06-RAG项目实战
实战项目:智能文档检索助手
学习目标:
- 熟悉 项目搭建思路
- 熟悉
streamlit的使用 - 熟悉 项目搭建过程
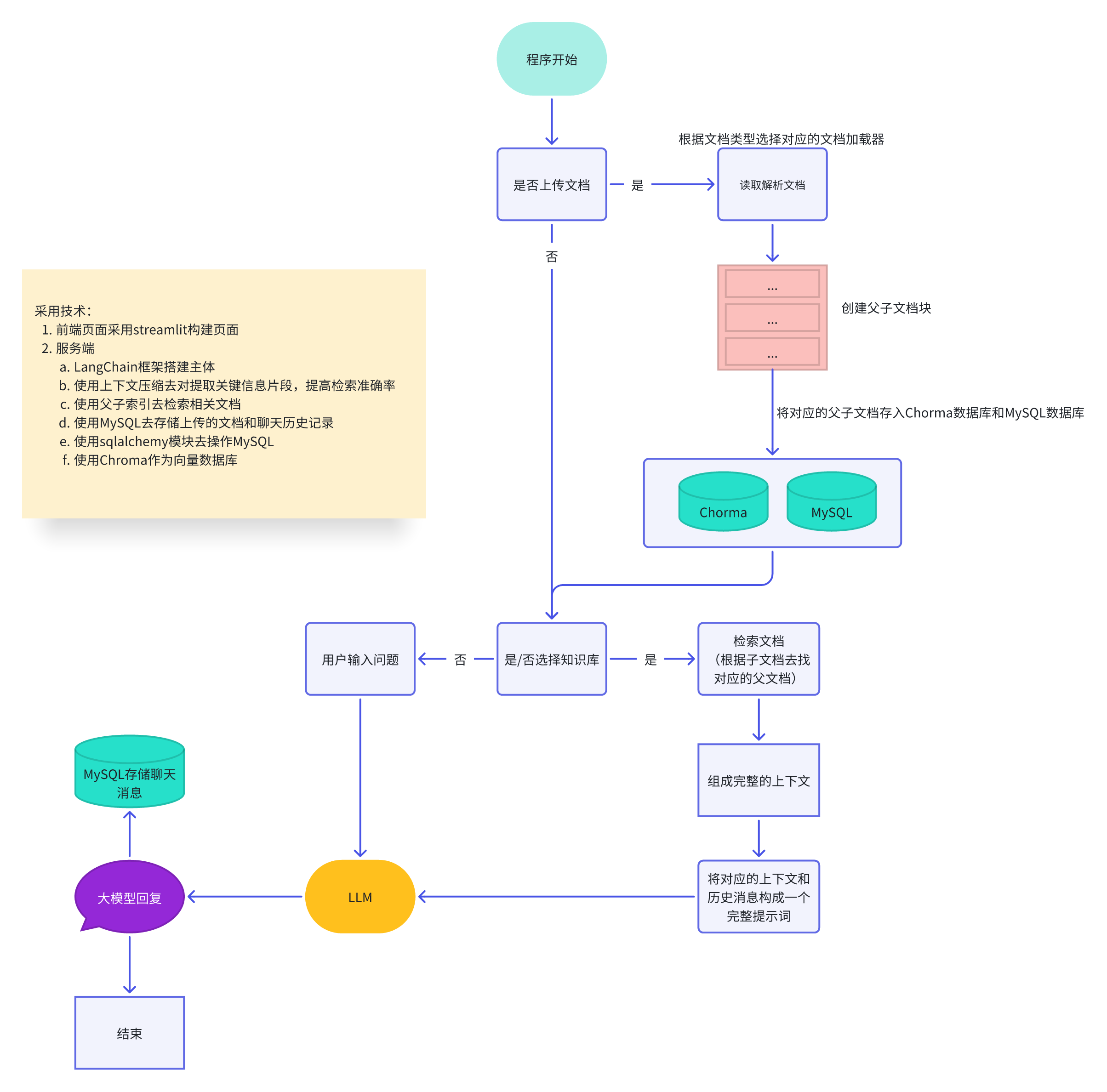
一. 项目思路解析
1. 开发流程
- 需求定义与分析
- 明确客户需求
- 技术评估
- 架构设计
- UI设计
- 设计规范
- 切图资源包
- 前端技术实现
- 后端技术实现
- 测试验证
- 部署上线
- 持续迭代
2. 前端
前端页面一般都不需要我们考虑,会有公司专门的前端工程师来进行完成(我们通过Streamlit来做页面)
3. 后端
二. streamlit的使用
1. 简介
Streamlit 是一个开源的 Python 框架,允许开发者快速构建和部署数据科学和机器学习应用。不同于传统的 Web 开发,Streamlit 只需几行代码就能创建交互式数据应用。
官方文档: https://docs.streamlit.io/get-started/installation
核心特点:
- 🚀 极简开发:纯 Python 脚本即可创建 Web 应用
- ⚡ 实时更新:文件保存自动刷新应用
- 🧩 内置组件:丰富的小部件、布局和图表类型
- ☁️ 轻松部署:支持一键部署
安装命令:
# 安装Streamlit
pip install streamlit
2. 组件使用方法
2.1 运行代码
# 创建第一个应用(app.py)
import streamlit as st
st.title("我的第一个Streamlit应用")
st.write("你好,世界!")
