
12-项目部署
项目部署
学习目标:
- 虚拟机配置方式
- Linux基本操作
- scrapyd项目部署
- scrapyweb可视化解密管理
一. 虚拟机
1. 虚拟机的作用
- 虚拟机,在计算机科学中的体系结构里,是指一种特殊的软件,可以在计算机平台和终端用户之间创建一种环境,而终端用户则是基于虚拟机这个软件所创建的环境来操作其它软件。
- 虚拟机
- VMware (课上使用)
- Oracle VirtualBox
- Microsoft Hyper-V
- 下载地址
- https://softwareupdate.vmware.com/cds/vmw-desktop/ws/17.5.2/23775571/
- 17版本激活码: MC60H-DWHD5-H80U9-6V85M-8280D
二. 环境配置
1. 镜像配置
iso镜像下载- 阿里镜像源网址:https://developer.aliyun.com/mirror/
- 选中os镜像,选择自己需要的镜像(操作系统)版本(课程使用ubuntu20.04.6)
- ubuntu简介
- Ubuntu20.04. 是Ubuntu操作系统的一个重要版本。基于linux进行开发,它于2020年4月发布,是Ubuntu团队的第一个长期支持版本(LTS),提供了长达5年的安全更新和技术支持。
2. 环境搭建
python环境配置- 在
miniconda3官网中下载sh文件并安装
# 安装指令
sh <sh文件名称>
MySQL数据库安装
sudo apt install mysql-server
# 安装成功后mysql默认无密码
# 进入到mysql表自行修改密码
Redis数据库安装
sudo apt install redis-server
MongoDB数据库安装
sudo apt mongodb
- 如果需要查询虚拟机
ip地址需安装net-tools
sudo apt install net-tools
三. Linux常见命令
1.cd 命令
(它用于切换当前目录,它的参数是要切换到的目录的路径,可以是绝对路径,也可以是相对路径)
cd /home进入 ‘/ home’ 目录cd ..返回上一级目录cd ../..返回上两级目录- cd / 返回跟目录
- cd - 返回上次所在的目录
2 . mkdir命令
(用于创建文件夹)
mkdir <目录名>创建目录mkdir dir1 dir2同时创建两个目录mkdir -p /tmp/dir1/dir2递归创建目录树
3 . rm命令
(用于删除文件)
rm -f file1删除’file1’⽂件rmdir dir1删除’dir1’⽬录rm -rf dir1删除’dir1’⽬录和其内容-rm -rf dir1 dir2同时删除两个⽬录及其内容- -f :就是force的意思,忽略不存在的文件,不会出现警告消息
