
11-scrapy-redis学习
scrapy-redis组件学习
学习目标
- 了解 scarpy_redis的概念和功能
- 了解 scrapy_redis的原理
- 了解 redis数据库操作命令
在前面scrapy框架中我们已经能够使用框架实现爬虫爬取网站数据,如果当前网站的数据比较庞大, 我们就需要使用分布式来更快的爬取数据
1、scrapy_redis是什么
Scrapy_redis : Redis-based components for Scrapy.
Github地址:https://github.com/rmax/scrapy-redis
在这个地址中存在三个demo,后续我们对scrapy_redis的学习会通过这三个demo展开
安装方式:pip install scrapy-redis
2、为什么要学习scrapy_redis
Scrapy_redis在scrapy的基础上实现了更多,更强大的功能,具体体现在:
- 请求对象的持久化
- 去重的持久化
- 和实现分布式
3、scrapy_redis的原理分析
3.1 回顾scrapy的流程
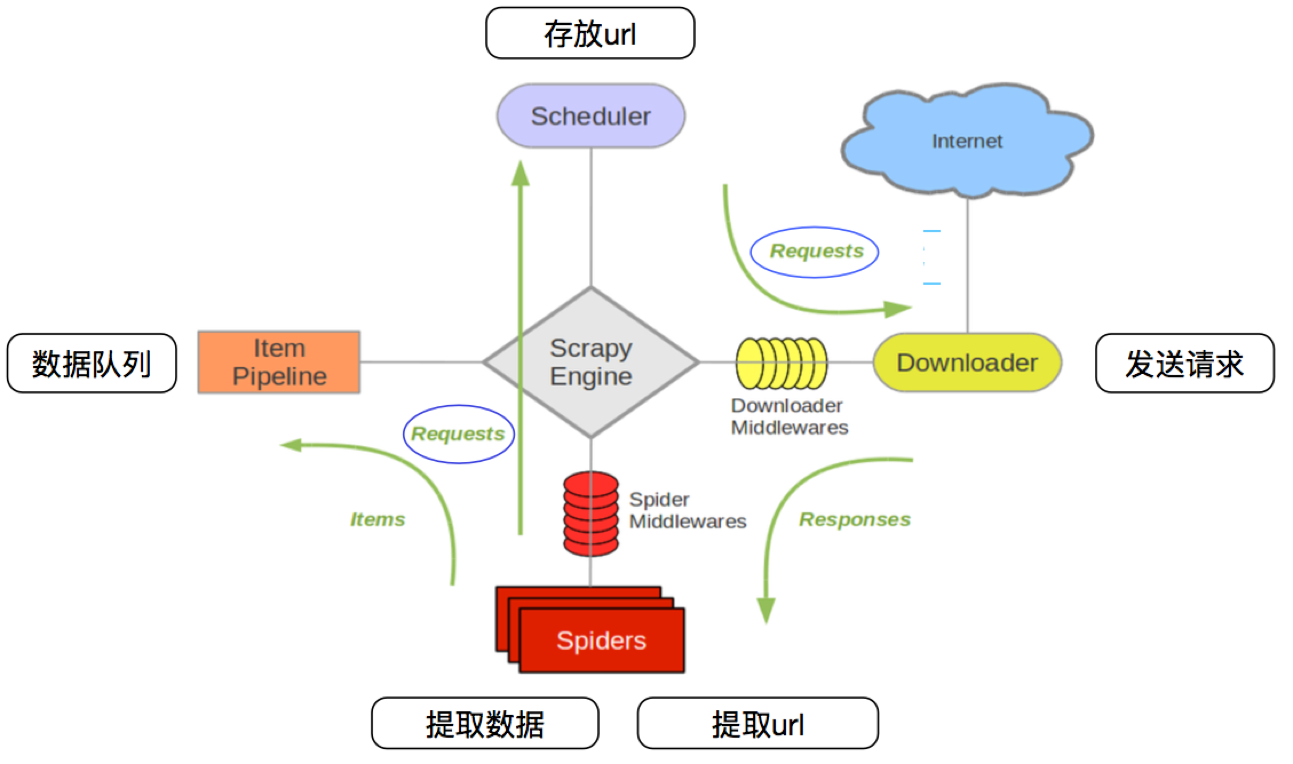
- 那么,在这个单机架构基础上,如果需要实现分布式,即多台服务器同时完成一个爬虫,需要怎么做呢?