# 在终端运行
streamlit run app.py
streamlit hello
2.2 文本组件
st.title("主标题") # 主标题
st.header("章节标题") # 大标题
st.subheader("子标题") # 子标题
st.text("普通文本") # 普通文本
st.write("万能文本/变量") # 显示任何对象
st.markdown("**Markdown**支持") # Markdown语法
2.3 数据展示组件
st.dataframe(pd.DataFrame()) # 交互式表格
st.table([1,2,3]) # 静态表格
st.json({"key": "value"}) # 显示JSON格式
2.4 输入控件
text = st.text_input("输入文本") # 文本输入
number = st.number_input("输入数字") # 数字输入
date = st.date_input("选择日期") # 日期选择
time = st.time_input("选择时间") # 时间选择
is_checked = st.checkbox("复选框") # 复选框
selected = st.radio("单选按钮", ['1', '2', '3', '4']) # 单选按钮
multi = st.multiselect("多选", ['1', '2', '3', '4']) # 多选下拉
slider = st.slider("滑块", 0, 100) # 滑块
st.button("确认") # 按钮
st.file_uploader("上传文件") # 文件上传
3. 布局使用
3.1 侧边栏
# 所有输入组件添加sidebar前缀即可放入侧边栏
st.sidebar.selectbox("选项", ['1', '2', '3', '4'])
3.2 分列布局
col1, col2 = st.columns(2) # 创建两列
with col1:
st.write("第一列内容")
with col2:
st.write("第二列内容")
3.3 标签页
tab1, tab2 = st.tabs(["主页", "分析"])
with tab1:
st.write("主页内容")
with tab2:
st.write("分析内容")
3.4 容器
container = st.container()
container.write("容器内的内容")
4. 项目页面
import streamlit as st
# 页面配置
st.set_page_config(
page_title="智能文档检索助手",
page_icon="🤖",
layout="wide",
initial_sidebar_state="collapsed"
)
# 自定义CSS样式
st.markdown("""
<style>
/* 聊天容器 */
.chat-container {
background: white;
border-radius: 12px;
box-shadow: 0 8px 32px rgba(0,0,0,0.1);
margin: 20px auto;
max-width: 800px;
display: flex;
flex-direction: column;
overflow: hidden;
}
/* 头部样式 */
.chat-header {
background: linear-gradient(90deg, #667eea 0%, #764ba2 100%);
color: white;
padding: 20px;
text-align: center;
border-radius: 12px 12px 0 0;
}
.chat-title {
font-size: 24px;
font-weight: 600;
margin: 0;
display: flex;
align-items: center;
justify-content: center;
gap: 10px;
}
.chat-subtitle {
font-size: 14px;
opacity: 0.9;
margin-top: 5px;
}
/* 聊天消息区域 */
.chat-messages {
flex: 1;
overflow-y: auto;
padding: 20px;
background: #f8f9fa;
}
/* 消息样式 */
.message {
margin-bottom: 16px;
display: flex;
align-items: flex-start;
gap: 12px;
}
.message.user {
flex-direction: row-reverse;
}
.message-avatar {
width: 36px;
height: 36px;
border-radius: 50%;
display: flex;
align-items: center;
justify-content: center;
font-size: 18px;
flex-shrink: 0;
}
.user-avatar {
background: linear-gradient(135deg, #667eea 0%, #764ba2 100%);
color: white;
}
.assistant-avatar {
background: linear-gradient(135deg, #84fab0 0%, #8fd3f4 100%);
color: white;
}
.message-content {
max-width: 70%;
padding: 12px 16px;
border-radius: 18px;
font-size: 14px;
line-height: 1.4;
}
.user-message {
background: linear-gradient(135deg, #667eea 0%, #764ba2 100%);
color: white;
border-bottom-right-radius: 4px;
}
.assistant-message {
background: white;
color: #333;
border: 1px solid #e1e5e9;
border-bottom-left-radius: 4px;
box-shadow: 0 1px 2px rgba(0,0,0,0.1);
}
/* 流式输出动画 */
.streaming-cursor::after {
content: '▊';
animation: blink 1s infinite;
color: #667eea;
}
@keyframes blink {
0%, 50% { opacity: 1; }
51%, 100% { opacity: 0; }
}
/* 文档卡片样式 */
.doc-card {
background: 000000;
border: 1px solid #e1e5e9;
border-radius: 8px;
padding: 12px;
margin: 8px 0;
}
.doc-card:hover {
border-color: #667eea;
box-shadow: 0 2px 8px rgba(102, 126, 234, 0.1);
}
/* 状态指示器 */
.status-indicator {
display: inline-flex;
align-items: center;
gap: 6px;
padding: 4px 12px;
border-radius: 20px;
font-size: 12px;
font-weight: 500;
}
.status-rag {
background: #e3f2fd;
color: #1976d2;
}
.status-normal {
background: #f3e5f5;
color: #7b1fa2;
}
/* 隐藏Streamlit默认元素 */
#MainMenu {visibility: hidden;}
footer {visibility: hidden;}
header {visibility: hidden;}
/* 自定义按钮样式 */
.stButton > button {
background: linear-gradient(90deg, #667eea 0%, #764ba2 100%);
color: white;
border: none;
border-radius: 8px;
padding: 8px 16px;
font-weight: 500;
transition: all 0.2s;
}
.stButton > button:hover {
transform: translateY(-2px);
box-shadow: 0 4px 12px rgba(102, 126, 234, 0.3);
}
/* 响应式设计 */
@media (max-width: 768px) {
.chat-container {
margin: 10px;
height: 85vh;
}
.message-content {
max-width: 85%;
}
}
</style>
""", unsafe_allow_html=True)
def display_message(role, content, docs=None):
"""显示静态消息"""
message_class = "message user" if role == "user" else "message"
avatar_class = "user-avatar" if role == "user" else "assistant-avatar"
content_class = "user-message" if role == "user" else "assistant-message"
avatar_icon = "👤" if role == "user" else "🤖"
st.markdown(f"""
<div class="{message_class}">
<div class="message-avatar {avatar_class}">