- -i :互动模式,在删除前会询问用户是否操作
- -r :递归删除,最常用于目录删除,它是一个非常危险的参数
4、pwd 命令
- pwd 显示工作路径
5、ls 命令
- ls 查看目录中的文件
- ls -l 显示文件和目录的详细资料
- ls -a 列出全部文件,包含隐藏文件
- ls -lh 查看⽂件和⽬录的详情列表(增强⽂件⼤⼩易读性)
- ls -lSr 查看⽂件和⽬录列表(以⽂件⼤⼩升序查看)
- tree 查看⽂件和⽬录的树形结构 (如果没有需要先安装 yum install tree)
- ls -R 连同子目录的内容一起列出(递归列出),等于该目录下的所有文件都会显示出来
- ls -al /proc/pid/exe 通过pid查询程序正在运行的路径
命令网址:https://blog.csdn.net/qq_43108153/article/details/136230423
6. vim编辑器
(编辑器之神)
命令网址:https://blog.csdn.net/2301_79695159/article/details/140323426
四. scrapyd部署
1. scrapyd的概念
scarpy是一个爬虫框架,而scrapyd相当于一个组件,能够将scrapy项目进行远程部署,调度使用等。
2. 服务端配置
- 安装
scrapyd
pip install scrapyd -i https://pypi.tuna.tsinghua.edu.cn/simple
- 运行
scrapyd - 在服务端执行
scrapyd指令
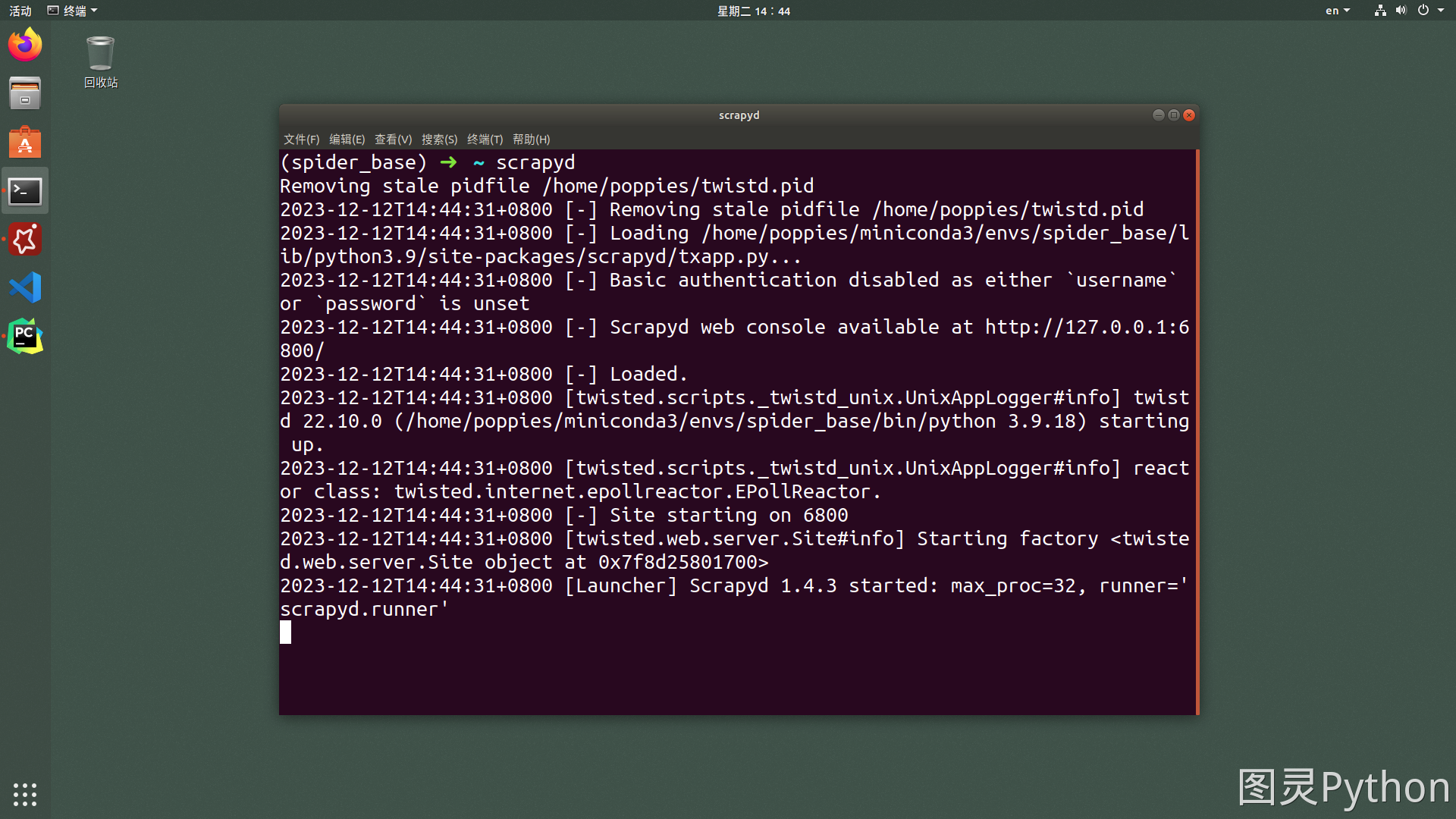
- 修改配置让
scrapyd支持远程访问 - 使用
ctrl+c停止上一步运行的scrapyd,并在你想要运行爬虫项目的路径之下新建scrapyd.conf文件。
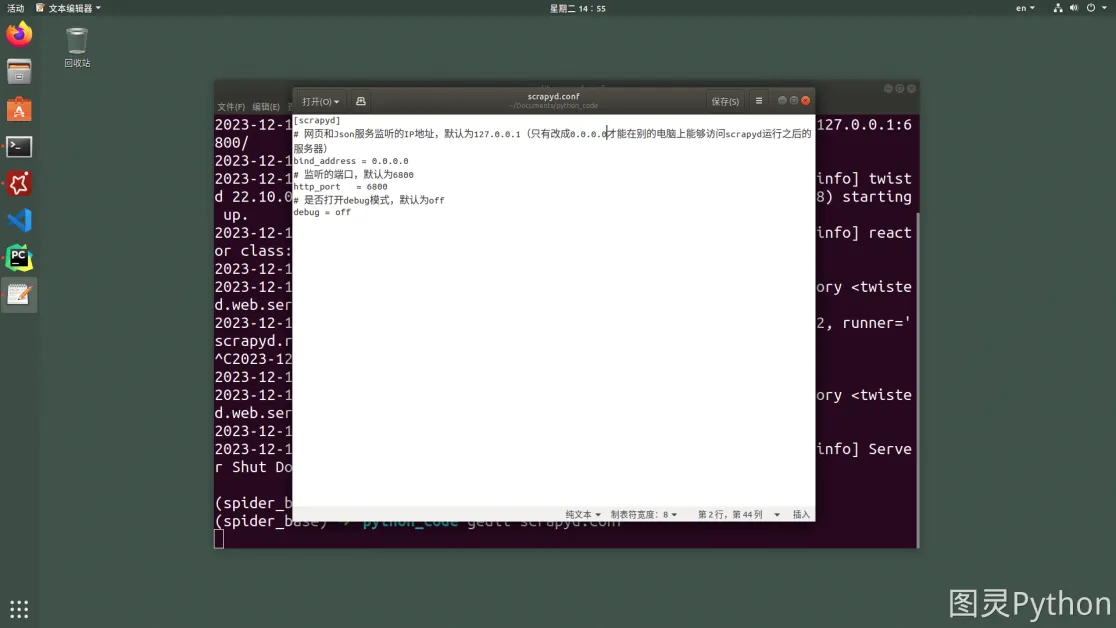
- 插入代码
[scrapyd]
# 监听的IP地址,默认为127.0.0.1(只有改成0.0.0.0才能在别的电脑上能够访问scrapyd运行之后的服务器)
bind_address = 0.0.0.0
# 监听的端口,默认为6800
http_port = 6800
# 是否打开debug模式,默认为off
debug = off
- 重新执行
scrapyd- 在刚刚新建
scrpayd.conf文件所在路径下通过终端运行scrapyd。
- 在刚刚新建
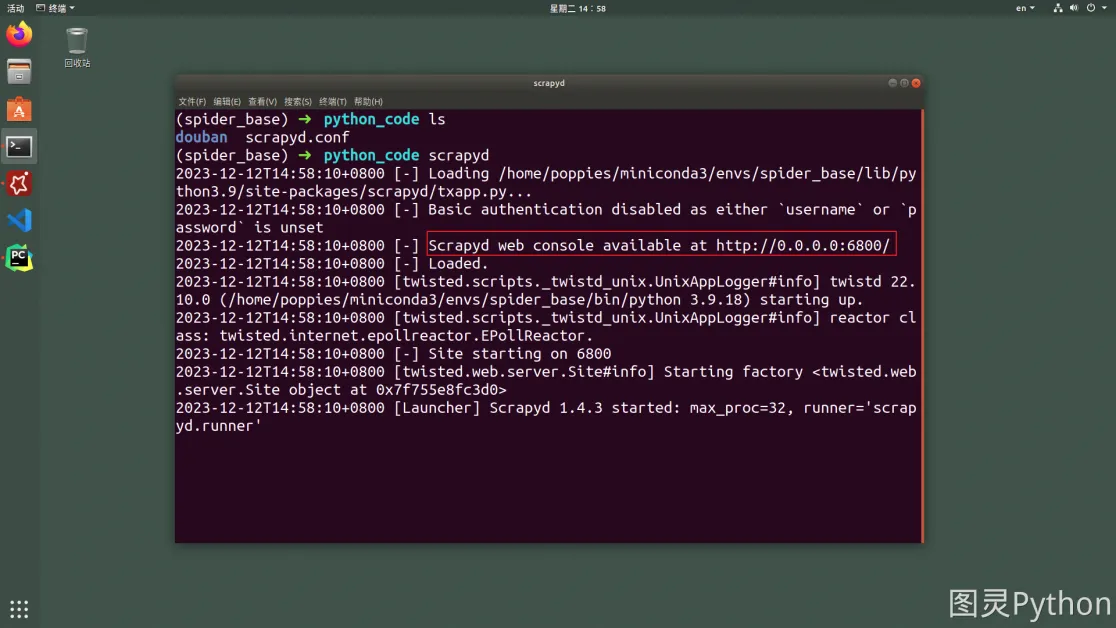