- 在单机架构的基础上都是通过scheduler的队列来进行任务的调度
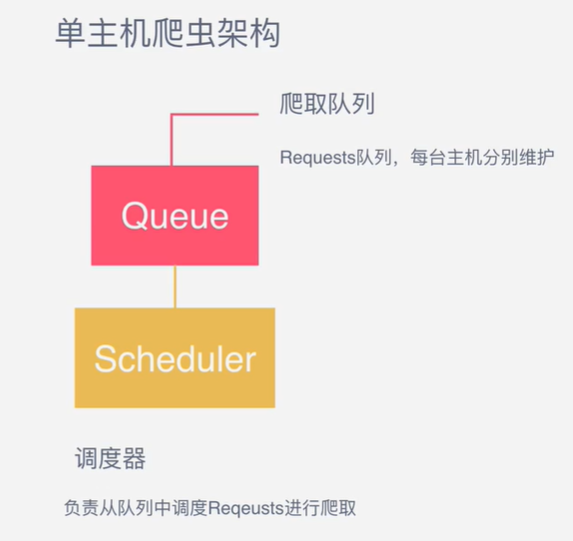
- 那么要是想实现分布式的方式就需要开多个调度器,从队列里进行获取request请求对象,主机负责分配对应的request任务,那这个主机一般都是一个单独存在的机器,丛机是负责任务的下载和保存,也就是说丛机都找主机队列去获取请求,其他的保持一致
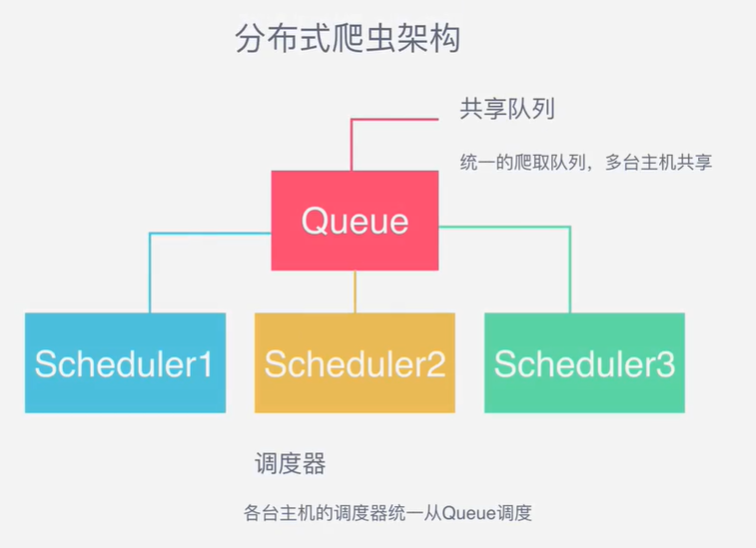
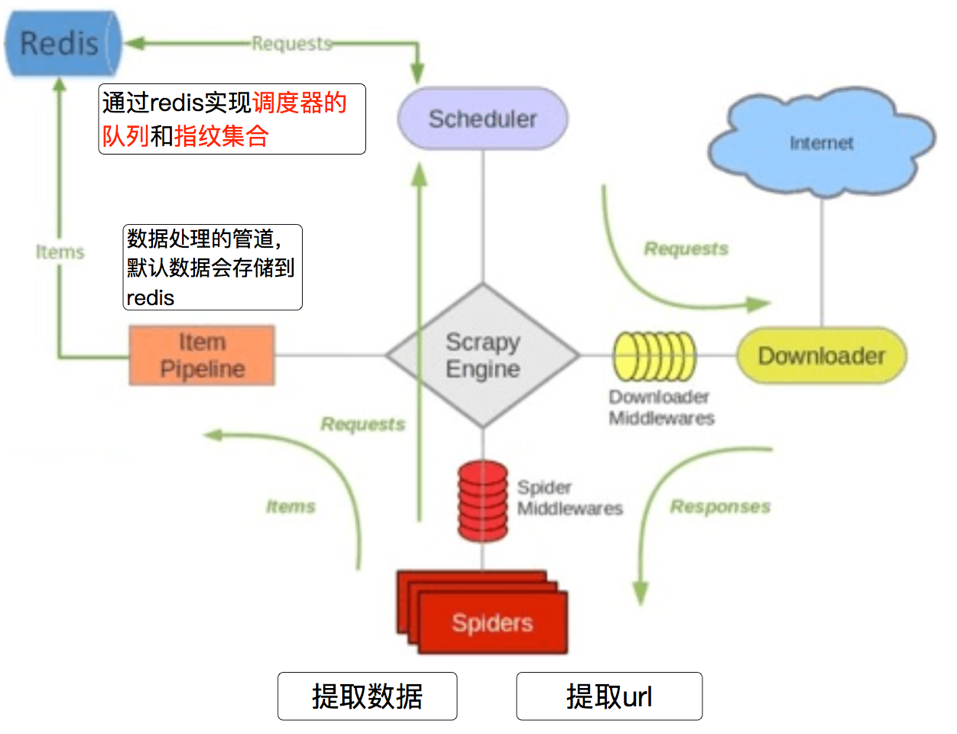
3.2 scrapy_redis的流程
- 在scrapy_redis中,所有的带抓取的对象和去重的指纹都存在所有的服务器公用的redis中
- 所有的服务器公用一个redis中的request对象
- 所有的request对象存入redis前,都会在同一个redis中进行判断,之前是否已经存入过
- 在默认情况下所有的数据会保存在redis中
具体流程如下:
4、对于redis的复习
由于时间关系,大家对redis的命令遗忘的差不多了, 但是在scrapy_redis中需要使用redis的操作命令,所有需要回顾下redis的命令操作
4.1 redis是什么
redis是一个开源的内存型数据库,支持多种数据类型和结构,比如列表、集合、有序集合等,同时可以使用redis-manger-desktop等客户端软件查看redis中的数据,关于redis-manger-desktop的使用可以参考扩展阅读
4.2 redis配置
默认情况下,Redis服务值运行本地电脑访问,即Redis运行在哪台电脑就只允许这台电脑上的软件连接试用它
既然我们要做分布式爬取,就意味着别的电脑也需要访问Redis,因此需要对Redis进行配置
配置参考地址:https://www.cnblogs.com/masonblog/p/12726914.html
- 别忘了修改爬虫的配置文件
settings.py,将Redis服务器地址改为你运行Redis的服务器的ip - 服务器安装:https://blog.csdn.net/m0_60028455/article/details/125316625
4.3 redis服务端和客户端的启动
/etc/init.d/redis-server start启动服务端redis-cli -h -p <端口号>客户端启动
4.4 redis中的常见命令
select 1切换dbkeys *查看所有的键type 键查看键的类型flushdb清空dbflushall清空数据库lrange 键 0 -1查看列表数据
4.5 redis命令的复习
redis的命令很多,这里我们简单复习后续会使用的命令

5、scrapy-redis的核心组件
1. Scheduler(调度):
scrapy改造了python本来的collection.deque(双向队列)形成了自己scrapy queue,而scrapy-redis 的解决是把这个scrapy queue换成redis数据库,从同一个redis-server存放要爬取的request,便能让多个spider去同一个数据库里读取。
Scrapy中跟“待爬队列”直接相关的就是调度器Scheduler,它负责对新的request进行入列操作(加入Scrapy queue),取出下一个要爬取的request(从Scrapy queue中取出)等操作。它把待爬队列按照优先级建立了一个字典结构,比如:
{
优先级0 : 队列0
优先级1 : 队列1
优先级2 : 队列2
}
然后根据request中的优先级,来决定该入哪个队列,出列时则按优先级较小的优先出列。为了管理这个比较高级的队列字典,Scheduler需要提供一系列的方法。但是原来的Scheduler已经无法使用,所以使用Scrapy-redis的scheduler组件。
2. Duplication Filter(去重):
