什么是LangGraph?
LangGraph 是 LangChain 发布的一个多智能体框架。通过建立在LangChain 之上,LangGraph 使开发人员可以轻松创建强大的智能体。
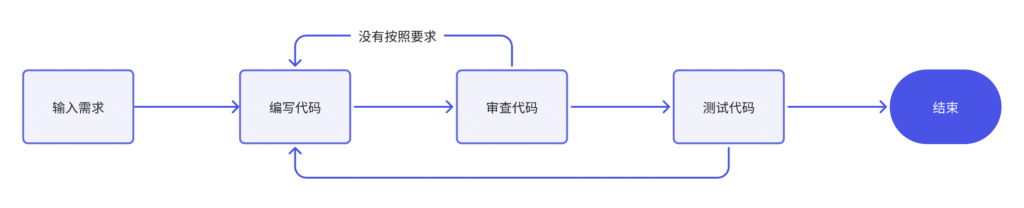
LangGraph 的核心功能
- 支持循环流: LangGraph 允许定义包含循环的流程,这对于大多数代理架构至关重要。这使得 LangGraph 更适合构建需要记忆和上下文推理的应用程序。
- 状态管理: LangGraph 提供了状态管理功能,允许代理在多个步骤之间存储和检索信息。这对于构建需要跟踪对话状态或游戏状态的应用程序至关重要。
- 多参与者支持: LangGraph 支持多个代理相互交互,以实现更复杂的工作流程。这使得 LangGraph 非常适合构建需要协作或竞争的代理应用程序。
- 可扩展性: LangGraph 可以扩展到生产环境,以支持大规模应用程序。
LangGraph和LangChain的区别
LangGraph和LangChain是两个相关但不同的工具,都来自LangChain生态系统。
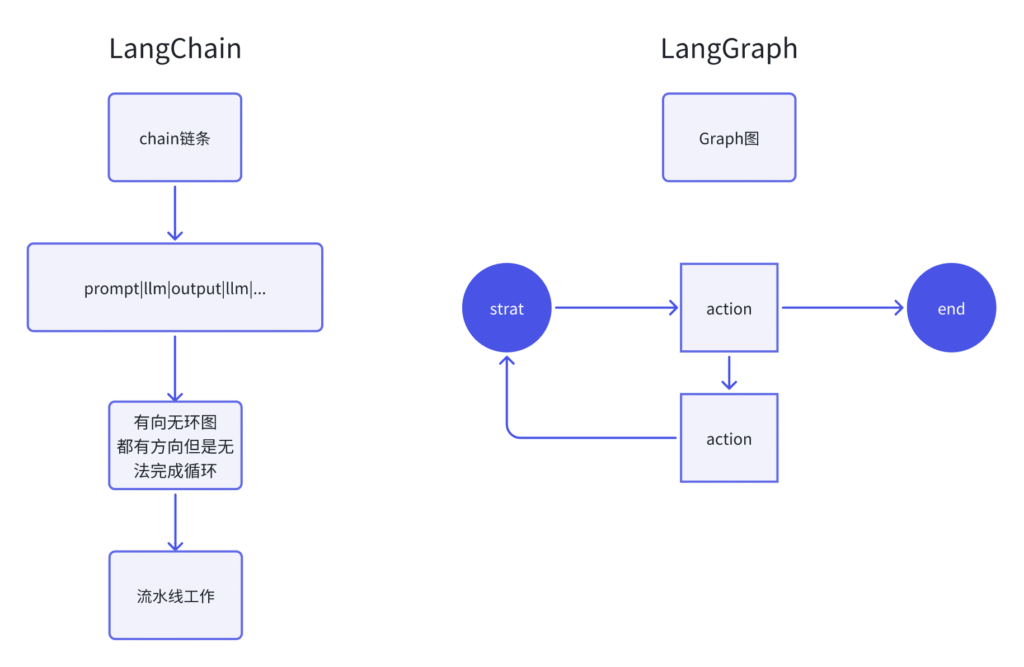
LangChain
LangChain是一个用于构建大语言模型应用程序的框架
- 线性工作流:主要支持顺序执行的链式操作
- 组件库:提供丰富的预构建组件,如提示模板、向量存储、检索器等
- 简单集成:易于快速原型开发和简单的LLM应用
- 抽象层:为不同的LLM提供统一接口
LangGraph
LangGraph是LangChain团队开发的更高级工具,专门用于构建复杂的多智能体系统:
- 图状工作流:支持复杂的分支、循环和条件逻辑
- 状态管理:内置强大的状态管理机制
- 多智能体协作:原生支持多个AI智能体之间的交互
- 复杂决策流:可以根据条件动态选择执行路径
- 持久化:支持长时间运行的工作流和状态持久化
主要区别
复杂性处理:
- LangChain适合简单到中等复杂度的应用
- LangGraph专为复杂的多步骤、多智能体场景设计
工作流结构:
- LangChain主要是链式(Chain)结构
- LangGraph是图状(Graph)结构,支持任意的节点连接
LangGraph安装和使用
pip install -U "langgraph>=0.6.1"简单Agent
from langgraph.prebuilt import create_react_agent
from langchain_ollama import ChatOllama
from langchain_tavily import TavilySearch
from langchain_core.tools import tool
from datetime import datetime
import os
llm = ChatOllama(
model="qwen3:4b",
temperature=0.5,
# other params...
)
# 定义工具函数
@tool
def search_web(query: str) -> str:
"""搜索网络信息的工具"""
t_search = TavilySearch(
max_results=5,
topic="general",
tavily_api_key = ""
)
return t_search.run(query)
@tool
def get_data_tool():
"""获取目前日期的工具"""
return datetime.now().date()
tools = [search_web, get_data_tool]
system_prompt = """你是一个智能助手。你有以下工具可以使用:
1. search_web: 用于搜索互联网获取最新信息,特别是产品价格、新闻、实时数据等
2. get_current_date: 获取今天的日期
3. get_current_time: 获取当前的日期和时间
重要规则:
- 当用户询问产品价格、最新信息、新闻等需要实时数据的问题时,必须使用search_web工具
- 当用户询问时间或日期时,使用相应的时间工具
- 如果你的知识库中没有准确或最新的信息,应该使用搜索工具
- 优先使用工具获取准确信息,而不是依赖可能过时的训练数据
请根据用户问题选择合适的工具来获取准确答案。"""
agent = create_react_agent(model=llm,
tools=tools,
prompt=system_prompt
)
response = agent.invoke({"messages": [{"role": "user", "content": "小米yu7价格"}]})
print(response["messages"][3].content)LangGraph基础知识(核心概念)
| 序号 | 核心概念 |
| ① State(状态) | 存储工作流中每个步骤的上下文信息(如问题、回答、变量等) |
| ② Node(节点) | 工作流中执行的一个步骤(如调用 LLM、调用工具、某个函数) |
| ③ Edge(边/跳转) | 控制流程走向的“路口”,决定从哪个节点跳到哪个节点(支持条件判断) |
| ④ Graph(流程图) | 将所有节点和边组织起来形成一张状态流程图,是 LangGraph 的执行主结构 |
Graph(流程图)
LangGraph 的核心是将代理工作流程建模为图表。您可以使用三个关键组件来定义代理的行为:
State:表示应用程序当前快照的共享数据结构。它可以是任何 Python 类型,但通常是TypedDict或 PydanticBaseModel。Nodes:用于编码代理逻辑的 Python 函数。它们接收当前值State作为输入,执行一些计算或副作用,并返回更新后的State。Edges:根据当前条件确定下一步执行哪个操作的 Python 函数State。它们可以是条件分支或固定转换。
通过组合Nodes和Edges,您可以创建复杂的循环工作流,使其State随时间推移而演化。然而,真正的强大之处在于 LangGraph 对 的管理方式State。需要强调的是:Nodes和Edges只不过是 Python 函数而已——它们可以包含 LLM 代码,也可以只是经典的 Python 代码。
简而言之:节点负责工作,边负责告诉下一步做什么。
状态图
StateGraph 类是主要使用的图形类。这是由用户定义的 State 对象参数化的。
通俗来说,它是一张流程图 + 状态管理系统,定义了:
- 哪些步骤(节点)要执行?
- 每一步之间怎么跳转(边)?
- 整个流程中数据状态如何流动和更新(状态)?
为什么叫“状态图”而不是“流程图”?
LangGraph 不只是流程控制,还强调:
- 每个节点执行前、执行后都可以访问和修改状态(state)
- 状态是图的“血液”,在节点之间流动
- 节点的跳转可以依据状态来判断(如条件跳转)
所以叫做 State Graph(有状态的流程图),而不是“静态流程图”。
from typing import TypedDict
from langgraph.graph import StateGraph
# 定义状态结构
class MyState(TypedDict):
question: str
answer: str
# 定义节点函数
def search_node(state):
return {"answer": "这是答案"}
# 创建状态图
builder = StateGraph(state_schema=MyState)
# 添加一个节点
builder.add_node("search", search_node)
# 第一个要调用的节点
builder.set_entry_point("search")
# 要构建图,首先要定义状态,然后添加节点和边,最后进行编译,会进行基本的检查
graph = builder.compile()
# 执行图
result = graph.invoke({"question": "什么是状态图?"})
print(result)
print(result["answer"]) # 输出:这是答案State(状态)
在使用 LangGraph 构建流程图之前,第一件事就是定义图的状态 State。这是整个图运行中用于共享和传递信息的核心机制。
什么是 State?
