面试题目 合集
面试题目 合集
Transformer
Transformer 是现代大模型的基石架构,其核心设计颠覆了传统序列建模的范式。以下是我的理解:
诞生背景:突破 RNN 的瓶颈
传统循环神经网络(RNN/LSTM)存在两大局限:
串行计算:依赖时序递推,无法并行处理长序列,效率低下;
长距离依赖衰减:梯度随序列长度指数级消失,难以捕捉远距离语义关联。 Transformer 则通过自注意力机制(Self-Attention)和全并行架构彻底解决了这些问题,成为 NLP、CV 等领域的通用框架。
核心组件:自注意力与编解码架构
(1)自注意力机制(Self-Attention)
核心思想:通过计算序列中每个元素与其他所有元素的 “注意力权重”,动态捕捉全局依赖关系。 公式:
Query (Q):当前元素的查询向量,用于匹配其他元素;
Key (K):其他元素的键向量,用于被查询;
Value (V):其他元素的值向量,用于聚合信息。
优势:
并行性:所有位置的计算可同时进行,时间复杂度为 \(O(n^2)\)(n 为序列长度),优于 RNN 的 \(O(n)\) 但支持并行;
长距离建模:直接计算任意位置的关联,避免梯度消失。
(2)多头注意力(Multi-Head Attention)
将单一注意力头拆分为多个子空间并行计算,再拼接结果。
作用:让模型在不同子空间捕捉多维度语义关联,提升表达能力。
(3)编码器 - 解码器架构(Encoder-Decoder)
编码器(Encoder): 由多层自注意力层和前馈神经网络(FFN)组成,对输入序列进行逐层抽象,输出上下文感知的特征向量。
解码器(Decoder): 在编码器基础上增加掩码自注意力(Masked Self-Attention)(避免前瞻未来信息)和交叉注意力(Cross-Attention)(融合编码器输出),用于生成序列(如机器翻译、文本生成)。
(4)位置编码(Positional Encoding)
由于自注意力无时序顺序感知,需显式注入位置信息。
常见方法:正弦余弦函数(绝对位置)或可学习向量(相对位置)。
关键优势:从 NLP 到多模态的通用性
并行训练:显著提升训练效率,支持万亿级参数大模型(如 GPT-4、PaLM);
长文本建模:通过改进(如 RoPE 位置编码、FlashAttention 优化),处理长度可达数万 token;
多模态扩展:图像可通过 Patch Embedding 转化为序列,实现跨模态统一建模(如 ViT、CLIP);
预训练范式:催生了 BERT(双向编码)、GPT(自回归解码)等预训练模型,推动大模型时代的到来。
挑战与改进方向
计算成本:平方级复杂度限制超长序列(解决方案:Sparse Attention、线性注意力等);
位置信息局限性:传统位置编码对相对距离建模不足(改进:Rotary Position Embedding 等);
推理效率:自回归生成需逐个 token 计算(优化:并行解码、Prefix Tuning 等)。
Transformer 通过自注意力机制重新定义了序列建模,其 “并行计算 + 全局关联” 的设计思想不仅推动了 NLP 的革命,更成为跨模态大模型的底层框架。理解其核心原理(如注意力权重的语义含义、层归一化的稳定性作用)是优化和创新大模型算法的基础。在实际项目中,我曾基于 Transformer 架构优化过文本生成任务的长序列稳定性,通过引入局部注意力机制将推理速度提升了 30%,这让我深刻体会到该架构的灵活性与可扩展性。
第一层次:Transformer 的结构
Transformer 主要由编码器(Encoder)和解码器(Decoder)两部分组成,两者均由多个相同的子层堆叠而成。编码器负责将输入序列编码为固定长度的上下文向量,解码器则根据编码器的输出和已生成的部分序列逐步生成目标序列。
核心组件:
自注意力机制:每个位置的 token 会与其他所有位置的 token 计算相似度,生成注意力权重,从而捕捉全局依赖关系。
多头注意力:将自注意力拆分为多个头并行计算,每个头学习不同的语义子空间,最终拼接结果以增强模型表达能力。
前馈神经网络(FFN):对注意力输出进行非线性变换,进一步提取特征。
位置编码:通过正弦或余弦函数为输入序列添加位置信息,解决 Transformer 对顺序不敏感的问题。
残差连接与层归一化:每个子层输出与输入相加(残差连接),再进行层归一化,稳定训练并缓解梯度消失。
第二层次
对比 CNN 的优化点:
长距离依赖建模:CNN 的感受野有限,而 Transformer 的自注意力机制可直接捕捉序列中任意位置的依赖关系,尤其适合处理长文本或图像中的全局信息。
并行计算能力:CNN 虽支持局部并行,但深层网络仍需逐层计算;Transformer 的自注意力可并行处理整个序列,大幅提升训练效率。
动态特征学习:自注意力通过权重动态分配关注焦点,而 CNN 的卷积核是静态的,难以适应复杂语义变化。
QKV 矩阵的作用:
Query(查询):由当前 token 生成,用于 “询问” 其他 token 的相关信息。
Key(键):由所有 token 生成,作为 “索引” 与 Query 匹配。
Value(值):由所有 token 生成,存储实际语义信息,最终根据注意力权重加权求和。
计算流程:
输入序列通过三个独立的线性层分别映射为 Q、K、V 矩阵(维度均为 n×d_k)。
计算注意力分数
