15ac0b3e79244efa88b03a570cbcbcaa.htm"
# 初始化文档加载器列表(加载多个文本文件)
loaders = [
UnstructuredWordDocumentLoader("mianshi.docx"),
WebBaseLoader(url)
]
# 加载并合并所有文档
docs = []
for loader in loaders:
docs.extend(loader.load())
print(docs)
# 初始化递归文本分割器(设置块大小和重叠)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024, chunk_overlap=100)
docs = text_splitter.split_documents(docs)
print(docs)1.5 构建摘要生成链
- 使用llm跨文档批量生成文档摘要
llm = ChatOpenAI(api_key="1",
base_url="http://127.0.0.1:11434/v1",
model='qwen3:8b')
# 创建摘要生成链
chain = (
{"doc": lambda x: x.page_content}
| ChatPromptTemplate.from_template("总结下面的文档:\n\n{doc}")
| llm
| StrOutputParser()
)
# 批量生成文档摘要(最大并发数5)
summaries = chain.batch(docs, {"max_concurrency": 5})
# print(summaries)1.6 索引构建
- 我们引入了 InMemoryByteStore 和 Chroma 两个模块,分别用于存储原始文档和摘要文档。InMemoryByteStore 是一个内存中的存储层,用于存储原始文档;Chroma 是一个文档向量数据库,用于存储文档的向量表示。
# 初始化嵌入模型(用于文本向量化)
embeddings_model = OllamaEmbeddings(
model="embeddinggemma:latest",
base_url="http://localhost:11434"
)
# 初始化Chroma实例(用于存储摘要向量)
vectorstore = Chroma(
collection_name="summaries",
embedding_function=embeddings_model
)
# 初始化内存字节存储(用于存储原始文档)
store = InMemoryByteStore()1.7 检索关联
- 将摘要与文档关联以进行检索
# 初始化多向量检索器(结合向量存储和文档存储)
id_key = "doc_id"
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
byte_store=store,
id_key=id_key,
)
# 为每个文档生成唯一ID
doc_ids = [str(uuid.uuid4()) for _ in docs]
# 创建摘要文档列表(包含元数据) metadata可以用来关联原始文档和摘要文档会自动找到匹配关系
summary_docs = [
Document(page_content=s, metadata={id_key: doc_ids[i]}) for i, s in enumerate(summaries)
]
# 将摘要添加到向量数据库
retriever.vectorstore.add_documents(summary_docs)
# 将原始文档存储到字节存储(使用ID关联)
retriever.docstore.mset(list(zip(doc_ids, docs)))1.8 检索测试
# 执行相似性搜索测试
sub_docs = retriever.vectorstore.similarity_search("抢劫10万元,会受到什么处罚?")
print("-------------匹配的摘要内容--------------")
print(sub_docs[0])1.9 通过ID获取原始文档
# 获取第一个匹配摘要的ID
matched_id = sub_docs[0].metadata[id_key]
# 通过ID获取原始文档
original_doc = retriever.docstore.mget([matched_id])
print("-------------对应的原始文档--------------")
print(original_doc)1.10 模型问答
prompt = ChatPromptTemplate.from_template("根据下面的文档回答问题:\n\n{doc}\n\n问题: {question}")
# 生成问题回答链
chain = RunnableMap({
"doc": lambda x: retriever.get_relevant_documents(x["question"]),
"question": lambda x: x["question"]
}) | prompt | llm | StrOutputParser()
# 生成问题回答
query = "病假的请假流程?"
answer = chain.invoke({"question": query})
print("-------------回答--------------")
print(answer)调用 retriever 返回喂给模型的上下文
retrieved_docs = retriever.invoke(query)
print("-------------检索到的文档--------------")
print(retrieved_docs)2. 父子索引
2.1 痛点分析
我们在利用大模型进行文档检索的时候,常常会有相互矛盾的需求,比如:
- 你可能希望得到较小的文档块,以便它们Embedding以后能够最准确地反映出文档的含义,如果文档块太大,Embedding就失去了意义。
- 你可能希望得到较大的文档块以保留较多的内容,然后将它们发送给LLM以便得到全面且正确的答案。
2.2 解决思路:
父文档检索重点解决这种问题,基本思路:
- 文档被分割成一个层级化的块结构,随后用最小的叶子块进行索引
- 在检索过程中检索出top k个叶子块
- 如果存在n个叶子块都指向同一个更大的父块,那么我们就用这个父块来替换这些子块,并将其送入大模型用于生成答案。