LangGraph 中的 State 是图中所有节点(Node)之间传递数据的模式结构,可以类比为一个共享的上下文字典,它包含输入、输出、中间变量等。
定义 State 时,需要包含两个部分:
- Schema(模式):指定 State 的字段结构(可以用
TypedDict或Pydantic)
# langgraph推荐使用TypedDict
"""
1. TypedDict 是标准库的一部分(来自 typing 模块),零依赖,零性能开销而 Pydantic 会在每一步创建模型实例,会增加运行时负担
2. LangGraph 中的 State 实质就是一个字典(dict),而 TypedDict 就是“有类型注解的 dict”,与 LangGraph 的执行机制无缝对接,而 Pydantic 是类结构,需要 .dict() 转换,略显多余
"""
from typing import TypedDict
class State1(TypedDict):
user_input: str
# 使用 pydantic 可以进行参数校验和提供默认值
from pydantic import BaseModel
class State2(BaseModel):
question: str
result: str = ""- 多个模式(Multiple Schemas):在大多数情况下,LangGraph 使用一个统一的 State 模式。但你也可以设置“输入模式”和“输出模式”分开
- 输入模式:接收用户输入的字段(如
question) - 输出模式:只保留最终输出的字段(如
final_answer)
- 输入模式:接收用户输入的字段(如
from typing import TypedDict
from langgraph.graph import StateGraph
# 1. 定义输入、输出、图内部的状态结构
# 输入字段:用户的问题
class InputState(TypedDict):
question: str
# 中间状态:包括中间结果
class InternalState(TypedDict):
question: str
search_result: str
final_answer: str
# 输出字段:只想返回最终答案
class OutputState(TypedDict):
final_answer: str
# 2. 定义节点函数(中间节点用中间字段)
def search_node(state: InternalState) -> dict:
return {"search_result": f"搜索了:{state['question']}"}
def answer_node(state: InternalState) -> dict:
return {"final_answer": f"根据搜索结果:{state['search_result']},这是答案"}
# 3. 创建 StateGraph,显式指定输入/输出 Schema
builder = StateGraph(state_schema=InternalState,
input_schema=InputState,
output_schema=OutputState)
# 4. 添加节点
builder.add_node("search", search_node)
builder.add_node("answer", answer_node)
# 5. 配置流程
builder.set_entry_point("search")
builder.add_edge("search", "answer")
# 6. 编译并执行图
app = builder.compile()
result = app.invoke({"question": "什么是LangGraph?"})
print(result) # {'final_answer': '根据搜索结果:搜索了:什么是LangGraph?,这是答案'}Reducer(归并函数):在 LangGraph 中,所有节点返回的都是“局部更新结果”,Reducer 是用于合并多个节点输出更新的机制。 将每个节点返回的“局部状态更新”统一合并进全局的 State。
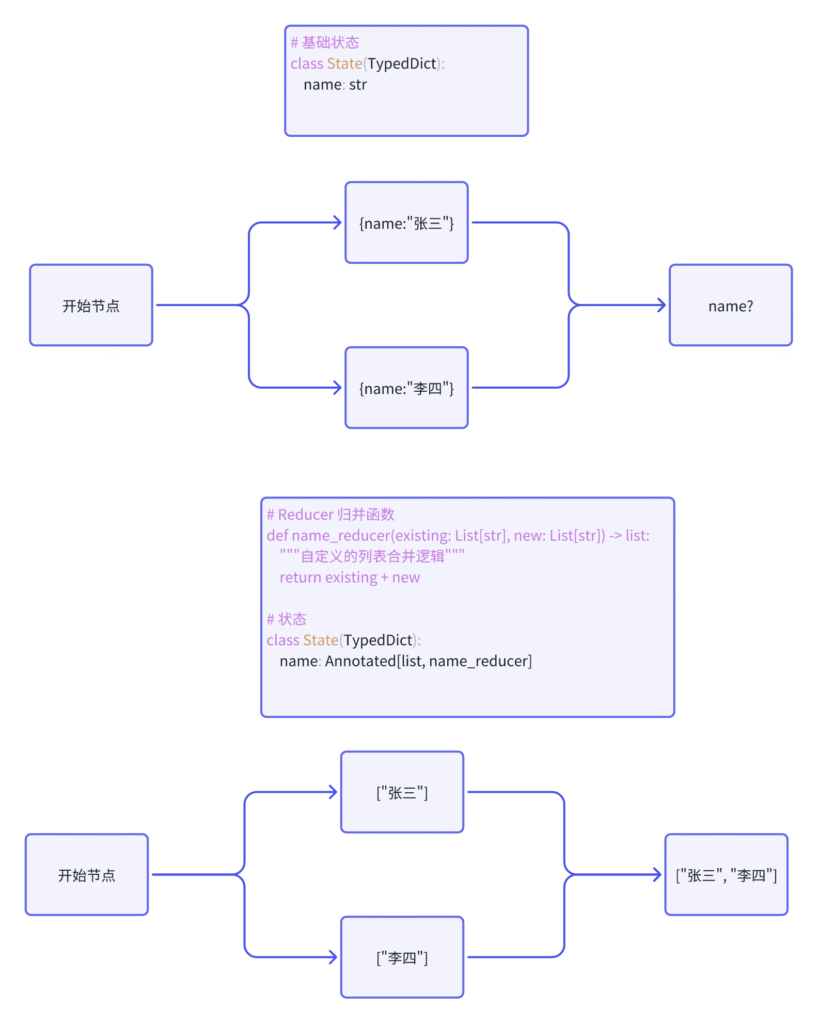
from typing import Annotated
from typing_extensions import TypedDict
from operator import add
class State(TypedDict):
foo: int
bar: Annotated[list[str], add] # 每条消息是 {role, content},会自动追加到列表末尾使用图形状态中的消息
为什么要使用消息?