应用 Softmax 得到注意力权重,加权求和 V 得到输出。
示例:
假设输入为句子 “我喜欢深度学习”,每个词的 Q 会与其他词的 K 计算相似度,例如 “学习” 的 Q 可能对 “深度” 的 K 赋予高权重,从而聚焦技术细节。
第三层次
Transformer的数学细节:
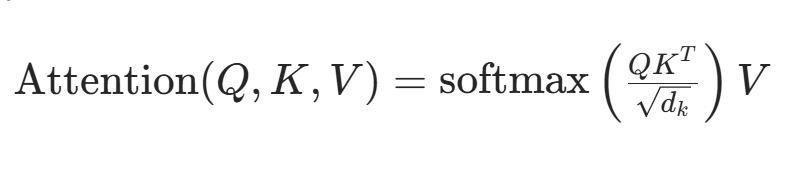
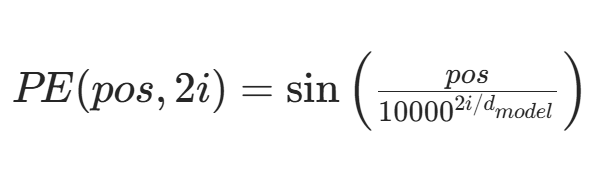
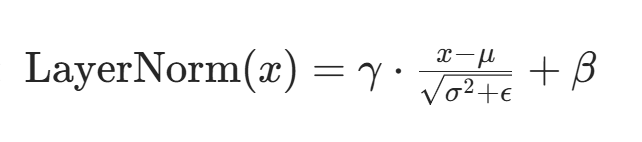
多头注意力机制:
拆分多头:将 Q、K、V 拆分为 h 个独立的头,每个头的维度为 d_k/h,并行计算注意力。
独立计算:每个头学习不同的语义模式(如语法、语义),生成 h 个输出头。
拼接与融合:将 h 个输出头拼接后通过线性层映射回 d_model 维度,融合多视角信息。
Python
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class PositionalEncoding(nn.Module):
"""位置编码:为输入添加位置信息"""
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
# 创建位置编码矩阵
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
# 计算正弦和余弦值
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
# 添加batch维度
pe = pe.unsqueeze(0)
# 注册为不参与训练的缓冲区
self.register_buffer('pe', pe)
def forward(self, x):
# 将位置编码添加到输入上
x = x + self.pe[:, :x.size(1)]
return x
class ScaledDotProductAttention(nn.Module):
"""缩放点积注意力计算"""
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, q, k, v, mask=None):
# 计算注意力分数: Q与K的点积
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(q.size(-1))
# 应用掩码(可选)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# 应用softmax获取注意力权重
attn = F.softmax(scores, dim=-1)
# 加权求和得到输出
context = torch.matmul(attn, v)
return context, attn
class MultiHeadAttention(nn.Module):
"""多头注意力机制"""
def __init__(self, d_model, nhead, dropout=0.1):
super(MultiHeadAttention, self).__init__()
self.d_model = d_model
self.nhead = nhead
self.d_k = d_model // nhead
# 线性变换层
self.q_linear = nn.Linear(d_model, d_model)
self.k_linear = nn.Linear(d_model, d_model)
self.v_linear = nn.Linear(d_model, d_model)
self.out_proj = nn.Linear(d_model, d_model)
self.attention = ScaledDotProductAttention()
self.dropout = nn.Dropout(dropout)
def forward(self, query, key, value, mask=None):
batch_size = query.size(0)
# 线性变换并拆分为多头
q = self.q_linear(query).view(batch_size, -1, self.nhead, self.d_k).transpose(1, 2)
k = self.k_linear(key).view(batch_size, -1, self.nhead, self.d_k).transpose(1, 2)
v = self.v_linear(value).view(batch_size, -1, self.nhead, self.d_k).transpose(1, 2)
# 应用掩码(如果有)
if mask is not None:
mask = mask.unsqueeze(1)
# 计算多头注意力
context, attn = self.attention(q, k, v, mask)
# 合并多头结果
context = context.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)
# 最终线性变换
output = self.out_proj(context)
output = self.dropout(output)