- 在物理机上使用浏览器访问服务器
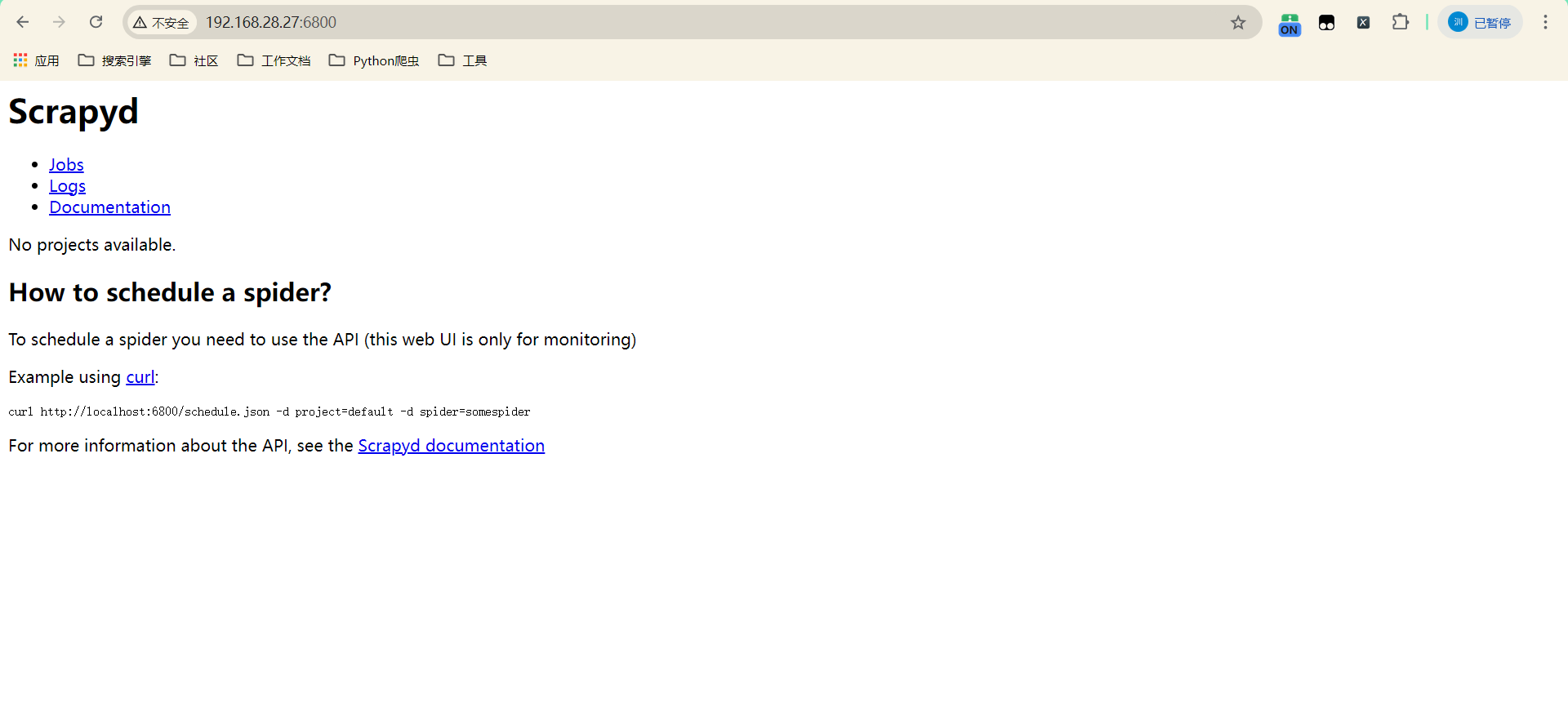
3. 客户端配置
- 安装
scrapyd-client
pip install scrapyd-client -i https://pypi.tuna.tsinghua.edu.cn/simple
- 配置
scrapy项目
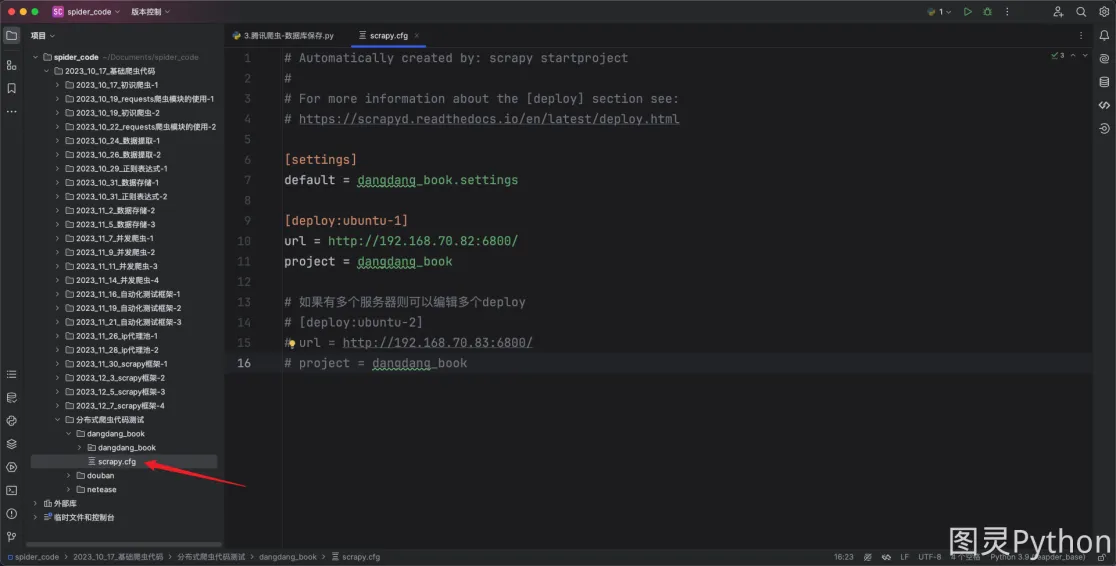
如果运行的
scrapy的服务器只有一个则配置一个deploy即可,如果有多台服务器则配置多个deploy。
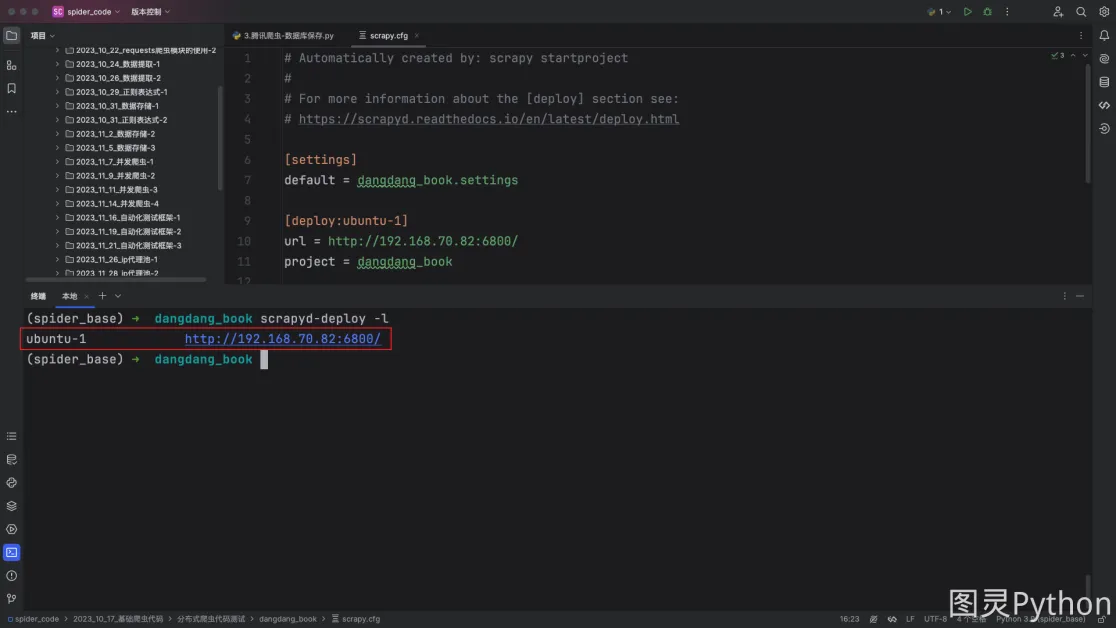
- 检查配置是否生效
在
scrapy项目根路径之下运行如下命令:
# 注意是小写的L,不是数字1
scrapyd-deploy -l
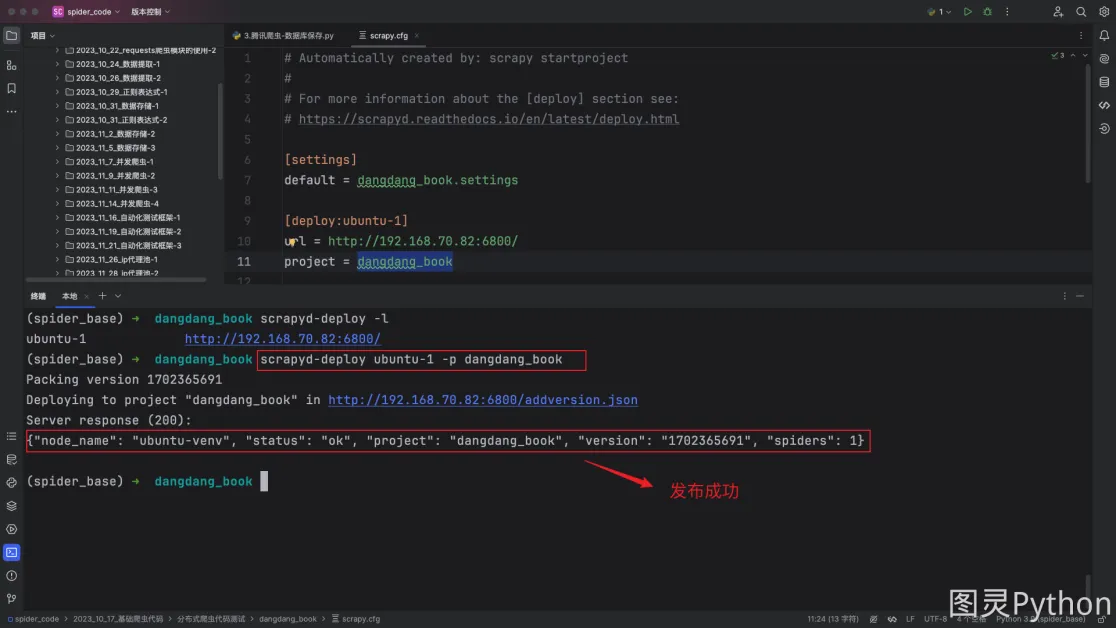
- 发布
scrapy项目到scrapyd所在的服务器(当前爬虫是未运行状态)
scrapyd-deploy <target> -p <project> --version <version>
● target:就是前面配置文件里deploy后面的的target名字,例如ubuntu-1
● project:可以随意定义,跟爬虫的工程名字无关,一般建议与scrapy爬虫项目名相同