大多数现代 LLM 提供商都提供聊天模型接口,接受消息列表作为输入。LangChainChatModel尤其接受对象列表Message作为输入。这些消息有多种形式,例如HumanMessage(用户输入)或AIMessage(LLM 响应)。
在图表中使用消息
在许多情况下,将之前的对话历史记录以消息列表的形式存储在图状态中会很有帮助。为此,我们可以向图状态添加一个键(通道),该键存储Message对象列表,并使用 Reducer 函数对其进行注释。Reducer 函数对于指示图如何Message在每次状态更新(例如,当节点发送更新时)时更新状态中的对象列表至关重要。如果您未指定 Reducer,则每次状态更新都会用最新提供的值覆盖消息列表。如果您只想将消息附加到现有列表中,可以使用operator.add。
operator 是 Python 的一个内置模块,把常见的运算符(如 +、-、==、getitem 等)变成了函数,方便函数式编程和高阶函数使用。from typing import TypedDict
from langgraph.graph import StateGraph
from typing import Annotated
import operator
# 定义状态结构 如果定义的是list[dict],会覆盖之前的数据
class ChatState(TypedDict):
messages: Annotated[list, operator.add] # 每条消息是 {role, content},会自动追加到列表末尾
# 节点函数:添加用户问题
def user_input_node(state: ChatState) -> dict:
user_msg = {"role": "user", "content": "什么是LangGraph?"}
return {"messages": [user_msg]}
# 节点函数:添加助手回复
def assistant_node(state: ChatState) -> dict:
reply = {"role": "assistant", "content": "LangGraph 是一个有状态的图编排框架。"}
return {"messages": [reply]}
# 构建状态图
builder = StateGraph(state_schema=ChatState)
builder.add_node("user_input", user_input_node)
builder.add_node("assistant_reply", assistant_node)
builder.set_entry_point("user_input")
builder.add_edge("user_input", "assistant_reply")
graph = builder.compile()
result = graph.invoke({"messages": []})
print(result["messages"])有场景可能还需要手动更新图状态中的消息(例如,人机交互)。 如果您使用 operator.add,您发送到图的手动状态更新将被附加到现有消息列表中,而不是更新现有消息。 为了避免这种情况,您需要一个能够跟踪消息 ID 并在更新时覆盖现有消息的 Reducer。 为此,您可以使用预构建 add_messages 函数。 对于新消息,它只会附加到现有列表中,但它也会正确处理现有消息的更新。
from langchain_core.messages import AnyMessage
from langgraph.graph.message import add_messages
from typing import Annotated
from typing_extensions import TypedDict
class GraphState(TypedDict):
messages: Annotated[list[AnyMessage], add_messages]MessagesState
由于在状态中包含消息列表非常常见,因此存在一个名为MessagesState的预建状态,它使使用消息变得非常简单。该状态MessagesState使用单个键定义messages,该键是对象列表AnyMessage并使用add_messages。通常,需要跟踪的状态不仅仅是消息,因此我们看到人们将这个状态子类化并添加更多字段,例如:
Node(节点)
节点(Nodes)是图中执行逻辑的基本单位。每个节点表示一个函数步骤、处理阶段或子逻辑流程,多个节点通过边连接成有向图,组成一个完整的有状态计算流程。
LangGraph 中的节点就是你定义的一个函数(或 Runnable 对象),用于接收状态、执行逻辑,并返回更新后的状态
def my_node(state: dict) -> dict:
# 处理输入状态,并返回更新字段
return {"new_key": "new_value"}
# LangGraph 会自动用 reducer 把这些更新合并进全局状态。START节点
NodeSTART是一个特殊节点,表示将用户输入发送到图的节点。引用此节点的主要目的是确定应首先调用哪些节点。
(API 参考:START)
from langgraph.graph import START
graph.add_edge(START, "node_a")END节点
NodeEND是一个特殊节点,表示终端节点。当需要指示哪些边在完成后没有操作时,可以引用此节点。
from langgraph.graph import END
graph.add_edge("node_a", END)并行运行节点
import operator
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
class State(TypedDict):
# The operator.add reducer fn makes this append-only
aggregate: Annotated[list, operator.add]
def a(state: State):
print(f'Adding "A" to {state["aggregate"]}')
return {"aggregate": ["A"]}
def b(state: State):
print(f'Adding "B" to {state["aggregate"]}')
return {"aggregate": ["B"]}
def c(state: State):
print(f'Adding "C" to {state["aggregate"]}')
return {"aggregate": ["C"]}
def d(state: State):
print(f'Adding "D" to {state["aggregate"]}')
return {"aggregate": ["D"]}
builder = StateGraph(State)
builder.add_node(a)
builder.add_node(b)
builder.add_node(c)
builder.add_node(d)
builder.add_edge(START, "a")
builder.add_edge("a", "b")
builder.add_edge("a", "c")
builder.add_edge("b", "d")
builder.add_edge("c", "d")
builder.add_edge("d", END)
graph = builder.compile()
print(graph.invoke({"aggregate": ["start"]}))Edge(边/跳转)
Edge(边) 是连接节点的通道,表示图中节点之间的执行跳转关系。你可以把它理解为「节点执行完之后,下一步去哪,是构成 LangGraph 流程图的核心。
Edge 是 LangGraph 中连接两个节点的“执行路径”,控制流程的走向。
- 普通边:直接从一个节点到下一个节点。
graph.add_edge("节点A", "节点B")条件边:调用一个函数来确定下一步要去哪个节点。
from typing import TypedDict
from langgraph.graph import StateGraph, END