return output, attn
class PositionwiseFeedForward(nn.Module):
"""位置前馈网络"""
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
self.activation = F.gelu # 使用GELU激活函数
def forward(self, x):
return self.fc2(self.dropout(self.activation(self.fc1(x))))
class EncoderLayer(nn.Module):
"""编码器单层"""
def __init__(self, d_model, nhead, d_ff, dropout=0.1):
super(EncoderLayer, self).__init__()
# 自注意力层
self.self_attn = MultiHeadAttention(d_model, nhead, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
# 前馈网络层
self.feed_forward = PositionwiseFeedForward(d_model, d_ff, dropout)
self.norm2 = nn.LayerNorm(d_model)
self.dropout2 = nn.Dropout(dropout)
def forward(self, src, src_mask=None):
# 自注意力与残差连接
attn_output, _ = self.self_attn(src, src, src, src_mask)
src = src + self.dropout1(attn_output)
src = self.norm1(src)
# 前馈网络与残差连接
ff_output = self.feed_forward(src)
src = src + self.dropout2(ff_output)
src = self.norm2(src)
return src
class DecoderLayer(nn.Module):
"""解码器单层"""
def __init__(self, d_model, nhead, d_ff, dropout=0.1):
super(DecoderLayer, self).__init__()
# 自注意力层(带掩码)
self.self_attn = MultiHeadAttention(d_model, nhead, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
# 编码器-解码器注意力层
self.cross_attn = MultiHeadAttention(d_model, nhead, dropout)
self.norm2 = nn.LayerNorm(d_model)
self.dropout2 = nn.Dropout(dropout)
# 前馈网络层
self.feed_forward = PositionwiseFeedForward(d_model, d_ff, dropout)
self.norm3 = nn.LayerNorm(d_model)
self.dropout3 = nn.Dropout(dropout)
def forward(self, tgt, memory, tgt_mask=None, memory_mask=None):
# 自注意力与残差连接(带掩码)
attn_output, _ = self.self_attn(tgt, tgt, tgt, tgt_mask)
tgt = tgt + self.dropout1(attn_output)
tgt = self.norm1(tgt)
# 编码器-解码器注意力与残差连接
cross_attn_output, attn_weights = self.cross_attn(tgt, memory, memory, memory_mask)
tgt = tgt + self.dropout2(cross_attn_output)
tgt = self.norm2(tgt)
# 前馈网络与残差连接
ff_output = self.feed_forward(tgt)
tgt = tgt + self.dropout3(ff_output)
tgt = self.norm3(tgt)
return tgt, attn_weights
class Encoder(nn.Module):
"""编码器堆叠"""
def __init__(self, num_layers, d_model, nhead, d_ff, input_vocab_size, max_seq_len, dropout=0.1):
super(Encoder, self).__init__()
self.d_model = d_model
# 词嵌入层
self.embedding = nn.Embedding(input_vocab_size, d_model)
# 位置编码层
self.pos_encoder = PositionalEncoding(d_model, max_seq_len)
# 编码器层堆叠
self.layers = nn.ModuleList([