{avatar_icon}
</div>
<div class="message-content {content_class}">
{content}
</div>
</div>
""", unsafe_allow_html=True)
def main():
# 侧边栏
with st.sidebar:
st.markdown("### 📁 文档管理")
# 文档上传
uploaded_files = st.file_uploader(
"上传知识库文档",
type=['pdf', 'docx', 'txt'],
accept_multiple_files=True,
help="支持 PDF、Word 和txt文件"
)
if uploaded_files:
for uploaded_file in uploaded_files:
if st.button(f"📤 处理 {uploaded_file.name}", key=f"process_{uploaded_file.name}"):
st.rerun()
st.markdown("---")
# 已有文档
st.markdown("### 📚 知识库")
documents = [{'filename': '1.txt', 'id': 1, 'created_at': {'strftime': '1:20'}, 'chunk_count': 10},
{'filename': '2.txt', 'chunk_count': 10, 'id': 2, 'created_at': {'strftime': '1:20'}}]
if documents:
doc_options = {f"{doc['filename']}": doc['id'] for doc in documents}
selected_docs = st.multiselect(
"选择知识源",
options=list(doc_options.keys()),
help="选择后将基于文档内容回答问题"
)
selected_doc_ids = [doc_options[doc] for doc in selected_docs]
# 显示文档列表
for doc in documents:
st.markdown(f"""
<div class="doc-card">
<strong>📄 {doc['filename']}</strong><br>
<small>📅 {doc['created_at']['strftime']}</small><br>
<small>📊 {doc['chunk_count']} 个文档块</small>
</div>
""", unsafe_allow_html=True)
else:
st.info("暂无文档,请先上传")
selected_doc_ids = []
total_docs = len(documents) if documents else 0
st.metric("📊 文档数", total_docs)
if st.button("🗑️ 清空对话"):
st.rerun()
# 主聊天界面
st.markdown("""
<div class="chat-container">
<div class="chat-header">
<div class="chat-title">
🤖 智能文档检索助手
</div>
<div class="chat-subtitle">
基于知识库的智能问答系统
</div>
</div>
</div>
""", unsafe_allow_html=True)
# 状态显示
col1, col2 = st.columns([2, 1])
with col1:
if selected_doc_ids:
st.markdown(f"""
<div class="status-indicator status-rag">
🔍 知识库模式 ({len(selected_doc_ids)} 个文档)
</div>
""", unsafe_allow_html=True)
else:
st.markdown("""
<div class="status-indicator status-normal">
💭 普通对话模式
</div>
""", unsafe_allow_html=True)
# 聊天消息显示区域
chat_container = st.container()
with chat_container:
# 欢迎消息
st.markdown("""
<div class="message">
<div class="message-avatar assistant-avatar">🤖</div>
<div class="message-content assistant-message">
👋 你好!我是你的AI智能助手。<br><br>
💡 <strong>我能做什么:</strong><br>
• 📚 基于你上传的文档回答问题<br>
• 💬 进行日常对话交流<br>
• 🔍 提供准确的信息检索<br><br>
请上传文档或直接开始对话吧!
</div>
</div>
""", unsafe_allow_html=True)
# 用户输入
if prompt := st.chat_input("💬 输入你的问题..."):
# 显示用户消息
display_message("user", prompt)
print(prompt)
if __name__ == "__main__":
main()
三. sqlalchemy 基本使用
1. 简介
SQLAlchemy 是 Python 社区中最流行且功能最强大的 数据库工具包 和 对象关系映射(ORM)框架。它提供了高效且灵活的数据库访问解决方案,使开发者能够用 Pythonic 的方式操作各种关系型数据库。
双引擎架构:
- ORM层(高阶抽象):简化数据模型操作
- Core层(SQL表达式语言):直接构建复杂SQL语句
官网: https://docs.sqlalchemy.org/en/20/
下载命令:
pip install sqlalchemy
2. 基本使用方法
2.1 orm入门
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.orm import declarative_base, sessionmaker
Base = declarative_base()
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String(50))
age = Column(Integer)
# 初始化引擎并创建表
engine = create_engine('mysql+pymysql://root:root@127.0.0.1:3306/spiders?charset=utf8')
Base.metadata.create_all(engine)
- 数据增删改查
# 创建和管理数据库会话(Session 对象)
Session = sessionmaker(bind=engine)
session = Session()
# 新增记录
new_user = User(name="Alice", age=30)
session.add(new_user)
session.commit()
# 查询记录
user = session.query(User).filter_by(name="Alice").first()
print(user.id, user.name) # 输出: 1 Alice
# 更新记录
user.age = 31
session.commit()
# 删除记录
session.delete(user)
session.commit()
四. 项目开发
1. 完整代码
- requirements.txt
streamlit==1.37.0
langchain==0.3.25
langchain-core==0.3.63
langchain-chroma==0.2.4
langchain-huggingface==0.2.0
langchain-openai==0.3.18
langchain-community==0.3.24
chromadb==1.0.12
pymysql==1.1.1
sqlalchemy==2.0.23
python-dotenv==1.0.0
pypdf2==2.11.2
python-docx==0.8.11
tiktoken==0.9.0
torch==2.7.0
import os
from dotenv import load_dotenv
load_dotenv()
class Config:
# OpenAI配置
OPENAI_API_KEY = os.getenv("DASHSCOPE_API_KEY")
OPENAI_BASE_URL = os.getenv("DASHSCOPE_BASE_URL")
# MySQL配置
MYSQL_HOST = os.getenv("MYSQL_HOST", "localhost")
MYSQL_PORT = int(os.getenv("MYSQL_PORT", 3306))
MYSQL_USER = os.getenv("MYSQL_USER", "root")
MYSQL_PASSWORD = os.getenv("MYSQL_PASSWORD", "root")
MYSQL_DATABASE = os.getenv("MYSQL_DATABASE", "rag")
# Chroma配置
CHROMA_PERSIST_DIR = os.getenv("CHROMA_PERSIST_DIR", "../core/chroma_db")
# 其他配置
CHUNK_SIZE = int(os.getenv("CHUNK_SIZE", 1000))
CHUNK_OVERLAP = int(os.getenv("CHUNK_OVERLAP", 200))
TOP_K = int(os.getenv("TOP_K", 5))
- 主文件 streamlit_app.py
import time