class MyState(TypedDict):
type: str
result: str
def judge_node(state: MyState):
"""节点函数:可以做一些预处理"""
return state # 保持状态不变,只是路由
def route_condition(state: MyState):
"""条件函数:只负责路由决策"""
if state["type"] == "a":
return "a"
elif state["type"] == "b":
return "b"
else:
return "default"
def node_a(state):
return {"result": "走了 A 分支"}
def node_b(state):
return {"result": "走了 B 分支"}
def node_default(state):
return {"result": "走了默认分支"}
# 构建图
graph = StateGraph(state_schema=MyState)
# 定义节点
graph.add_node("judge_node", judge_node)
graph.add_node("a1", node_a)
graph.add_node("b1", node_b)
graph.add_node("default1", node_default)
# 定义开始节点
graph.set_entry_point("judge_node")
# 使用不同的函数作为条件函数
graph.add_conditional_edges("judge_node", route_condition, {
"a": "a1",
"b": "b1",
"default": "default1"
})
# 添加结束边
graph.add_edge("a1", END)
graph.add_edge("b1", END)
graph.add_edge("default1", END)
app = graph.compile()
# 测试
print("测试 A:", app.invoke({"type": "b", "result": ""}))入口点:当图开始运行时首先运行的第一个(些)节点。
from langgraph.graph import START
graph.add_edge(START, "node_a")条件入口点:调用一个函数来确定当用户输入到达时首先调用哪个节点。
from typing import TypedDict
from langgraph.graph import StateGraph, END
class MyState(TypedDict):
user_type: str # "vip", "normal", "guest"
message: str
result: str
# 定义不同的处理节点
def vip_service(state):
"""VIP 用户服务"""
return {"result": f"VIP专享服务: {state['message']}"}
def normal_service(state):
"""普通用户服务"""
return {"result": f"标准服务: {state['message']}"}
def guest_service(state):
"""游客服务"""
return {"result": f"游客服务(功能受限): {state['message']}"}
# 条件入口点函数
def route_by_user_type(state):
"""根据用户类型路由到不同的服务"""
user_type = state["user_type"]
if user_type == "vip":
return "vip_service"
elif user_type == "normal":
return "normal_service"
else:
return "guest_service"
# 构建图
workflow = StateGraph(state_schema=MyState)
# 添加节点
workflow.add_node("vip_service", vip_service)
workflow.add_node("normal_service", normal_service)
workflow.add_node("guest_service", guest_service)
# 设置条件入口点 - 关键部分!
workflow.set_conditional_entry_point(
route_by_user_type, # 条件函数
{
"vip_service": "vip_service",
"normal_service": "normal_service",
"guest_service": "guest_service"
}
)
# 添加结束边
workflow.add_edge("vip_service", END)
workflow.add_edge("normal_service", END)
workflow.add_edge("guest_service", END)
# 编译图
app = workflow.compile()
# 测试 VIP 用户
result1 = app.invoke({
"user_type": "vip",
"message": "我要退款",
"result": ""
})
print("VIP用户:", result1)Send发送
默认情况下,Nodes和Edges是提前定义的,并在相同的共享状态下运行。但是,在某些情况下,确切的边无法提前知道,并且可能希望同时存在State的不同版本。
send("节点名", 更新数据) 的作用是:告诉 LangGraph 把这部分更新数据发送给指定节点,让它继续执行。
主要用途
- 条件路由:根据某些条件将消息发送到不同的节点
- 并行处理:同时向多个节点发送消息
- 动态工作流:根据运行时状态决定消息的发送目标
from langgraph.graph import StateGraph, END
from langgraph.types import Send
from typing import TypedDict
class MyState(TypedDict):
messages: list
result: str
def process_input(state: MyState) -> Send:
"""处理输入并决定发送到哪个节点"""
if len(state["messages"]) > 5:
return Send("complex_processor", state)
else:
return Send("simple_processor", state)
def simple_processor(state: MyState) -> MyState:
"""简单处理器"""
return {"messages": state["messages"], "result": "simple"}
def complex_processor(state: MyState) -> MyState:
"""复杂处理器"""
return {"messages": state["messages"], "result": "complex"}
# 构建图
graph = StateGraph(state_schema=MyState)
graph.add_node("input", process_input)
graph.add_node("simple_processor", simple_processor)
graph.add_node("complex_processor", complex_processor)
graph.set_entry_point("input")
graph.add_edge("simple_processor", END)
graph.add_edge("complex_processor", END)
app = graph.compile()
massages = []
for i in range(6):
massages.append(i)
print(app.invoke({"messages": massages}))和add_conditional_edges有什么区别呢?