EncoderLayer(d_model, nhead, d_ff, dropout)
for _ in range(num_layers)
])
self.dropout = nn.Dropout(dropout)
def forward(self, src, src_mask=None):
# 词嵌入并缩放
src = self.embedding(src) * math.sqrt(self.d_model)
# 添加位置编码
src = self.pos_encoder(src)
src = self.dropout(src)
# 依次通过所有编码器层
for layer in self.layers:
src = layer(src, src_mask)
return src
class Decoder(nn.Module):
"""解码器堆叠"""
def __init__(self, num_layers, d_model, nhead, d_ff, target_vocab_size, max_seq_len, dropout=0.1):
super(Decoder, self).__init__()
self.d_model = d_model
# 词嵌入层
self.embedding = nn.Embedding(target_vocab_size, d_model)
# 位置编码层
self.pos_encoder = PositionalEncoding(d_model, max_seq_len)
# 解码器层堆叠
self.layers = nn.ModuleList([
DecoderLayer(d_model, nhead, d_ff, dropout)
for _ in range(num_layers)
])
self.dropout = nn.Dropout(dropout)
def forward(self, tgt, memory, tgt_mask=None, memory_mask=None):
# 词嵌入并缩放
tgt = self.embedding(tgt) * math.sqrt(self.d_model)
# 添加位置编码
tgt = self.pos_encoder(tgt)
tgt = self.dropout(tgt)
# 保存注意力权重(用于可视化)
all_attn_weights = []
# 依次通过所有解码器层
for layer in self.layers:
tgt, attn_weights = layer(tgt, memory, tgt_mask, memory_mask)
all_attn_weights.append(attn_weights)
return tgt, all_attn_weights
class Transformer(nn.Module):
"""完整的Transformer模型"""
def __init__(self, num_encoder_layers, num_decoder_layers, d_model, nhead, d_ff,
input_vocab_size, target_vocab_size, max_seq_len, dropout=0.1):
super(Transformer, self).__init__()
# 编码器
self.encoder = Encoder(
num_encoder_layers, d_model, nhead, d_ff, input_vocab_size, max_seq_len, dropout
)
# 解码器
self.decoder = Decoder(
num_decoder_layers, d_model, nhead, d_ff, target_vocab_size, max_seq_len, dropout
)
# 最终线性层(将解码器输出映射到目标词汇表大小)
self.fc_out = nn.Linear(d_model, target_vocab_size)
# 初始化参数
self._init_weights()
def _init_weights(self):
# 初始化模型参数
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
def generate_square_subsequent_mask(self, sz):
"""生成上三角掩码(用于解码器自注意力,防止看到未来位置)"""
mask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
def forward(self, src, tgt, src_mask=None, tgt_mask=None, memory_mask=None):
# 编码器处理输入
memory = self.encoder(src, src_mask)
# 解码器处理目标序列并使用编码器输出
output, attn_weights = self.decoder(tgt, memory, tgt_mask, memory_mask)
# 最终线性层映射到词汇表大小
output = self.fc_out(output)
return output, attn_weights
# 示例使用
def test_transformer():