Scrapy中用集合实现这个request去重功能,Scrapy中把已经发送的request指纹放入到一个集合中,把下一个request的指纹拿到集合中比对,如果该指纹存在于集合中,说明这个request发送过了,如果没有则继续操作。这个核心的判重功能是这样实现的:
def request_seen(self, request):
# self.request_figerprints就是一个指纹集合
fp = self.request_fingerprint(request)
# 这就是判重的核心操作
if fp in self.fingerprints:
return True
self.fingerprints.add(fp)
if self.file:
self.file.write(fp + os.linesep)
在scrapy-redis中去重是由Duplication Filter组件来实现的,它通过redis的set 不重复的特性,巧妙的实现了Duplication Filter去重。scrapy-redis调度器从引擎接受request,将request的指纹存⼊redis的set检查是否重复,并将不重复的request push写⼊redis的 request queue。
引擎请求request(Spider发出的)时,调度器从redis的request queue队列⾥里根据优先级pop 出⼀个request 返回给引擎,引擎将此request发给spider处理。
3. Item Pipline(管道):
引擎将(Spider返回的)爬取到的Item给Item Pipeline,scrapy-redis 的Item Pipeline将爬取到的 Item 存⼊redis的 items queue。
修改过Item Pipeline可以很方便的根据key从items queue提取item,从而实现 items processes集群。
4. Base Spider(爬虫):
不再使用scrapy原有的Spider类,重写的RedisSpider继承了Spider和RedisMixin这两个类,RedisMixin是用来从redis读取url的类。
当我们生成一个Spider继承RedisSpider时,调用setup_redis函数,这个函数会去连接redis数据库,然后会设置signals(信号):
- 一个是当spider空闲时候的signal,会调用spider_idle函数,这个函数调用
schedule_next_request函数,保证spider是一直活着的状态,并且抛出DontCloseSpider异常。 - 一个是当抓到一个item时的signal,会调用item_scraped函数,这个函数会调用
schedule_next_request函数,获取下一个request。
6、scrapy-redis的核心配置
首先最主要的是,需要将调度器的类和去重的类替换为 Scrapy-Redis 提供的类,在 settings.py 里面添加如下配置即可:
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 布隆过滤器
# pip install scrapy-redis-bloomfilter
DUPEFILTER_CLASS = "scrapy_redis_bloomfilter.dupefilter.RFPDupeFilter"
直接在 settings.py 里面配置为 REDIS_URL 变量即可:
redis://[:password]@host:port/db
REDIS_URL = 'redis://172.25.197.89:6379/0'
6.1配置调度队列
此项配置是可选的,默认使用 PriorityQueue。如果想要更改配置,可以配置 SCHEDULER_QUEUE_CLASS 变量,如下所示:
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue' # 使用有序集合来存储