add_conditional_edges:外部决策。路由逻辑在一个单独的函数中,它在节点运行之后被调用,根据图的当前状态来决定下一步去哪里。Send:内部决策。路由逻辑在节点自身的函数体内,节点在运行时直接、显式地决定将其结果发送到哪个特定的节点
两者通常在需要并发处理的时候配合使用
Map-Reduce模式
Map-Reduce 是一种经典的并行计算模式,特别适合处理大规模数据。
Map-Reduce 将复杂的数据处理任务分解为两个阶段:
- Map阶段:将大任务分解为多个小任务,并行处理
- Reduce阶段:将所有小任务的结果合并成最终结果
"""
LangGraph Map-Reduce 简单案例:数字求和
把一堆数字分给多个worker算平方,然后把结果加起来
"""
from typing import Annotated
import operator
from langgraph.graph import StateGraph, START, END
from langgraph.types import Send
from typing import TypedDict, List
# 状态定义
class State(TypedDict):
numbers: List[int] # 输入的数字
results: Annotated[list[int], operator.add] # worker的结果
final_sum: int # 最终求和
# 1. Map阶段:分发数字
def split_numbers(state: State):
"""把数字分发给不同的worker"""
numbers = state["numbers"]
print(f"📦 分发数字: {numbers}")
# 每个数字发给一个worker
return [Send("worker", {"number": num}) for num in numbers]
# 2. Worker阶段:计算平方
def calculate_square(state: State):
"""每个worker计算一个数字的平方"""
number = state["number"]
square = number * number
print(f"⚡ Worker: {number}² = {square}")
return {"results": [square]}
# 3. Reduce阶段:求和
def sum_results(state: State):
"""把所有结果加起来"""
results = state.get("results", [])
total = sum(results)
print(f"📊 求和: {results} = {total}")
return {"final_sum": total}
# 构建图
def create_simple_graph():
graph = StateGraph(State)
# 添加节点
graph.add_node("splitter", lambda s: s) # 分发器
graph.add_node("worker", calculate_square) # 工作节点
graph.add_node("summer", sum_results) # 求和器
# 连接节点
graph.add_edge(START, "splitter")
graph.add_conditional_edges("splitter", split_numbers, ["worker"]) # Map阶段
graph.add_edge("worker", "summer") # Worker完成后求和
graph.add_edge("summer", END)
return graph.compile()
# 运行例子
def run_example():
app = create_simple_graph()
# 测试数据
initial_state = {
"numbers": [1, 2, 3, 4, 5],
"results": [],
"final_sum": 0
}
print("🚀 开始计算...")
print("任务:计算每个数字的平方,然后求和")
print()
# 运行
result = app.invoke(initial_state)
print(result)
run_example()Command命令
将控制流(边)和状态更新(节点)结合在一起可能非常有用。例如,您可能希望在同一个节点中既执行状态更新,又决定接下来要去哪个节点。
在节点函数中返回时Command,必须添加返回类型注释,其中包含节点路由到的节点名称列表,例如Command[Literal["my_other_node"]]。这对于图形渲染是必需的,它告诉 LangGraphmy_node可以导航到my_other_node。
from typing import TypedDict
from langgraph.graph import StateGraph, END
from langgraph.types import Command, Literal, Send
class MyState(TypedDict):
type: str
text: str
result: str
def judge_node(state: MyState) -> Command[Literal["a", "b", "default"]]:
"""条件函数:使用Command进行路由和状态更新"""
if state["type"] == "a":
return Command(update={"text": "走了 A 分支"}, goto="a")
elif state["type"] == "b":
# Command只是更新当前节点结束的状态
# return Command(update={"text": "走了 B 分支"}, goto="b")
return Send("b", state)
else:
return Command(update={"text": "走了默认分支"}, goto="default")
def node_a(state):
return {"result": f"A节点处理: {state['text']}"}
def node_b(state):
return {"result": f"B节点处理: {state['text']}"}
def node_default(state):
return {"result": f"默认节点处理: {state['text']}"}
# 构建图
graph = StateGraph(state_schema=MyState)
graph.add_node("judge_node", judge_node)
graph.add_node("a", node_a)
graph.add_node("b", node_b)
graph.add_node("default", node_default)
graph.set_entry_point("judge_node")
# 添加结束边
graph.add_edge("a", END)
graph.add_edge("b", END)
graph.add_edge("default", END)
app = graph.compile()
# 测试
print("测试 A:", app.invoke({"type": "a", "text": "", "result": ""}))
print("测试 B:", app.invoke({"type": "b", "text": "", "result": ""}))
print("测试其他:", app.invoke({"type": "default", "text": "", "result": ""}))什么时候应该使用命令而不是条件边?