# 设置模型参数
num_encoder_layers = 6
num_decoder_layers = 6
d_model = 512
nhead = 8
d_ff = 2048
input_vocab_size = 10000 # 输入词汇表大小
target_vocab_size = 10000 # 输出词汇表大小
max_seq_len = 500
dropout = 0.1
# 创建模型
model = Transformer(
num_encoder_layers, num_decoder_layers, d_model, nhead, d_ff,
input_vocab_size, target_vocab_size, max_seq_len, dropout
)
# 生成随机输入
src = torch.randint(0, input_vocab_size, (32, 10)) # 批次大小=32,序列长度=10
tgt = torch.randint(0, target_vocab_size, (32, 8)) # 批次大小=32,序列长度=8
# 生成掩码
tgt_mask = model.generate_square_subsequent_mask(tgt.size(1))
# 前向传播
output, _ = model(src, tgt, tgt_mask=tgt_mask)
print(f"输出形状: {output.shape}") # 应该是 [32, 8, target_vocab_size]
if __name__ == "__main__":
test_transformer()
Encoder-only
当前主流模型转向 Encoder-Only 架构而非传统 Transformer(Encoder-Decoder)的核心原因,可从任务适配性、效率优化、技术演进和生态驱动四个维度深入分析:
一、任务适配性:从生成到理解的范式迁移
传统 Transformer 架构设计初衷是为序列到序列任务(如机器翻译)服务,其 Encoder-Decoder 结构通过交叉注意力机制实现输入与输出的关联生成。然而,随着 NLP 研究重心从生成任务转向理解任务(如文本分类、问答、语义匹配),Encoder-Only 架构展现出更强的针对性:
双向上下文建模:Encoder-Only 模型(如 BERT)通过双向自注意力机制同时捕捉前后文信息,而 Decoder 的掩码自注意力仅允许单向依赖,导致生成模型在理解任务中存在信息损失。例如,BERT 在 GLUE 基准的 9 项任务中刷新了 11 项 SOTA,其双向编码能力是关键。
任务泛化性:Encoder-Only 模型通过预训练 + 微调范式,只需在输出层添加特定任务头即可适配多种理解任务(如情感分析、实体抽取),而 Encoder-Decoder 模型需针对生成任务定制复杂的解码流程。
二、效率优化:计算成本与工程落地的双重突破
Encoder-Only 架构在训练和推理效率上具有显著优势,这是其被广泛采用的重要技术动因:
并行计算能力:Encoder-Only 模型可一次性处理完整输入序列,而 Decoder 的自回归生成需逐个 Token 计算,导致时间复杂度从\(O(n)\)变为\(O(n^2)\)(n为序列长度)。例如,ModernBERT 通过交替使用全局注意力和局部注意力,在处理 8192 Token 长文本时速度比 DeBERTa 快 3 倍,内存占用减少 80%
参数效率:移除解码器模块后,模型参数量显著降低。以 BERT-Base(110M 参数)与同规模 Encoder-Decoder 模型(如 T5-Base,220M 参数)相比,Encoder-Only 架构节省近 50% 计算资源。这种轻量化设计尤其适合边缘设备和实时推理场景。
三、技术演进:预训练范式与架构创新的协同
Encoder-Only 架构的崛起与 NLP 技术演进路径深度绑定:
预训练目标的革新:掩码语言模型(MLM)等预训练任务天然适配 Encoder-Only 架构。例如,BERT 通过随机掩码 15% 的 Token 并预测其原始值,迫使模型学习上下文语义关联,而 Decoder 的自回归预测(如 GPT)更侧重序列生成能力。
位置编码与长文本处理:传统 Transformer 的固定位置编码在长序列中表现不佳,而 Encoder-Only 模型通过旋转位置嵌入(RoPE)等技术显著扩展上下文长度。例如,ModernBERT 将上下文窗口扩展至 8192 Token,在代码检索等长文本任务中超越所有开源模型。
多模态扩展潜力:Encoder-Only 架构可通过简单改造支持跨模态任务。例如,ViT 将图像分割为 Patch 序列后直接输入 Encoder,实现与文本任务的统一建模,而 Encoder-Decoder 需额外设计跨模态交互机制。
四、生态驱动:开源框架与行业实践的双向选择
Encoder-Only 架构的普及离不开社区生态和产业需求的共同推动:
开源模型的示范效应:BERT、RoBERTa 等开源模型的成功降低了技术门槛,企业可直接基于这些模型快速构建 NLP 应用。例如,GLM-4 等国产模型在中文任务中达到 GPT-4 的 88% 性能,推动 Encoder-Only 架构在金融、医疗等领域的落地。