import streamlit as st
from config.config import Config
from core.database import DatabaseManager
from core.document_processor import DocumentProcessor
from core.vector_store import VectorStore
from core.rag_system import RAGSystem
import os
# 页面配置
st.set_page_config(
page_title="智能文档检索助手",
page_icon="🤖",
layout="wide",
initial_sidebar_state="collapsed"
)
# 自定义CSS样式
st.markdown("""
<style>
/* 聊天容器 */
.chat-container {
background: white;
border-radius: 12px;
box-shadow: 0 8px 32px rgba(0,0,0,0.1);
margin: 20px auto;
max-width: 800px;
display: flex;
flex-direction: column;
overflow: hidden;
}
/* 头部样式 */
.chat-header {
background: linear-gradient(90deg, #667eea 0%, #764ba2 100%);
color: white;
padding: 20px;
text-align: center;
border-radius: 12px 12px 0 0;
}
.chat-title {
font-size: 24px;
font-weight: 600;
margin: 0;
display: flex;
align-items: center;
justify-content: center;
gap: 10px;
}
.chat-subtitle {
font-size: 14px;
opacity: 0.9;
margin-top: 5px;
}
/* 聊天消息区域 */
.chat-messages {
flex: 1;
overflow-y: auto;
padding: 20px;
background: #f8f9fa;
}
/* 消息样式 */
.message {
margin-bottom: 16px;
display: flex;
align-items: flex-start;
gap: 12px;
}
.message.user {
flex-direction: row-reverse;
}
.message-avatar {
width: 36px;
height: 36px;
border-radius: 50%;
display: flex;
align-items: center;
justify-content: center;
font-size: 18px;
flex-shrink: 0;
}
.user-avatar {
background: linear-gradient(135deg, #667eea 0%, #764ba2 100%);
color: white;
}
.assistant-avatar {
background: linear-gradient(135deg, #84fab0 0%, #8fd3f4 100%);
color: white;
}
.message-content {
max-width: 70%;
padding: 12px 16px;
border-radius: 18px;
font-size: 14px;
line-height: 1.4;
}
.user-message {
background: linear-gradient(135deg, #667eea 0%, #764ba2 100%);
color: white;
border-bottom-right-radius: 4px;
}
.assistant-message {
background: white;
color: #333;
border: 1px solid #e1e5e9;
border-bottom-left-radius: 4px;
box-shadow: 0 1px 2px rgba(0,0,0,0.1);
}
/* 流式输出动画 */
.streaming-cursor::after {
content: '▊';
animation: blink 1s infinite;
color: #667eea;
}
@keyframes blink {
0%, 50% { opacity: 1; }
51%, 100% { opacity: 0; }
}
/* 文档卡片样式 */
.doc-card {
background: 000000;
border: 1px solid #e1e5e9;
border-radius: 8px;
padding: 12px;
margin: 8px 0;
}
.doc-card:hover {
border-color: #667eea;
box-shadow: 0 2px 8px rgba(102, 126, 234, 0.1);
}
/* 状态指示器 */
.status-indicator {
display: inline-flex;
align-items: center;
gap: 6px;
padding: 4px 12px;
border-radius: 20px;
font-size: 12px;
font-weight: 500;
}
.status-rag {
background: #e3f2fd;
color: #1976d2;
}
.status-normal {
background: #f3e5f5;
color: #7b1fa2;
}
/* 隐藏Streamlit默认元素 */
#MainMenu {visibility: hidden;}
footer {visibility: hidden;}
header {visibility: hidden;}
/* 自定义按钮样式 */
.stButton > button {
background: linear-gradient(90deg, #667eea 0%, #764ba2 100%);
color: white;
border: none;
border-radius: 8px;
padding: 8px 16px;
font-weight: 500;
transition: all 0.2s;
}
.stButton > button:hover {
transform: translateY(-2px);
box-shadow: 0 4px 12px rgba(102, 126, 234, 0.3);
}
/* 响应式设计 */
@media (max-width: 768px) {
.chat-container {
margin: 10px;
height: 85vh;
}
.message-content {
max-width: 85%;
}
}
</style>
""", unsafe_allow_html=True)
# 初始化组件
# @st.cache_resource 做热启动 多用户访问时不需要重复去执行代码(类似单列)
@st.cache_resource
def init_system():
# 读取配置
config = Config()
# 创建数据库操作对象
db_manager = DatabaseManager(config)
# # 创建文档操作对象
doc_processor = DocumentProcessor(config)
# 创建向量操作对象
vector_store = VectorStore(config)
# 创建RAG操作对象
rag_system = RAGSystem(config, db_manager, vector_store)
return config, db_manager, doc_processor, vector_store, rag_system
def upload_and_process_document(uploaded_file, doc_processor, vector_store, db_manager):
with st.spinner(f"正在处理文档 {uploaded_file.name}..."):
try:
# 加载上传的文档
documents = doc_processor.load_document(uploaded_file)
# 创建父子文档块
parent_docs, child_docs = doc_processor.create_parent_child_chunks(documents, uploaded_file.name)
# 添加文档到向量存储
parent_vector_ids, child_vector_ids = vector_store.add_documents(parent_docs, child_docs, 0)
# 将文档存储到MySQL数据库中
content = "\n".join([doc.page_content for doc in documents])
doc_id = db_manager.save_document_with_chunks(
filename=uploaded_file.name,
file_path="",
content=content,
parent_docs=parent_docs,
child_docs=child_docs,
parent_vector_ids=parent_vector_ids,
child_vector_ids=child_vector_ids
)
for doc in parent_docs + child_docs:
doc.metadata['document_id'] = str(doc_id)
st.success(f"✅ 文档 '{uploaded_file.name}' 上传成功!")