Command当需要同时更新图形状态和路由到其他节点时使用。例如,在实现多代理切换时,需要路由到其他代理并向该代理传递一些信息。在进行command更新状态的时候,更新的属性必须符合初始化状态的内容使用条件边在节点之间有条件地路由而不更新状态。
配置Runtime
创建图时,还可以标记图的某些部分是可配置的。这样做通常是为了方便在模型或系统提示之间切换。这允许创建单个“认知架构”(图),但拥有多个不同的实例。
在运行图时提供额外的“配置参数”而不是“状态参数”,并且通过类型约束这些参数。
from langgraph.graph import StateGraph
from langgraph.runtime import Runtime
from langchain_community.chat_models import ChatZhipuAI
from typing import TypedDict
# 定义状态结构
class MyState(TypedDict):
question: str
answer: str
# 定义配置结构
class MyContext(TypedDict):
language: str # 配置中包含语言选项,比如 "en" 或 "zh"
# 节点函数可以访问 runtime 参数 runtime 可以访问上下文和内存存储
def step1(state: MyState, runtime: Runtime[MyContext]):
if runtime.context["language"] == "zh":
answer = "你好!"
else:
answer = "Hello!"
return {"answer": answer}
# 构建图
graph = StateGraph(state_schema=MyState, context_schema=MyContext)
graph.add_node("step1", step1)
graph.set_entry_point("step1")
# 编译
app = graph.compile()
# 执行时传入 config 参数(区分于 state)
result = app.invoke({"question": "Hi"}, context={"language": "zh"})
print(result) # => {"question": "Hi", "answer": "你好!"}在运行时指定llm
from langgraph.graph import MessagesState
from langgraph.runtime import Runtime
from langgraph.graph import END, StateGraph, START
from typing_extensions import TypedDict
class MyContext(TypedDict):
model: str
MODELS = {
"anthropic": "anthropic:claude-3-5-haiku-latest",
"openai": "openai:gpt-4.1-mini",
}
def call_model(state: MessagesState, runtime: Runtime[MyContext]):
model = ""
if runtime.context:
model = runtime.context["model"]
model = MODELS[model]
return {"messages": {"role": "assistant", "content": model}}
builder = StateGraph(MessagesState, context_schema=MyContext)
builder.add_node("model", call_model)
builder.add_edge(START, "model")
builder.add_edge("model", END)
graph = builder.compile()
# Usage
input_message = {"role": "user", "content": "hi"}
# With no configuration, uses default (Anthropic)
response_1 = graph.invoke({"messages": [input_message]})
# Or, can set OpenAI
context = {"model": "openai"}
response_2 = graph.invoke({"messages": [input_message]}, context=context)
print(response_1)
print(response_2)递归限制
递归限制设置图在单次执行中可以执行的最大超步数。一旦达到限制,LangGraph 将出现GraphRecursionError。默认情况下,此值设置为 25 步。可以在运行时在任何图上设置递归限制,并将其传递给.invoke/.stream通过配置字典。重要的是,recursion_limit是一个独立的config键,不应configurable像所有其他用户定义的配置一样在键内传递。
graph.invoke(inputs, config={"recursion_limit": 5, "configurable":{"llm": "anthropic"}})可视化图表
"""
LangGraph Map-Reduce 简单案例:数字求和
把一堆数字分给多个worker算平方,然后把结果加起来
"""
from typing import Annotated
import operator
from langgraph.graph import StateGraph, START, END
from langgraph.types import Send
from typing import TypedDict, List
# 状态定义
class State(TypedDict):
numbers: List[int] # 输入的数字
results: Annotated[list[int], operator.add] # worker的结果
final_sum: int # 最终求和
# 1. Map阶段:分发数字
def split_numbers(state: State):
"""把数字分发给不同的worker"""
numbers = state["numbers"]
print(f"📦 分发数字: {numbers}")
# 每个数字发给一个worker
return [Send("worker", {"number": num}) for num in numbers]
# 2. Worker阶段:计算平方
def calculate_square(state: State):
"""每个worker计算一个数字的平方"""
number = state["number"]
square = number * number
print(f"⚡ Worker: {number}² = {square}")
return {"results": [square]}
# 3. Reduce阶段:求和
def sum_results(state: State):
"""把所有结果加起来"""
results = state.get("results", [])
total = sum(results)
print(f"📊 求和: {results} = {total}")
return {"final_sum": total}
# 构建图
def create_simple_graph():
graph = StateGraph(State)
# 添加节点
graph.add_node("splitter", lambda s: s) # 分发器
graph.add_node("worker", calculate_square) # 工作节点
graph.add_node("summer", sum_results) # 求和器
# 连接节点
graph.add_edge(START, "splitter")
graph.add_conditional_edges("splitter", split_numbers, ["worker"]) # Map阶段
graph.add_edge("worker", "summer") # Worker完成后求和
graph.add_edge("summer", END)
return graph.compile()
# 运行例子
def run_example():
app = create_simple_graph()
# 测试数据
initial_state = {
"numbers": [1, 2, 3, 4, 5],
"results": [],
"final_sum": 0
}
print("🚀 开始计算...")