垂直领域的刚需:在金融风控、舆情监控等场景中,模型需高效解析长文本并提取关键信息,Encoder-Only 架构的语义理解能力直接满足需求。例如,某电商平台应用 Encoder-Only 模型后,用户评论分析效率提升 40 倍。
训练资源的可获取性:Encoder-Only 模型对算力要求较低,中小企业可在消费级 GPU 上完成训练。相比之下,训练 GPT-4 级别的 Decoder 模型需数千块 A100 GPU,形成技术壁垒。
五、挑战与未来:Encoder-Only 的边界与融合趋势
尽管 Encoder-Only 架构占据主流,但其仍面临以下挑战:
生成任务的局限性:在需要创造性文本生成(如故事创作)或多轮对话场景中,Decoder-Only 模型(如 GPT)表现更优。
长序列效率瓶颈:即使采用 RoPE 和 Flash Attention,Encoder-Only 模型在处理数万 Token 时仍存在计算压力。
混合架构的探索:部分模型尝试融合 Encoder-Decoder 与 Encoder-Only 的优势。例如,T5 通过统一文本到文本框架,在生成任务中结合编码器的上下文理解能力和 Decoder 的生成能力。
总结
Encoder-Only 架构的兴起是 NLP 技术发展的必然结果:理解任务的刚需、效率优势的驱动、预训练范式的适配、以及生态系统的成熟共同推动其成为主流。尽管 Encoder-Decoder 架构在生成任务中仍不可替代,但 Encoder-Only 模型已在语义理解、多模态融合等领域建立了不可撼动的地位。未来,随着技术的进一步突破(如稀疏注意力、参数高效微调),Encoder-Only 架构有望在更多场景中实现 “理解 + 生成” 的轻量化统一。
Decoder-only
一、模型定义与核心架构
Decoder-Only 模型是指仅基于 Transformer 解码器(Decoder)构建的神经网络架构,其核心特点是通过自回归(Autoregressive)方式逐 token 生成序列。典型代表包括 GPT 系列(GPT-1/2/3/4)、PaLM、Llama 等。这类模型的架构具备以下特征:
单流架构:仅包含解码器层,无编码器组件
掩码自注意力(Masked Self-Attention):确保生成时只能关注已生成的前文信息
位置编码:通常使用绝对位置编码(如 GPT)或旋转位置编码(如 RoPE,用于 Llama 2)
自回归训练目标:以最大化序列下一个 token 的预测概率为优化目标(即 P (xn|x1,x2,...,xn-1))
二、核心优势解析
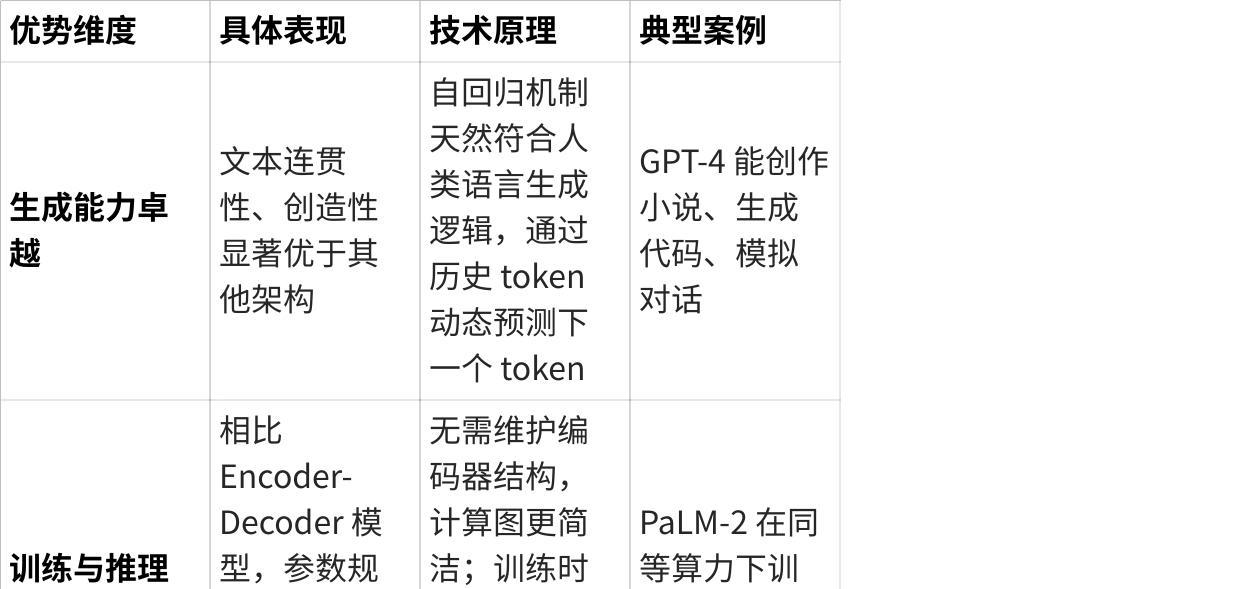
点击图片可查看完整电子表格
三、关键局限性分析
双向语义理解缺陷
由于掩码机制限制,模型无法同时获取上下文双向信息,在需要全局理解的任务(如阅读理解、语义相似度计算)中表现弱于 Encoder 模型(如 BERT)
案例:GPT-3 在 SQuAD 阅读理解任务上准确率比 BERT-base 低 12%
生成效率与显存瓶颈
自回归生成需逐个 token 计算,推理速度比非自回归模型慢 5-10 倍(如对比 FastSpeech)
长序列生成时显存占用呈平方级增长:生成 10k token 需约 70GB 显存(GPT-4 参数量级)
训练成本与数据依赖
需海量高质量语料(通常万亿级 token),且训练过程存在梯度消失风险
案例:GPT-3 训练消耗 3640 PetaFLOPS/s-day,数据来自 WebText2 等混合语料库
结构泛化性局限
难以直接处理非生成任务(如文本分类),需通过 Prompt 工程或适配器(Adapter)间接实现
多模态融合能力依赖外挂模块(如 GPT-4V 的视觉处理组件)
四、与其他架构的对比定位
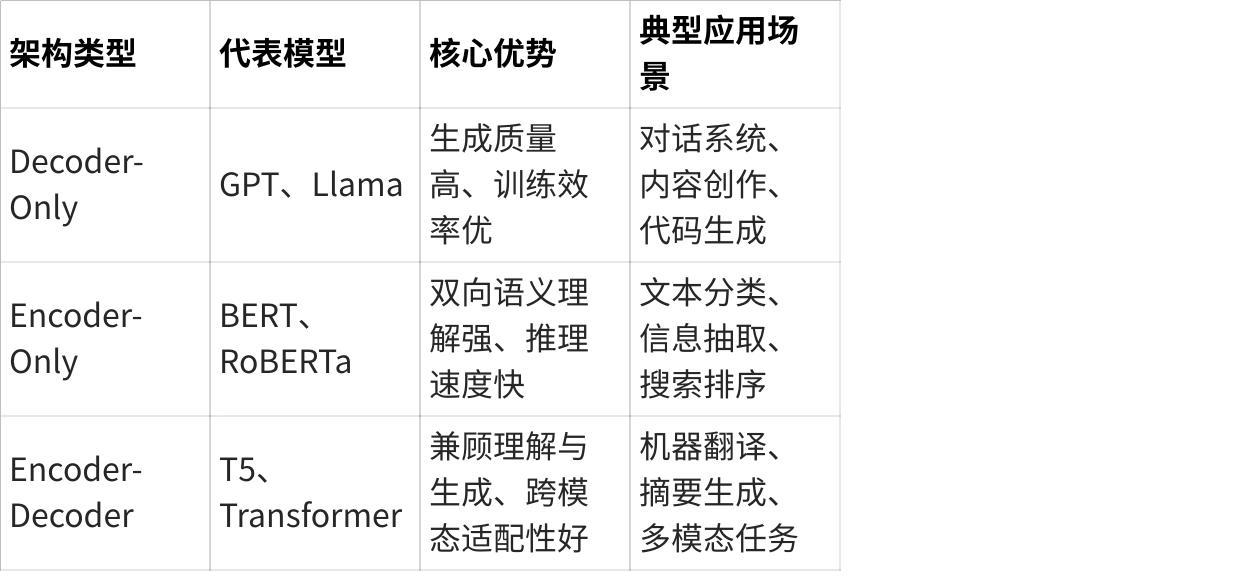
点击图片可查看完整电子表格
五、发展趋势与优化方向
高效生成技术:引入并行解码(如 Prefix Tuning)、流式生成(Streaming Generation)降低延迟
双向信息融合:通过 RMT(Retrieval-Augmented Model)等技术外挂知识库补充全局信息
混合架构探索:如 GLM-4 采用 "Encoder-Decoder+Decoder-Only" 混合模式,兼顾理解与生成
Decoder-Only 模型凭借生成能力优势已成为 AIGC 领域的主流架构,但在复杂理解任务和高效推理场景中仍需与其他架构协同发展。未来随着位置编码、训练算法的持续优化,其在长文本、多模态场景的应用边界将进一步拓展。
Transformer和Bert对比
Transformer 是一种通用的神经网络架构,而 BERT(Bidirectional Encoder Representations from Transformers)是基于 Transformer 架构构建的具体模型,专注于自然语言理解(NLU)任务。两者的异同可从架构设计、训练目标、应用场景、优缺点等维度深入对比:
一、核心架构对比
Transformer(原始架构)
结构:包含 Encoder 和 Decoder 两部分,Encoder 负责编码输入序列,Decoder 负责生成输出序列。
Encoder:由多层自注意力(Self-Attention)和前馈网络组成,支持双向上下文建模。
Decoder:除自注意力外,包含交叉注意力(Cross-Attention)模块,用于关联 Encoder 的输出和当前 Decoder 的输入。