return True
except Exception as e:
st.error(f"❌ 文档处理失败: {str(e)}")
return False
def display_message(role, content, docs=None):
"""显示静态消息"""
message_class = "message user" if role == "user" else "message"
avatar_class = "user-avatar" if role == "user" else "assistant-avatar"
content_class = "user-message" if role == "user" else "assistant-message"
avatar_icon = "👤" if role == "user" else "🤖"
st.markdown(f"""
<div class="{message_class}">
<div class="message-avatar {avatar_class}">
{avatar_icon}
</div>
<div class="message-content {content_class}">
{content}
</div>
</div>
""", unsafe_allow_html=True)
# 如果有参考文档,显示在消息下方
if docs and role == "assistant":
with st.expander("📚 参考来源", expanded=False):
for i, doc in enumerate(docs, 1):
st.markdown(f"""
<div class="doc-card">
<strong>📄 片段 {i}</strong><br>
{doc.page_content[:200]}{'...' if len(doc.page_content) > 200 else ''}
</div>
""", unsafe_allow_html=True)
def stream_response_generator(rag_system, message, selected_doc_ids, session_id, is_rag_mode=True):
"""生成流式响应的生成器函数"""
if is_rag_mode:
# RAG模式 - 需要修改RAGSystem以支持流式输出
response, retrieved_docs = rag_system.chat_with_documents(
message, selected_doc_ids, session_id
)
# 模拟流式输出(如果RAGSystem不支持流式,可以这样处理)
words = response.split()
current_response = ""
for i, word in enumerate(words):
current_response += word + " "
yield current_response.strip(), retrieved_docs if i == len(words) - 1 else None
time.sleep(0.05) # 控制流式速度
else:
# 普通对话模式
response = rag_system.normal_chat(message, session_id)
# 模拟流式输出
words = response.split()
current_response = ""
for word in words:
current_response += word + " "
yield current_response.strip(), None
time.sleep(0.05)
def display_streaming_message(role, generator, docs_placeholder=None):
"""显示流式消息"""
message_class = "message user" if role == "user" else "message"
avatar_class = "user-avatar" if role == "user" else "assistant-avatar"
content_class = "user-message" if role == "user" else "assistant-message"
avatar_icon = "👤" if role == "user" else "🤖"
# 创建消息容器的占位符
message_placeholder = st.empty()
final_content = ""
retrieved_docs = None
# 流式显示内容
print("generator->", generator)
for content, docs in generator:
final_content = content
if docs is not None:
retrieved_docs = docs
# 添加流式光标效果
display_content = content + " <span class='streaming-cursor'></span>"
message_placeholder.markdown(f"""
<div class="{message_class}">
<div class="message-avatar {avatar_class}">
{avatar_icon}
</div>
<div class="message-content {content_class}">
{display_content}
</div>
</div>
""", unsafe_allow_html=True)
# 最终显示(移除光标)
message_placeholder.markdown(f"""
<div class="{message_class}">
<div class="message-avatar {avatar_class}">
{avatar_icon}
</div>
<div class="message-content {content_class}">
{final_content}
</div>
</div>
""", unsafe_allow_html=True)
# 显示参考文档
if retrieved_docs and role == "assistant" and docs_placeholder:
with docs_placeholder:
with st.expander("📚 参考来源", expanded=False):
for i, doc in enumerate(retrieved_docs, 1):
st.markdown(f"""
<div class="doc-card">
<strong>📄 片段 {i}</strong><br>
{doc.page_content[:200]}{'...' if len(doc.page_content) > 200 else ''}
</div>
""", unsafe_allow_html=True)
return final_content, retrieved_docs
def main():
# 初始化系统
config, db_manager, doc_processor, vector_store, rag_system = init_system()
# 侧边栏
with st.sidebar:
st.markdown("### 📁 文档管理")
# 文档上传
uploaded_files = st.file_uploader(
"上传知识库文档",
type=['pdf', 'docx', 'txt'],
accept_multiple_files=True,
help="支持 PDF、Word 和txt文件"
)
if uploaded_files:
for uploaded_file in uploaded_files:
if st.button(f"📤 处理 {uploaded_file.name}", key=f"process_{uploaded_file.name}"):
if upload_and_process_document(uploaded_file, doc_processor, vector_store, db_manager):
st.rerun()
st.markdown("---")
# 已有文档
st.markdown("### 📚 知识库")
documents = db_manager.get_all_documents()
if documents:
doc_options = {f"{doc.filename}": doc.id for doc in documents}
selected_docs = st.multiselect(
"选择知识源",
options=list(doc_options.keys()),
help="选择后将基于文档内容回答问题"
)
selected_doc_ids = [doc_options[doc] for doc in selected_docs]
# 显示文档列表
for doc in documents:
st.markdown(f"""
<div class="doc-card">
<strong>📄 {doc.filename}</strong><br>
<small>📅 {doc.created_at.strftime('%Y-%m-%d %H:%M')}</small><br>
<small>📊 {doc.chunk_count} 个文档块</small>
</div>
""", unsafe_allow_html=True)
else:
st.info("暂无文档,请先上传")
selected_doc_ids = []
total_docs = len(documents) if documents else 0
st.metric("📊 文档数", total_docs)
if st.button("🗑️ 清空对话"):
st.session_state.messages = []
st.session_state.session_id = None
st.rerun()
# 主聊天界面
st.markdown("""
<div class="chat-container">
<div class="chat-header">
<div class="chat-title">
🤖 智能文档检索助手
</div>
<div class="chat-subtitle">
基于知识库的智能问答系统
</div>
</div>
</div>
""", unsafe_allow_html=True)
# 状态显示
col1, col2 = st.columns([2, 1])
with col1:
if selected_doc_ids:
st.markdown(f"""
<div class="status-indicator status-rag">
🔍 知识库模式 ({len(selected_doc_ids)} 个文档)
</div>
""", unsafe_allow_html=True)
else:
st.markdown("""
<div class="status-indicator status-normal">
💭 普通对话模式
</div>
""", unsafe_allow_html=True)
# 初始化会话状态
if 'session_id' not in st.session_state or st.session_state.session_id is None:
st.session_state.session_id = rag_system.generate_session_id()
if 'messages' not in st.session_state:
st.session_state.messages = []
# 聊天消息显示区域
chat_container = st.container()
with chat_container:
if not st.session_state.messages:
# 欢迎消息
st.markdown("""
<div class="message">
<div class="message-avatar assistant-avatar">🤖</div>
<div class="message-content assistant-message">
👋 你好!我是你的AI智能助手。<br><br>
💡 <strong>我能做什么:</strong><br>
• 📚 基于你上传的文档回答问题<br>
• 💬 进行日常对话交流<br>
• 🔍 提供准确的信息检索<br><br>
请上传文档或直接开始对话吧!