● version:自定义版本号,不写的话默认为当前时间戳,一般不写
scrapyd-deploy ubuntu-1 -p dangdang_book
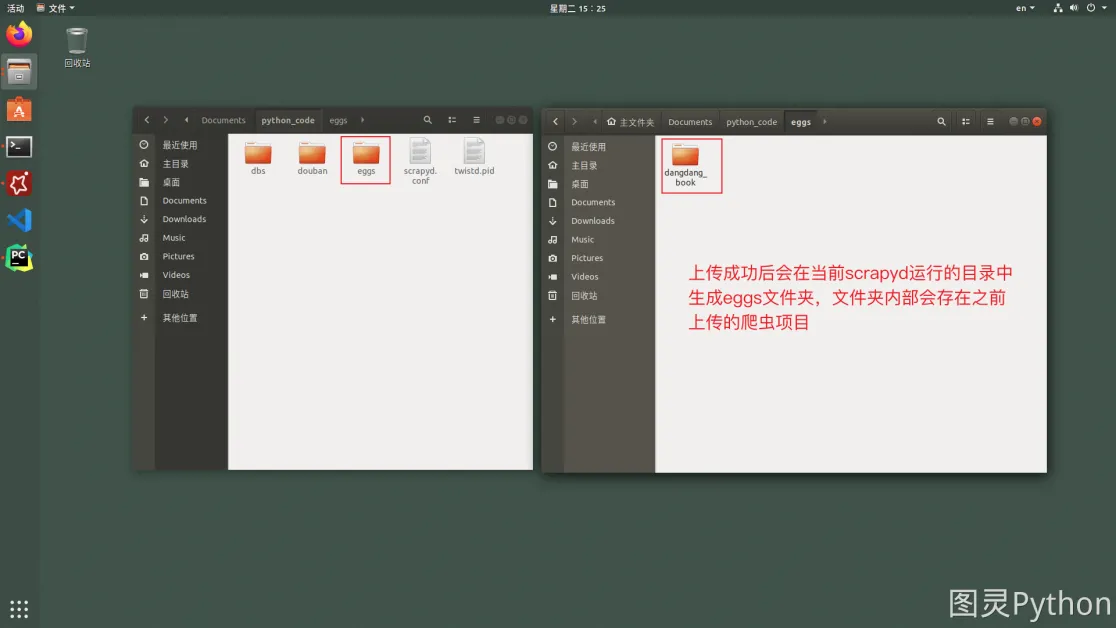
爬虫目录下不要放无关的py文件,放无关的py文件会导致发布失败。当爬虫发布成功后,会在当前目录生成一个setup.py文件,可以删除掉。
发布成功后可以在服务端查看到上传的爬虫项目,效果如下:
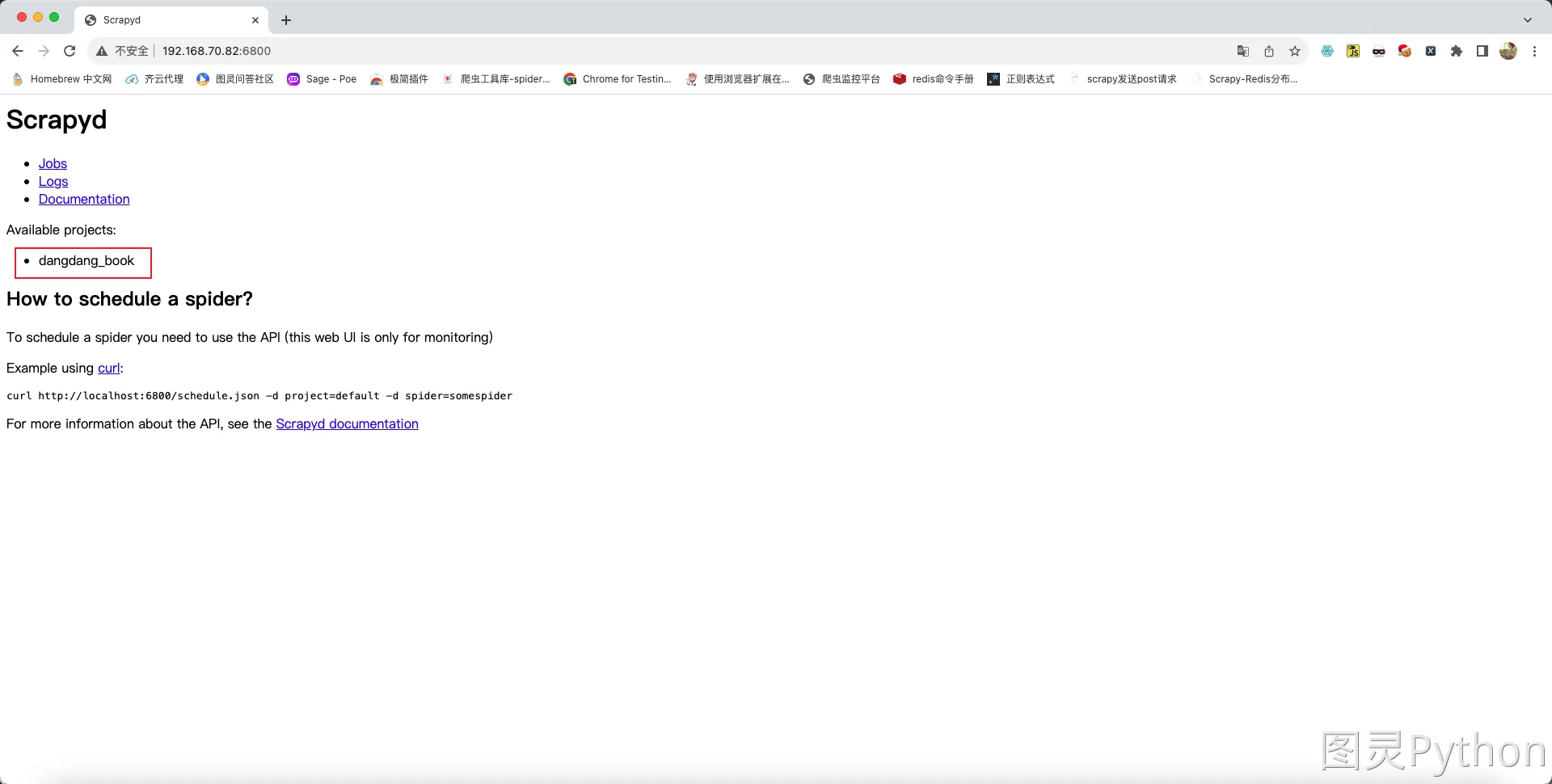
- 刷新物理机上的浏览器则显示上传成功后的
scrapy项目,效果如下:
4. 启动部署服务器代码
scrapyd已经给出了怎样开始运行爬虫,如下图所示:
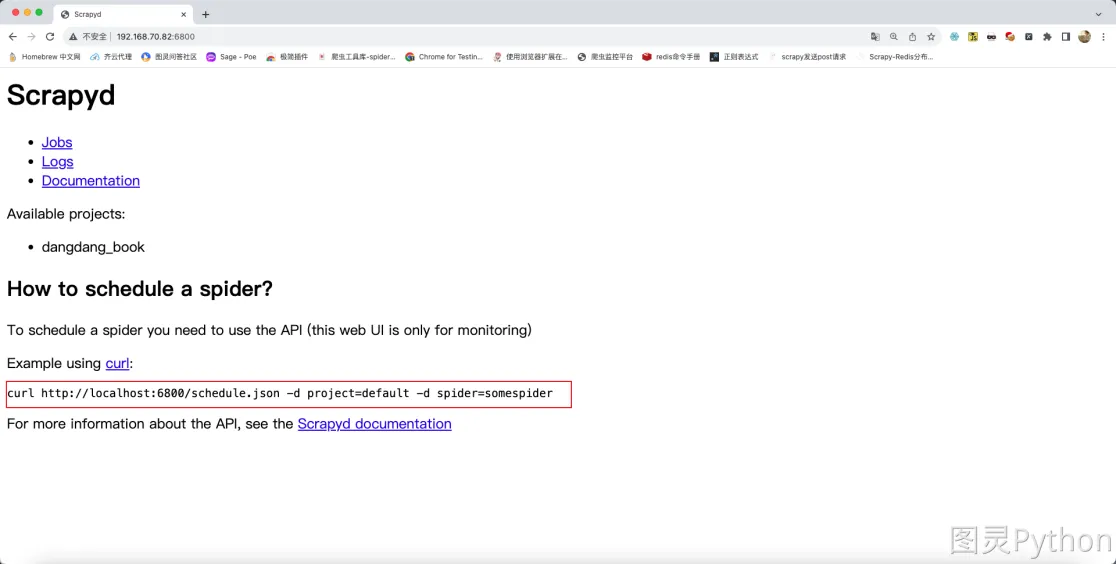
- 将上述的命令复制,之后在终端中进行适当的修改即可开启爬虫,命令如下
curl http://192.168.70.82:6800/schedule.json -d project=dangdang_book -d spider=book
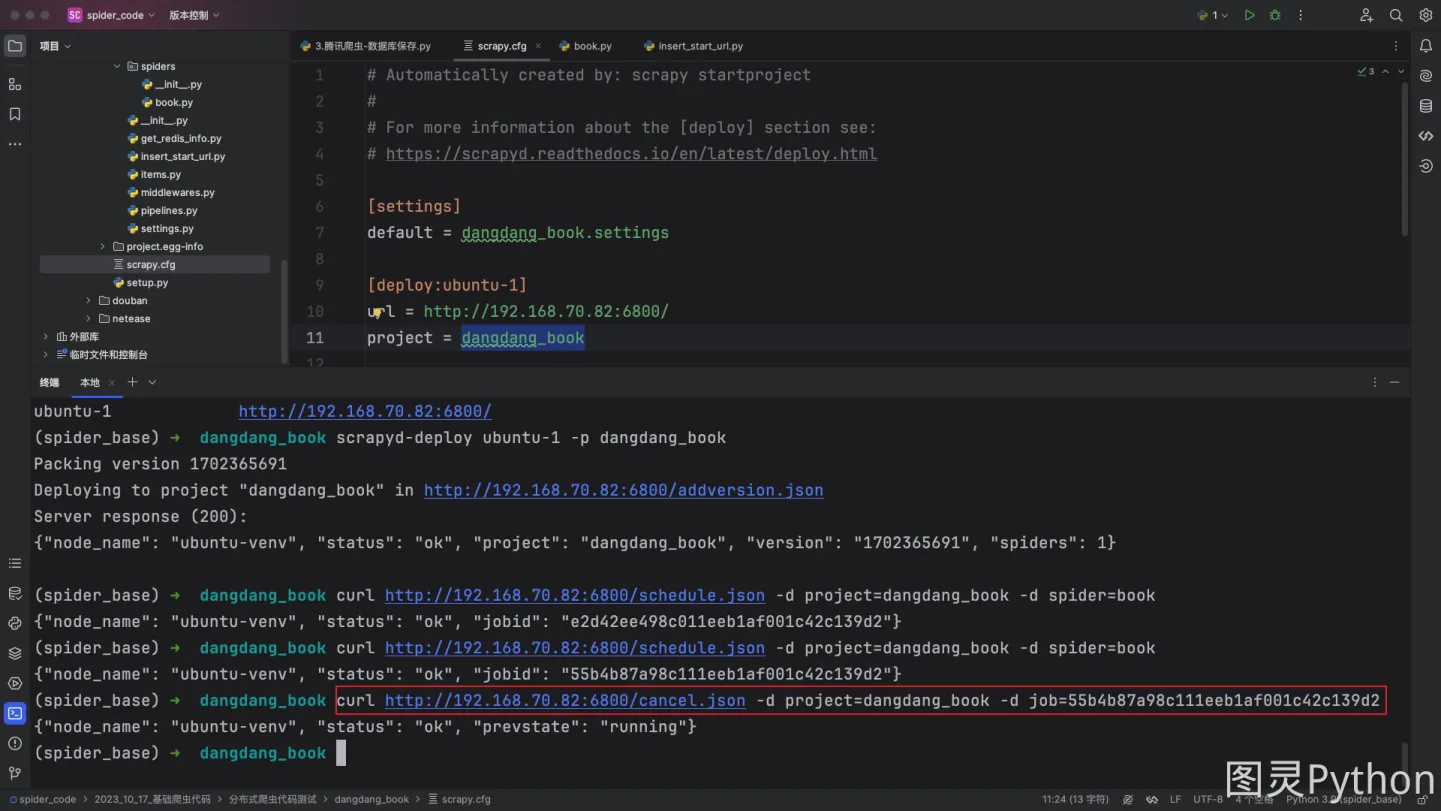
5. 停止爬虫
- 停止爬虫的指令如下:
curl http://ip:6800/cancel.json -d project=项目名 -d job=任务的id值
- 任务的
id值可在浏览器中查询:
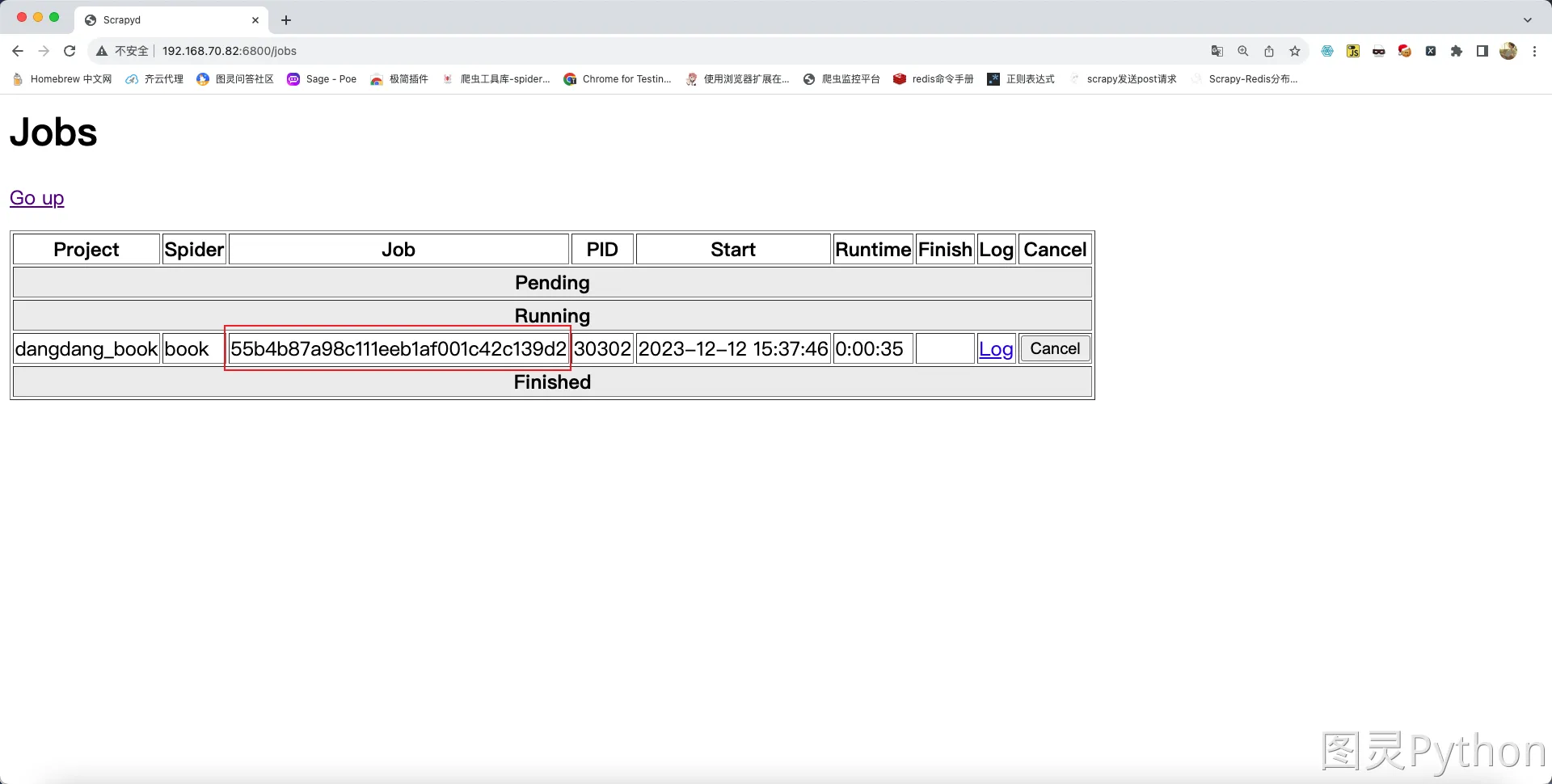
- 根据页面中显示的
id编辑指令:
curl http://192.168.70.82:6800/cancel.json -d project=dangdang_book -d job=55b4b87a98c111eeb1af001c42c139d2
五. 项目部署 - scrapyweb
1. 简介
scrapyweb是一个基于scrapyd的可视化组件,集成并且提供更多可视化功能和更优美的界面。scrapydweb后端是采用flask框架编写的,所以对于会flask的同学是可以适当定制的。- 安装方式
pip install scrapydweb -i https://pypi.tuna.tsinghua.edu.cn/simple
2. 运行指令
在运行
scrapydweb之前一定要确保scrapyd正在运行,可以在scrapyd服务启动之后重新创建一个新终端窗口来启动scrapydweb。
scrapyd
scrapydweb
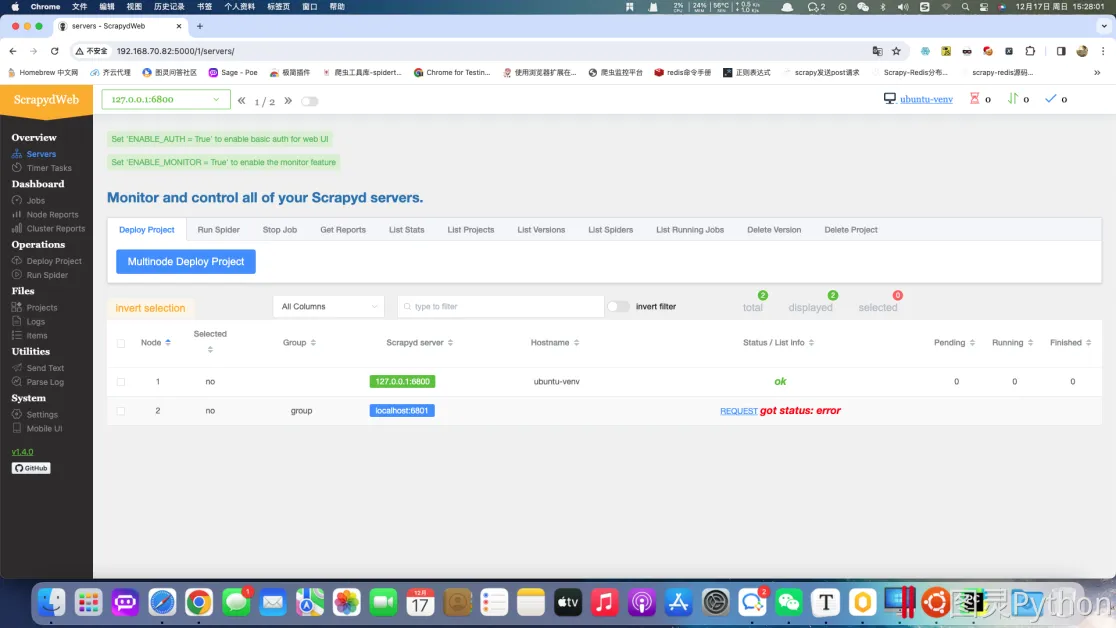