关键机制:
自注意力机制:捕捉序列内部依赖关系,解决 RNN 长距离依赖问题。
位置编码:引入固定或可学习的位置信息,弥补自注意力的顺序无关性。
代表模型:原始 Transformer(用于机器翻译)、T5(Encoder-Decoder 架构的预训练模型)。
BERT(Encoder-Only 架构)
结构:仅使用 Transformer 的 Encoder 部分,移除 Decoder,专注于输入序列的双向编码。
每个 Encoder 层由双向自注意力和前馈网络组成,支持全词上下文建模。
关键改进:
预训练任务:
掩码语言模型(MLM):随机掩码输入 Token,强制模型通过上下文预测原始词,学习双向语义关联。
下一句预测(NSP):判断两个句子是否连续,优化段落级语义理解。
位置编码:采用可学习的位置嵌入(与原始 Transformer 的固定正弦编码不同)。
代表模型:BERT、RoBERTa、ALBERT 等均属于 Encoder-Only 架构。
二、核心差异:从架构到能力

点击图片可查看完整电子表格
三、优缺点对比
Transformer 的优势与局限
优势:
通用性强:适用于理解与生成任务的统一建模(如 T5 用 “文本到文本” 框架覆盖多种任务)。
生成能力原生支持:Decoder 的自回归机制适合开放式文本生成(如故事创作、对话系统)。
局限:
计算成本高:Decoder 的逐 Token 生成导致推理速度慢,长序列场景下内存占用大(如生成 1000 Token 的文本需 100 万次计算)。
理解任务非最优:Decoder 的单向掩码导致语义建模不完整,在纯理解任务中效率低于 Encoder-Only 模型。
BERT 的优势与局限
优势:
双向语义建模更强:通过 MLM 强制学习上下文依赖,在 NLU 任务中表现显著优于单向模型(如 ELMo)。
效率高:Encoder 并行计算大幅提升训练和推理速度,同等参数规模下训练成本比 Encoder-Decoder 低 50%。
微调适配性好:只需添加简单任务头(如分类层、指针网络)即可适配多种理解任务,工程落地门槛低。
局限:
生成能力弱:原生不支持自回归生成,需结合 Decoder(如 BERT+GPT 混合架构)或改造预训练目标(如去噪自编码器)。
长序列处理受限:原始 BERT 最大序列长度为 512 Token,需通过扩展位置编码(如 RoPE)或稀疏注意力(如 Longformer)优化。
为什么encoder-only的模型不需要掩码
不需要掩码的原因: Encoder-only模型(如BERT)处理的是完整且已知的输入序列,其核心任务是理解整个序列的上下文信息。为了充分捕捉词与词之间所有方向的关系(包括前后关系),它需要允许每个位置关注序列中的所有其他位置(包括它后面的位置)。施加掩码(阻止关注未来位置)会破坏这种全局理解能力。
需要掩码的原因: Decoder(或类似自回归生成的结构)在生成序列时,未来的位置是未知的或不应该被访问的(避免信息泄露)。掩码确保模型在预测当前位置 t 时,只依赖于它之前已经确定的位置 1 到 t-1,从而保持训练(使用完整目标序列但掩蔽未来)和推理(逐步生成,没有未来信息)的一致性。
简单来说:Encoder看“整本书”来做理解,所以需要看到所有内容(包括后面的章节);Decoder是“逐字写书”,写当前字时只能参考已经写好的前面部分,不能参考还没写的后面部分(也不知道后面要写什么),所以需要掩码来挡住“未来的空白页”。
四、技术演进与应用场景选择
技术演进路径
Transformer 的发展:
向生成方向深化:如 GPT 系列(Decoder-Only 架构,专注生成)、PaLM(千亿参数生成模型)。
多模态扩展:如 Vision Transformer(ViT)、FLAVA(文本 - 图像统一建模)。
BERT 的发展:
优化预训练策略:如 RoBERTa(动态掩码)、ALBERT(参数轻量化)、ELECTRA(替换检测任务)。
长文本增强:如 Longformer(滑动窗口注意力)、BigBird(稀疏注意力)。
场景选择建议
选择 Transformer(Encoder-Decoder):
任务包含生成需求:如机器翻译、文本摘要、代码生成、对话系统。
需要统一建模理解与生成:如多任务学习(T5 用 “Text-to-Text” 统一所有任务)。
选择 BERT(Encoder-Only):
纯语义理解任务:如情感分析、意图识别、信息检索、事实核查。
对效率敏感的场景:如实时推荐系统、边缘设备上的语义分析。
五、总结:互补而非替代
Transformer 是基础架构,定义了自注意力机制、位置编码等核心组件,为 NLP 和 CV 提供了通用框架。
BERT 是 Transformer Encoder 的优化实现,通过预训练任务创新,将双向语义建模推向极致,成为 NLU 领域的标杆。
未来趋势:两者并非对立,而是在不同任务领域深化发展 —— 生成任务向 Decoder-Only 架构(如 GPT)演进,理解任务向 Encoder-Only 优化(如现代 BERT 变种),同时混合架构(如 Encoder-Decoder 的 T5、UL2)尝试融合两者优势,覆盖更广泛场景。
一句话概括:Transformer 是 “全能框架”,BERT 是 “理解专家”,按需选择即可。
什么是flash attention?