</div>
</div>
""", unsafe_allow_html=True)
else:
# 显示历史消息
for message in st.session_state.messages:
display_message(
message["role"],
message["content"],
message.get("docs")
)
# 用户输入
if prompt := st.chat_input("💬 输入你的问题..."):
# 添加用户消息
st.session_state.messages.append({"role": "user", "content": prompt})
# 显示用户消息
display_message("user", prompt)
# 创建文档占位符
docs_placeholder = st.empty()
# 生成助手回复(流式)
with st.spinner("🤔 思考中..."):
if selected_doc_ids:
# RAG模式流式输出
generator = stream_response_generator(
rag_system, prompt, selected_doc_ids,
st.session_state.session_id, is_rag_mode=True
)
final_content, retrieved_docs = display_streaming_message(
"assistant", generator, docs_placeholder
)
# 添加到消息历史
st.session_state.messages.append({
"role": "assistant",
"content": final_content,
"docs": retrieved_docs
})
else:
# 普通对话模式流式输出
generator = stream_response_generator(
rag_system, prompt, [],
st.session_state.session_id, is_rag_mode=False
)
final_content, _ = display_streaming_message("assistant", generator)
# 添加到消息历史
st.session_state.messages.append({
"role": "assistant",
"content": final_content
})
if __name__ == "__main__":
main()
from sqlalchemy import create_engine, Column, Integer, String, DateTime, Boolean, ForeignKey, Index, Text
from sqlalchemy.dialects.mysql import MEDIUMTEXT
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker, relationship
from datetime import datetime
import pymysql
Base = declarative_base()
class Document(Base):
__tablename__ = 'documents'
id = Column(Integer, primary_key=True, autoincrement=True)
filename = Column(String(255), nullable=False)
file_path = Column(String(500), nullable=False)
content = Column(MEDIUMTEXT, nullable=False)
chunk_count = Column(Integer, default=0)
created_at = Column(DateTime, default=datetime.now())
is_active = Column(Boolean, default=True)
# 关联关系
parent_chunks = relationship("ParentChunk", back_populates="document", cascade="all, delete-orphan")
child_chunks = relationship("ChildChunk", back_populates="document", cascade="all, delete-orphan")
class ParentChunk(Base):
__tablename__ = 'parent_chunks'
id = Column(Integer, primary_key=True, autoincrement=True)
document_id = Column(Integer, ForeignKey('documents.id'), nullable=False)
parent_id = Column(String(100), nullable=False, unique=True) # 父文档唯一标识
content = Column(Text, nullable=False)
json_metadata = Column(Text) # JSON格式存储元数据
vector_id = Column(String(100)) # Chroma中的向量ID
created_at = Column(DateTime, default=datetime.now())
# 关联关系
document = relationship("Document", back_populates="parent_chunks")
child_chunks = relationship("ChildChunk", back_populates="parent_chunk", cascade="all, delete-orphan")
# 索引
__table_args__ = (
Index('idx_parent_document_id', 'document_id'),
Index('idx_parent_id', 'parent_id'),
)
class ChildChunk(Base):
__tablename__ = 'child_chunks'
id = Column(Integer, primary_key=True, autoincrement=True)
document_id = Column(Integer, ForeignKey('documents.id'), nullable=False)
parent_chunk_id = Column(Integer, ForeignKey('parent_chunks.id'), nullable=False)
child_id = Column(String(100), nullable=False) # 子文档标识
content = Column(Text, nullable=False)
json_metadata = Column(Text) # JSON格式存储元数据
vector_id = Column(String(100)) # Chroma中的向量ID
created_at = Column(DateTime, default=datetime.now())
# 关联关系
document = relationship("Document", back_populates="child_chunks")
parent_chunk = relationship("ParentChunk", back_populates="child_chunks")
# 索引
__table_args__ = (
Index('idx_child_document_id', 'document_id'),
Index('idx_child_parent_id', 'parent_chunk_id'),
Index('idx_child_id', 'child_id'),
)
class ChatHistory(Base):
__tablename__ = 'chat_history'
id = Column(Integer, primary_key=True, autoincrement=True)
session_id = Column(String(100), nullable=False)
user_message = Column(Text, nullable=False)
assistant_message = Column(Text, nullable=False)
document_ids = Column(String(500)) # 存储使用的文档ID,逗号分隔
used_chunks = Column(Text) # JSON格式存储使用的文档块信息
created_at = Column(DateTime, default=datetime.now())
# 索引
__table_args__ = (
Index('idx_chat_session_id', 'session_id'),
Index('idx_chat_created_at', 'created_at'),
)
class DatabaseManager:
def __init__(self, config):
self.config = config
self.engine = None
self.SessionLocal = None
self.init_database()
def init_database(self):
# 创建数据库连接
connection_string = f"mysql+pymysql://{self.config.MYSQL_USER}:{self.config.MYSQL_PASSWORD}@{self.config.MYSQL_HOST}:{self.config.MYSQL_PORT}/{self.config.MYSQL_DATABASE}?charset=utf8mb4"
try:
self.engine = create_engine(connection_string, echo=False)
# 创建所有的表
Base.metadata.create_all(self.engine)
self.SessionLocal = sessionmaker(bind=self.engine)
print("数据库连接成功")
except Exception as e:
print(f"数据库连接失败: {e}")
raise
def get_session(self):
return self.SessionLocal()
def save_document_with_chunks(self, filename, file_path, content, parent_docs, child_docs, parent_vector_ids,
child_vector_ids):
"""保存文档及其父子文档块"""
session = self.get_session()
try:
# 保存主文档
doc = Document(
filename=filename,
file_path=file_path,
content=content,
chunk_count=len(child_docs)
)
session.add(doc)
session.flush() # 获取文档ID
doc_id = doc.id
# 保存父文档块
parent_chunk_map = {} # parent_id -> parent_chunk_id 映射
for i, (parent_doc, vector_id) in enumerate(zip(parent_docs, parent_vector_ids)):
parent_chunk = ParentChunk(
document_id=doc_id,
parent_id=parent_doc.metadata.get('parent_id', f'parent_{i}'),
content=parent_doc.page_content,
json_metadata=str(parent_doc.metadata),