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.FifoQueue' # 先进先出
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.LifoQueue' # 先进后出、后进先出
6.2 配置redis-item
此配置可自行选择,想存放在redis可以放开
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline' : 400,
}
6.3 爬虫文件配置
修改爬虫 的继承类,给上对应的redis键名
from scrapy_redis.spiders import RedisSpider
class DoubanSpider(RedisSpider):
# 爬虫的名字
name = 'douban'
# redis的键名
redis_key = 'douban:start'
6.4 配置持久化
此配置是可选的,默认是 False。Scrapy-Redis 默认会在爬取全部完成后清空爬取队列和去重指纹集合。初始第一个网址一定会进行请求,后面的重复方式不会进行请求。
如果不想自动清空爬取队列和去重指纹集合,可以增加如下配置:
SCHEDULER_PERSIST = True # 底层 就是监听爬虫信号 触发redis指令 清空数据库
# SCHEDULER_PERSIST 控制爬虫是否在关闭时保持状态,True 不清空数据
6.5 配置重爬
此配置是可选的,默认是 False。如果配置了持久化或者强制中断了爬虫,那么爬取队列和指纹集合不会被清空,爬虫重新启动之后就会接着上次爬取。如果想重新爬取,我们可以配置重爬的选项
SCHEDULER_FLUSH_ON_START = True
# SCHEDULER_FLUSH_ON_START 控制是否在启动时清空请求队列,设置为 True 之后,爬虫每次启动时,爬取队列和指纹集合都会清空。
这样将 SCHEDULER_FLUSH_ON_START 设置为 True 之后,爬虫每次启动时,爬取队列和指纹集合都会清空。所以要做分布式爬取,我们必须保证只能清空一次,否则每个爬虫任务在启动时都清空一次,就会把之前的爬取队列清空,势必会影响分布式爬取。
如果你需要在每次启动时都重新开始爬取,可以将两者都设置为 False。如果需要断点续爬,可以将 SCHEDULER_FLUSH_ON_START 设置为 False,并将 SCHEDULER_PERSIST 设置为 True。
7、项目实战
7.1 项目分析
目标网址:http://search.dangdang.com/?key=Python&act=input
采集需求: 采集目标标题,价格,作者,上线时间, 介绍详情,出版社
7.2 创建项目
# 创建项目
scrapy startproject dd_project
# 创建爬虫
scrapy genspider dd_spider
7.3 爬虫文件
import scrapy
from scrapy_redis.spiders import RedisSpider
from DD.items import DdItem
class DangdangSpider(RedisSpider):
# 爬虫名称
name = "dangdang"
# allowed_domains = ["search.dangdang.com"]
# start_urls = ["http://search.dangdang.com/"]
# redis键名称
redis_key = 'dd:start'
def parse(self, response, **kwargs):
li_list = response.xpath('//ul[@class="bigimg"]/li')
for li in li_list:
item = DdItem()
item['title'] = li.xpath('./a/@title').extract_first()