print("任务:计算每个数字的平方,然后求和")
print()
# 运行
app.invoke(initial_state)
from IPython.display import Image, display
from langchain_core.runnables.graph import MermaidDrawMethod
display(
Image(
app.get_graph().draw_mermaid_png(
draw_method=MermaidDrawMethod.API,
output_file_path='./可视化图.png'
)
)
)
run_example()子图
LangGraph子图(Subgraph)是一种模块化的图结构,允许您将复杂的工作流分解为更小的、可重用的组件。就像函数在编程中的作用一样,子图提供了封装和复用的能力。
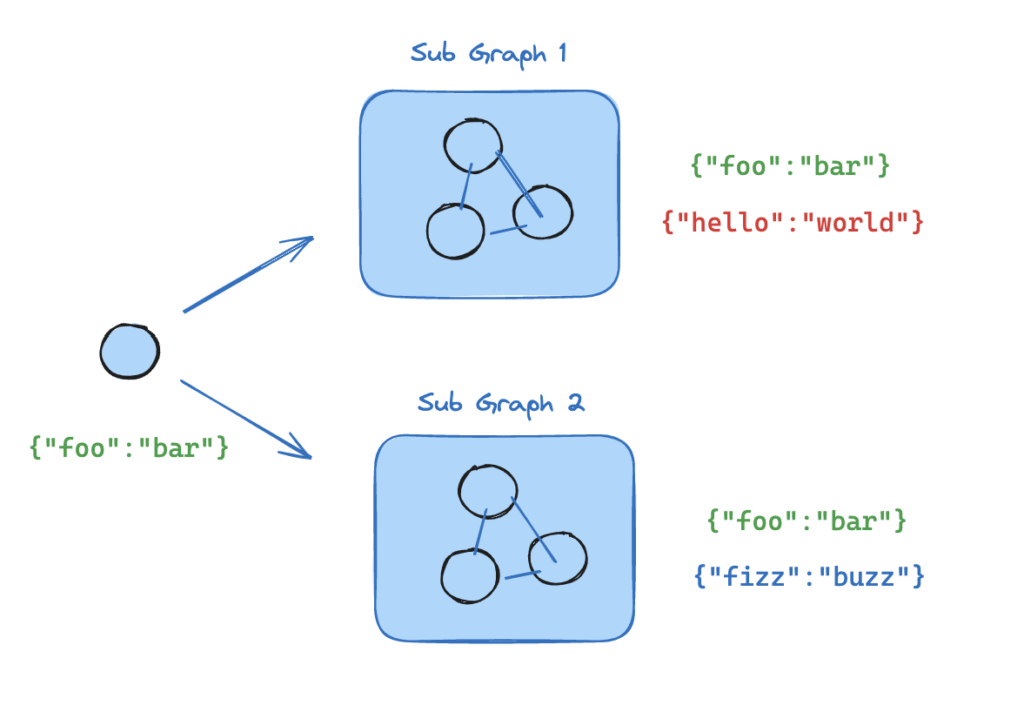
子图的优势
- 代码复用:避免重复编写相同的逻辑
- 清晰的架构:将复杂流程分解为清晰的模块
- 易于维护:修改子图只需在一个地方进行
- 团队协作:不同团队可以独立开发不同的子图
- 测试友好:可以单独测试子图的功能
两种状态通讯
1.共享状态键(Shared State Keys)
父图和子图在其状态模式中有共享的状态键。在这种情况下,您可以将子图作为节点包含在父图中。
from langgraph.graph import StateGraph, MessagesState, START
from langchain_ollama import ChatOllama
import os
from dotenv import load_dotenv
load_dotenv()
llm = ChatOllama(
model="qwen3:4b",
temperature=0.5,
# other params...
)
# 创建子图
def subplot(state: MessagesState) -> MessagesState:
# 获取大模型回答的内容进行摘要总结
answer = state["messages"][-1].content
summary_prompt = f"请用一句话总结下面这句话:\n\n答:{answer}"
response = llm.invoke(summary_prompt)
return {"messages": state["messages"] + [response]}
summary_subgraph = (
StateGraph(state_schema=MessagesState)
.add_node("subplot", subplot)
.add_edge(START, "subplot")
.compile()
)
# 创建父图
def llm_answer_node(state: MessagesState) -> MessagesState:
# 使用大模型进行回答
answer = llm.invoke(state["messages"])
print("父图输出", answer)
return {"messages": state["messages"] + [answer]}
parent_graph = (
StateGraph(MessagesState)
.add_node("llm_answer", llm_answer_node)
.add_node("summarize_subgraph", summary_subgraph)
.add_edge(START, "llm_answer")
.add_edge("llm_answer", "summarize_subgraph")
.compile()
)
# 测试
input_state = {
"messages": [{"role": "user", "content": "langgraph是什么?"}],
}
result = parent_graph.invoke(input_state)
print(result)2.不同状态模式(Different State Schemas)常用
父图和子图有不同的模式(状态模式中没有共享的状态键)。在这种情况下,您必须在父图的节点内部调用子图:这在父图和子图有不同状态模式且需要在调用子图前后转换状态时很有用。