vector_id=vector_id
)
session.add(parent_chunk)
session.flush()
parent_chunk_map[parent_chunk.parent_id] = parent_chunk.id
# 保存子文档块
for child_doc, vector_id in zip(child_docs, child_vector_ids):
parent_id = child_doc.metadata.get('parent_id', 'unknown')
parent_chunk_id = parent_chunk_map.get(parent_id)
child_chunk = ChildChunk(
document_id=doc_id,
parent_chunk_id=parent_chunk_id,
child_id=child_doc.metadata.get('child_id', f'child_{len(child_docs)}'),
content=child_doc.page_content,
json_metadata=str(child_doc.metadata),
vector_id=vector_id
)
session.add(child_chunk)
session.commit()
return doc_id
except Exception as e:
session.rollback()
raise e
finally:
session.close()
def get_all_documents(self):
session = self.get_session()
try:
docs = session.query(Document).filter(Document.is_active == True).all()
return docs
finally:
session.close()
def get_document_chunks(self, document_id):
"""获取文档的所有父子块"""
session = self.get_session()
try:
parent_chunks = session.query(ParentChunk).filter(
ParentChunk.document_id == document_id
).all()
child_chunks = session.query(ChildChunk).filter(
ChildChunk.document_id == document_id
).all()
return parent_chunks, child_chunks
finally:
session.close()
def get_parent_chunk_by_id(self, parent_id):
"""根据parent_id获取父文档块"""
session = self.get_session()
try:
parent_chunk = session.query(ParentChunk).filter(
ParentChunk.parent_id == parent_id
).first()
return parent_chunk
finally:
session.close()
def get_child_chunks_by_parent(self, parent_chunk_id):
"""获取指定父文档的所有子文档块"""
session = self.get_session()
try:
child_chunks = session.query(ChildChunk).filter(
ChildChunk.parent_chunk_id == parent_chunk_id
).all()
return child_chunks
finally:
session.close()
def delete_document(self, document_id):
"""删除文档及其所有块(级联删除)"""
session = self.get_session()
try:
doc = session.query(Document).filter(Document.id == document_id).first()
if doc:
doc.is_active = False # 软删除
session.commit()
return True
return False
except Exception as e:
session.rollback()
raise e
finally:
session.close()
def save_chat_history(self, session_id, user_message, assistant_message, document_ids=None, used_chunks=None):
session = self.get_session()
try:
chat = ChatHistory(
session_id=session_id,
user_message=user_message,
assistant_message=assistant_message,
document_ids=document_ids,
used_chunks=used_chunks
)
session.add(chat)
session.commit()
except Exception as e:
session.rollback()
raise e
finally:
session.close()
def get_chat_history(self, session_id, limit=10):
session = self.get_session()
try:
chats = session.query(ChatHistory).filter(
ChatHistory.session_id == session_id
).order_by(ChatHistory.created_at.desc()).limit(limit).all()
return list(reversed(chats))
finally:
session.close()
def get_document_statistics(self):
"""获取文档统计信息"""
session = self.get_session()
try:
total_docs = session.query(Document).filter(Document.is_active == True).count()
total_parent_chunks = session.query(ParentChunk).count()
total_child_chunks = session.query(ChildChunk).count()
return {
'total_documents': total_docs,
'total_parent_chunks': total_parent_chunks,
'total_child_chunks': total_child_chunks
}
finally:
session.close()
- document_processor.py
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader, TextLoader
from langchain_community.document_loaders import Docx2txtLoader
import os
import tempfile
class DocumentProcessor:
def __init__(self, config):
self.config = config
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=self.config.CHUNK_SIZE,
chunk_overlap=self.config.CHUNK_OVERLAP,
separators=["\n\n", "\n", "。", "!", "?", ".", "!", "?", " ", ""]
)
# 父子文档分割器
self.parent_splitter = RecursiveCharacterTextSplitter(
chunk_size=self.config.CHUNK_SIZE * 2, # 父文档更大
chunk_overlap=self.config.CHUNK_OVERLAP,
separators=["\n\n", "\n", "。", "!", "?"]
)
self.child_splitter = RecursiveCharacterTextSplitter(
chunk_size=self.config.CHUNK_SIZE // 2, # 子文档更小
chunk_overlap=self.config.CHUNK_OVERLAP // 2,
separators=["\n", "。", "!", "?", ".", "!", "?", " "]
)
def load_document(self, uploaded_file):
"""加载上传的文档"""
# 保存临时文件
with tempfile.NamedTemporaryFile(delete=False, suffix=f".{uploaded_file.name.split('.')[-1]}") as tmp_file:
tmp_file.write(uploaded_file.getvalue())
tmp_path = tmp_file.name
try:
# 根据文件类型选择加载器
if uploaded_file.name.endswith('.pdf'):
loader = PyPDFLoader(tmp_path)
elif uploaded_file.name.endswith('.docx'):
loader = Docx2txtLoader(tmp_path)
elif uploaded_file.name.endswith('.txt'):
loader = TextLoader(tmp_path, encoding='utf-8')
else:
raise ValueError(f"不支持的文件类型: {uploaded_file.name}")
documents = loader.load()
return documents
finally:
# 清理临时文件
if os.path.exists(tmp_path):
os.unlink(tmp_path)
def create_parent_child_chunks(self, documents, fileName):
"""创建父子文档块"""
parent_docs = self.parent_splitter.split_documents(documents)
child_docs = []
for i, parent_doc in enumerate(parent_docs):
# 为每个父文档创建唯一ID
parent_id = f"{fileName}_parent_{i}"
parent_doc.metadata['parent_id'] = parent_id
parent_doc.metadata['doc_type'] = 'parent'
# 从父文档创建子文档
child_chunks = self.child_splitter.split_documents([parent_doc])
for j, child_doc in enumerate(child_chunks):
child_doc.metadata['parent_id'] = parent_id
child_doc.metadata['child_id'] = f"child_{i}_{j}"
child_doc.metadata['doc_type'] = 'child'
child_docs.append(child_doc)
return parent_docs, child_docs
- rag_system.py
from langchain_openai import ChatOpenAI
from langchain.memory import ConversationBufferWindowMemory