item['price'] = li.xpath('./p[@class="price"]/span[1]/text()').extract_first()
item['author'] = li.xpath('./p[@class="search_book_author"]/span[1]/a[1]/@title').extract_first()
item['date_data'] = li.xpath('./p[@class="search_book_author"]/span[last()-1]/text()').extract_first()
item['detail'] = li.xpath('./p[@class="detail"]/text()').extract_first() if li.xpath(
'./p[@class="detail"]/text()') else '空'
item['producer'] = li.xpath(
'./p[@class="search_book_author"]/span[last()]/a/text()').extract_first() if li.xpath(
'./p[@class="search_book_author"]/span[last()]/a/text()') else '空'
print(item)
yield item
if response.xpath('//ul[@name="Fy"]/li[@class="next"]/a/@href').extract_first() != None:
next_url = response.urljoin(response.xpath('//ul[@name="Fy"]/li[@class="next"]/a/@href').extract_first())
yield scrapy.Request(url=next_url, callback=self.parse)
if __name__ == '__main__':
from scrapy import cmdline
cmdline.execute('scrapy crawl dangdang'.split())
7.4 item文件
import scrapy
class DdItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
price = scrapy.Field()
author = scrapy.Field()
date_data = scrapy.Field()
detail = scrapy.Field()
producer = scrapy.Field()
7.5 管道文件
import pymysql
class DdMySQLPipeline:
def open_spider(self, spider):
# 判断是哪个爬虫 名字不同可能执行的爬虫项目也不同
if spider.name == 'dangdang':
self.db = pymysql.connect(host="localhost", user="root", password="root", db="spiders")
self.cursor = self.db.cursor()
# 创建变语法
sql = '''
CREATE TABLE IF NOT EXISTS dangdang(
id int primary key auto_increment not null,
title VARCHAR(255) NOT NULL,
price VARCHAR(255) NOT NULL,
author VARCHAR(255) NOT NULL,
date_data VARCHAR(255) NOT NULL,
detail TEXT,
producer VARCHAR(255) NOT NULL)
'''
try:
self.cursor.execute(sql)
print("CREATE TABLE SUCCESS.")