scrapydweb项目地址:https://github.com/my8100/scrapydweb?tab=readme-ov-filescrapydweb第一次启动会报错,报错之后重新启动即可,重新启动后会在启动路径的位置生成脚本文件。如果重新启动失败并抛出版本依赖问题请查看项目地址中的requirements.txt文件并安装最新依赖。- 当成功启动后可使用物理机浏览器访问地址:http://192.168.70.82:5000/
- 显示如下:
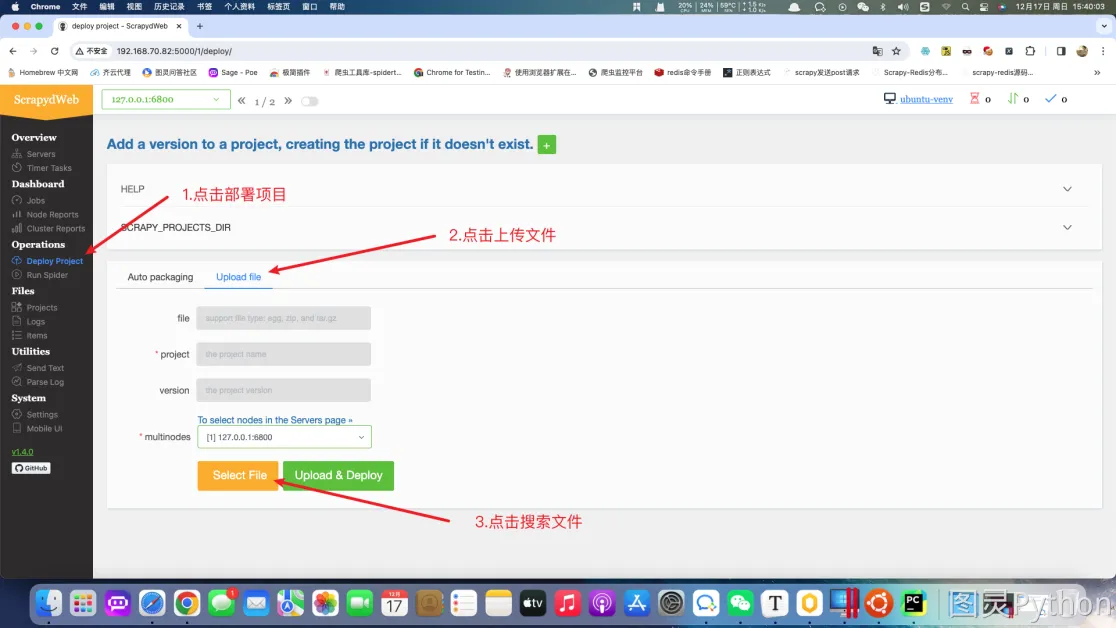
3. 可视化界面部署
-
发布
scrapy项目
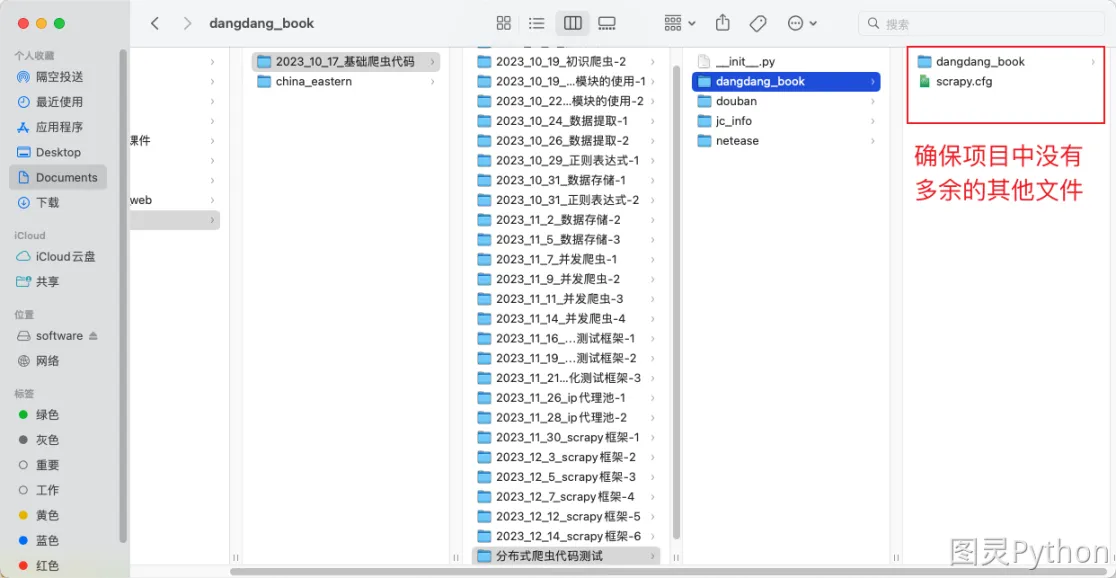
- 在计算机中搜索需要部署的项目,项目可以打包成压缩包,在打包压缩包之前需要确认项目中只有
scrapy框架代码。
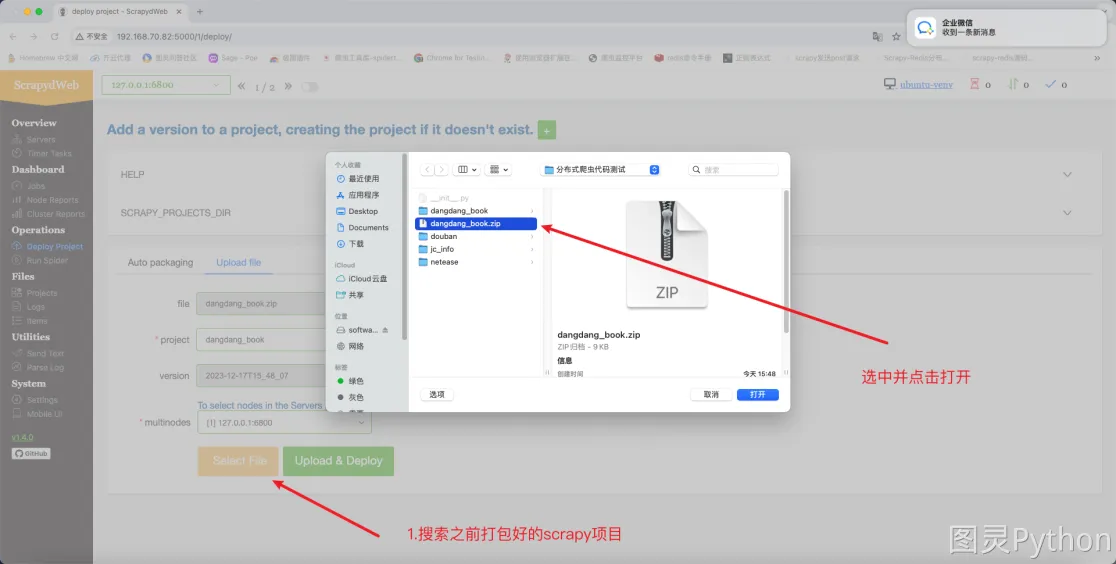
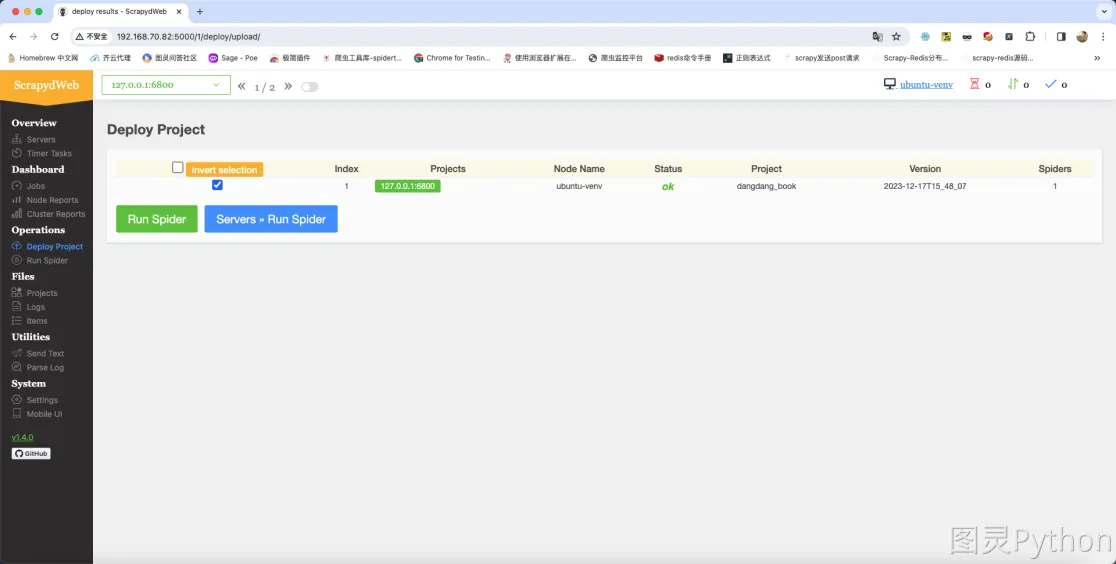
- 项目上传成功后的效果如下:
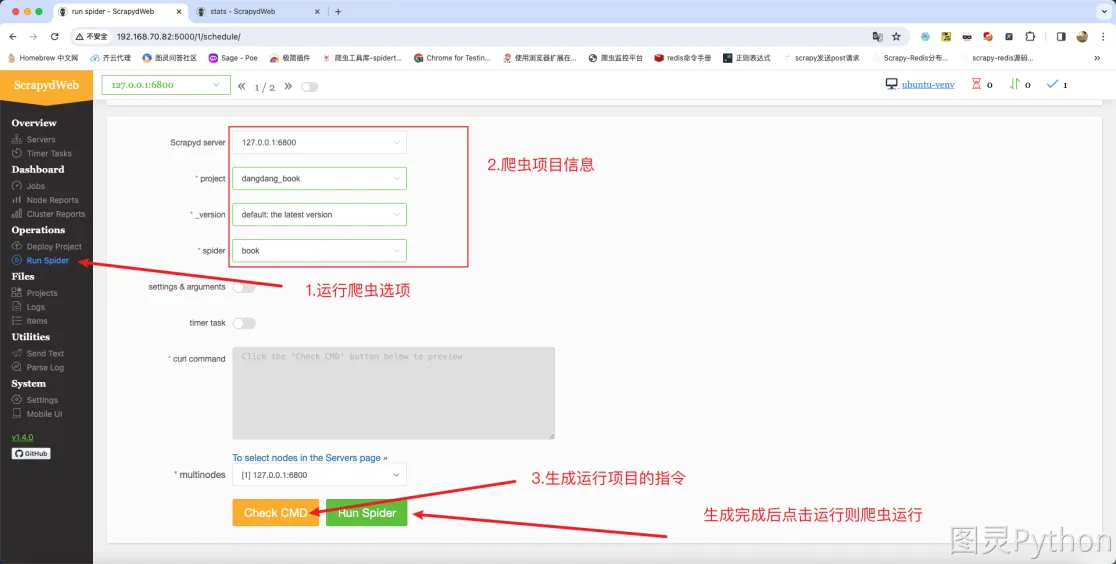
- 项目运行:
阅读建议

评论
匿名评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果
最近发布