from langchain.prompts import PromptTemplate
import uuid
class RAGSystem:
def __init__(self, config, db_manager, vector_store):
self.config = config
self.db_manager = db_manager
self.vector_store = vector_store
# 初始化LLM
self.llm = ChatOpenAI(
api_key=config.OPENAI_API_KEY,
base_url=config.OPENAI_BASE_URL,
model="qwen-plus",
temperature=0.7,
streaming=True,
)
# 对话记忆
self.memory = ConversationBufferWindowMemory(
memory_key="chat_history",
return_messages=True,
k=5 # 保留最近5轮对话
)
# RAG提示模板
self.rag_prompt = PromptTemplate(
template="""你是一个智能助手。请基于以下上下文信息回答用户的问题。如果上下文中没有相关信息,请诚实地说明。
上下文信息:
{context}
历史对话:
{chat_history}
用户问题: {question}
请提供准确、有帮助的回答:""",
input_variables=["context", "chat_history", "question"]
)
def generate_session_id(self):
"""生成会话ID"""
return str(uuid.uuid4())
def chat_with_documents(self, question, document_ids, session_id):
"""基于文档的RAG对话"""
try:
# 创建检索器
retriever = self.vector_store.create_retriever(
use_compression=True
)
# 检索相关文档
retrieved_docs = retriever.invoke(question)
# 获取父文档以提供更完整的上下文
parent_docs = self.vector_store.get_parent_documents(retrieved_docs)
all_docs = retrieved_docs + parent_docs
# 构建上下文
context = "\n\n".join([doc.page_content for doc in all_docs[:self.config.TOP_K]])
print("最终检索的上下文:", context)
# 获取历史对话
chat_history = self.db_manager.get_chat_history(session_id)
history_text = "\n".join([
f"用户: {chat.user_message}\n助手: {chat.assistant_message}"
for chat in chat_history[-3:] # 最近3轮对话
])
# 构建完整提示
full_prompt = self.rag_prompt.format(
context=context,
chat_history=history_text,
question=question
)
# 生成回答
response = self.llm.invoke(full_prompt)
answer = response.content
# 保存对话历史
self.db_manager.save_chat_history(
session_id=session_id,
user_message=question,
assistant_message=answer,
document_ids=",".join(map(str, document_ids))
)
return answer, retrieved_docs
except Exception as e:
error_msg = f"RAG对话出错: {str(e)}"
print(error_msg)
return error_msg, []
def normal_chat(self, question, session_id):
"""普通对话(不使用文档)"""
try:
# 获取历史对话
chat_history = self.db_manager.get_chat_history(session_id)
# 构建对话上下文
messages = []
for chat in chat_history[-5:]: # 最近5轮对话
messages.append(f"Human: {chat.user_message}")
messages.append(f"Assistant: {chat.assistant_message}")
# 添加当前问题
messages.append(f"Human: {question}")
conversation_context = "\n".join(messages)
# 生成回答
response = self.llm.invoke(conversation_context + "\nAssistant:")
answer = response.content
# 保存对话历史
self.db_manager.save_chat_history(
session_id=session_id,
user_message=question,
assistant_message=answer
)
return answer
except Exception as e:
error_msg = f"普通对话出错: {str(e)}"
print(error_msg)
return error_msg
- vector_store.py
import chromadb
from langchain_chroma import Chroma
from langchain_huggingface import HuggingFaceEmbeddings
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
from langchain_openai import ChatOpenAI
class VectorStore:
def __init__(self, config):
self.config = config
# 初始化模型
embed_path = r"D:\LLM\Local_model\BAAI\bge-large-zh-v1___5"
self.embeddings = HuggingFaceEmbeddings(model_name=embed_path)
# 初始化Chroma客户端
self.chroma_client = chromadb.PersistentClient(
path=config.CHROMA_PERSIST_DIR
)
# 父文档和子文档使用不同的集合
self.parent_vectorstore = Chroma(
client=self.chroma_client,
collection_name="parent_documents",
embedding_function=self.embeddings
)
self.child_vectorstore = Chroma(
client=self.chroma_client,
collection_name="child_documents",
embedding_function=self.embeddings
)
# 初始化上下文压缩器
self.llm = ChatOpenAI(
api_key=config.OPENAI_API_KEY,
base_url=config.OPENAI_BASE_URL,
model="qwen-plus-2025-04-28",
temperature=0
)
self.compressor = LLMChainExtractor.from_llm(self.llm)
def add_documents(self, parent_docs, child_docs, document_id):
"""添加文档到向量存储"""
# 为所有文档添加document_id元数据
for doc in parent_docs + child_docs:
doc.metadata['document_id'] = str(document_id)
# 存储父文档和子文档
parent_ids = self.parent_vectorstore.add_documents(parent_docs)
child_ids = self.child_vectorstore.add_documents(child_docs)
return parent_ids, child_ids
def get_parent_documents_by_metadata(self, parent_ids):
"""根据parent_id列表获取父文档"""
if not parent_ids:
return []
parent_docs = []
for parent_id in parent_ids:
try:
# 使用相似度搜索并过滤parent_id
results = self.parent_vectorstore.similarity_search(
"",
k=10, # 获取更多结果进行过滤
filter={"parent_id": parent_id}
)
parent_docs.extend(results[:1]) # 每个parent_id只取一个结果
except Exception as e:
print(f"获取父文档时出错 (parent_id: {parent_id}): {e}")
continue
return parent_docs
def create_retriever(self, use_compression=True):
"""创建检索器"""
# 创建子文档检索器(用于初始检索)
child_retriever = self.child_vectorstore.as_retriever(
search_kwargs={
"k": self.config.TOP_K * 2, # 获取更多子文档
}
)
if use_compression:
# 使用上下文压缩检索器
compression_retriever = ContextualCompressionRetriever(
base_compressor=self.compressor,
base_retriever=child_retriever
)
return compression_retriever
else:
return child_retriever
def get_parent_documents(self, child_docs):
"""根据子文档获取对应的父文档"""
parent_ids = set()
for doc in child_docs:
if 'parent_id' in doc.metadata:
parent_ids.add(doc.metadata['parent_id'])
return self.get_parent_documents_by_metadata(list(parent_ids))
def delete_document(self, document_id):
"""删除指定文档的所有向量"""
filter_dict = {"document_id": str(document_id)}
# 删除父文档和子文档
try:
self.parent_vectorstore.delete(filter=filter_dict)
self.child_vectorstore.delete(filter=filter_dict)
except Exception as e:
print(f"删除向量时出错: {e}")
阅读建议

评论
匿名评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果
最近发布