except Exception as ex:
print(f"CREATE TABLE FAILED,CASE:{ex}")
def process_item(self, item, spider):
# SQL 插入语句
sql = 'INSERT INTO dangdang(id, title, price, author, date_data, detail, producer) values(%s, %s, %s, %s, %s, %s, %s)'
# 执行 SQL 语句
try:
self.cursor.execute(sql, (0, item['title'], item['price'], item['author'], item['date_data'], item['detail'], item['producer']))
# 提交到数据库执行
self.db.commit()
print('mysql数据插入成功...')
except Exception as e:
print(f'数据插入失败: {e}')
# 如果发生错误就回滚
self.db.rollback()
# 不return的情况下,另一个权重较低的pipeline将不会获得item,否则后一个pipeline取到的数据为None值
return item
def close_spider(self, spider): # 在爬虫关闭的时候仅执行一次
# 关闭文件
if spider.name == 'dangdang':
self.db.close()
7.6 设置文件
# 持久化配置
SCHEDULER_PERSIST = True
# 使用scrapy-redis调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# scrapy-redis指纹过滤器
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# redis链接地址
REDIS_URL = 'redis://127.0.0.1:6379/0'
# 任务的优先级别
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue'
# 存放的管道
ITEM_PIPELINES = {
"scrapy_redis.pipelines.RedisPipeline": 300,
'dd_project.pipelines.DdMySQLPipeline': 301,
}
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36'
}
7.7 分配任务
import redis
import json
res = redis.Redis()
res.lpush('dd:start', 'http://search.dangdang.com/?key=python&act=input&page_index=1')
# res.lpush('dd:start', 'http://search.dangdang.com/?key=java&act=input&page_index=1')
# res.lpush('dd:start', 'http://search.dangdang.com/?key=go&act=input&page_index=1')
# for i in res.lrange('dangdang:items', 0, -1):
# print(json.loads(i))
8、scrapy-redis发送post请求
- 在当前案例中我们需要掌握如何使用
scrapy-redis发送post请求并完成翻页。 - 站点请求地址:http://www.cninfo.com.cn/new/commonUrl?url=disclosure/list/notice#szse
import json
from scrapy import cmdline
from scrapy.http import FormRequest
from scrapy_redis.spiders import RedisSpider
class JcSpider(RedisSpider):
name = "jc"
allowed_domains = ["www.cninfo.com.cn"]
# start_urls = ["http://www.cninfo.com.cn/"]
redis_key = 'jc:start_urls'
def make_request_from_data(self, data):
url = 'http://www.cninfo.com.cn/new/disclosure'
"""
:param data: 是scrapy-redis读取redis中的[url, form_data, meta]
:return:
"""
data = json.loads(data)
form_data = data.get('form_data')
print('12323', form_data)
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
return FormRequest(url=url, headers=headers, formdata=form_data, callback=self.parse)
def parse(self, response, **kwargs):
print('返回信息:', response.json())
if __name__ == '__main__':
cmdline.execute('scrapy crawl jc'.split())
- redis提交数据代码
import json
import redis
def push_start_url_data(db, request_obj):
"""
:param db: redis链接对象
:param request_obj: {'url':url, 'form_data':form_data, 'meta':meta}
:return:
"""
db.lpush('jc:start_urls', request_obj)
if __name__ == '__main__':
redis_client = redis.Redis()
# 需要将表单中的数字类型强转为字符串类型
for page in range(1, 26):
form_data = {
'column': 'szse_latest',
'pageNum': str(page),
'pageSize': '30',
'sortName': '',
'sortType': '',
'clusterFlag': 'true'
}
request_data = {
'form_data': form_data
}
push_start_url_data(redis_client, json.dumps(request_data))
redis_client.close()
- 配置文件
"""scrapy-redis配置"""
# 调度器类
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 指纹去重类
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 是否在关闭时候保留原来的调度器和去重记录,True=保留,False=清空
SCHEDULER_PERSIST = True
# Redis服务器地址
REDIS_URL = "redis://127.0.0.1:6379/0"