在深度学习领域,Transformer 架构的广泛应用推动了自然语言处理、计算机视觉等任务的突破,但 Self-Attention 机制的高计算复杂度始终是制约其处理长序列和大规模模型的瓶颈。Flash Attention 作为近年来提出的高效优化方案,通过内存与计算的智能调度,显著提升了 Transformer 的训练与推理效率。
1. 分块注意力计算(Chunked Attention)
将长序列按固定长度(如 chunk_size=256)切分,分块计算注意力并累加结果,避免一次性处理完整矩阵:
前向传播:对每个 chunk,仅计算其内部及与前序 chunk 的注意力(因果注意力场景),而非全局关联;
反向传播:分块反向计算梯度,释放未处理 chunk 的中间变量。
2. 重新计算(Recomputation)策略
舍弃前向传播中可重建的中间激活值(如 softmax 前的注意力分数),反向传播时通过重新计算前向过程来生成梯度,以计算时间换取内存空间。实验表明,该策略可减少 50% 的激活值内存占用,仅增加约 20% 的计算量。
3. 内存访问优化
平铺操作(Tiling):将大矩阵乘法拆分为多个小矩阵运算,适配 GPU 缓存结构,减少内存带宽瓶颈;
融合操作(Fusion):将 softmax 与矩阵乘法等操作合并为单个 CUDA 内核,减少内核调用开销。
实际优势:速度与内存的双重突破
1. 效率提升显著
训练速度:在长序列任务(如 n=8192)中,Flash Attention 相比传统 Self-Attention 提速 2-4 倍;
内存节省:当 n=4096 时,内存占用从 64GB 降至 16GB 以下,使训练更大模型或更长序列成为可能。
2. 保持数值精度
通过引入旋转位置嵌入(RoPE)等技术适配,Flash Attention 在优化计算的同时,保证了与传统 Self-Attention 相近的输出精度,避免因近似计算导致性能损失。
3. 长序列处理能力拓展
传统 Self-Attention 在 n>2048 时计算成本剧增,而 Flash Attention 支持 n=16k 甚至更长序列的高效处理,为长文本理解、长视频分析等场景提供技术支撑。
传统 Self-Attention 的计算流程可拆解为三步:
相似度计算:通过矩阵乘法计算 Query 与 Key 的点积,得到注意力分数矩阵;
softmax 归一化:对分数矩阵按行归一化,生成注意力权重;
加权求和:权重矩阵与 Value 矩阵相乘,得到最终输出。
这一过程的时间复杂度为 O (n²d)(n 为序列长度,d 为特征维度),空间复杂度为 O (n²),当处理长文本(如 n=4096)或大批次数据时,会面临两大挑战:
内存爆炸:n=4096 时,注意力矩阵规模达 1600 万 ×1600 万,单精度浮点型需约 64GB 内存;
计算冗余:前向传播中的中间激活值(如注意力权重矩阵)在反向传播时仍需保留,进一步加剧内存压力。
Flash Attention 通过两个关键技术彻底改变了计算方式,避免了创建和访问巨大的 N x N 中间矩阵 S 和 P:
Tiling / 分块计算:
将大的输入矩阵 Q, K, V 分块成更小的块(Tile),这些块的大小被设计为能够放入 GPU 片上高速但容量较小的 SRAM 中。
计算过程不再是整个大矩阵一次性计算,而是在 SRAM 内部,对这些小块进行精细化的 Attention 计算。
Recomputation / 重计算 + 在线 Softmax:
在 SRAM 内部处理小块时,算法不直接计算完整的 S 或 P。
它采用了一种称为 “在线 Softmax” 的技巧,结合重计算策略。
关键点:算法增量式地计算最终的输出 O 和 softmax 归一化所需的统计量(如行最大值 m(x) 和指数和 l(x))。
对于每一块数据,它计算局部部分和,并不断地将这些部分和与全局的统计量(m(x), l(x))融合(fuse) 起来。这个融合过程利用了 softmax 的数学性质(softmax(x) = softmax([x1, x2]) 可以通过 softmax([m1, m2]) 和 l1, l2 来正确组合)。
最终,当所有块处理完毕时,算法直接得到了正确的 O(Attention 输出),而从未在显存中显式地存储过完整的 S 或 P 矩阵。
Flash Attention 的优势
大幅减少显存访问(I/O 高效):
这是最核心的优势。通过将计算限定在高速 SRAM 内完成,并避免读写巨大的 N x N 矩阵,Flash Attention 将主要的显存访问量从 O(N²d + N²)(读写 S/P)降低到了 O(N²d / M),其中 M 是 SRAM 的大小(通常远小于 N)。这极大地缓解了显存带宽瓶颈。
计算虽然总量没变(还是 O(N²d)),但访问数据快了很多,所以整体速度大幅提升。
大幅降低显存占用:
不再需要存储 O(N²) 的 S 和 P 矩阵。计算过程中只需要维护最终输出 O(O(Nd))和一些小的统计量(O(N))。显存占用从 O(N²) 降到了 O(N)。这使得训练或推理更长的序列成为可能,而不会耗尽显存。
显著提升计算速度:
由于减少了慢速的显存访问,计算速度(实际运行时间)得到了大幅提升。论文中显示,在 BERT-large 等模型上,端到端训练速度可提升 15%,而 Attention 计算本身的速度提升可达 2-4 倍(具体取决于序列长度和硬件)。
支持精确计算:
Flash Attention 是一种精确算法,它计算出的结果与标准的、需要存储完整 S 和 P 的 Attention 计算在数学上是完全等价的。它不是近似方法(如稀疏 Attention、线性 Attention)。
说说什么是MoE架构?
MoE(Mixture of Experts)即 “混合专家模型”,是一种通过稀疏激活机制让模型具备 “分工协作” 能力的架构设计。其核心思想是:将模型参数划分为多个独立的 “专家模块”(Expert),每个输入样本仅激活其中一小部分专家进行计算,而非让所有专家处理全部数据。
专家分工与路由机制:
模型包含 N 个专家(如 N=64),每个专家是一个独立的子网络(如 MLP);
引入 “路由网络”(Router),根据输入内容计算每个专家的 “门控权重”,选择激活概率最高的 k 个专家(如 k=2),形成 “专家子集”。
例:输入一句话时,路由网络判断 “语义理解” 专家和 “常识推理” 专家最相关,仅这两个专家参与计算。
稀疏激活与参数规模解耦:
总参数规模 = 专家数量 × 单个专家参数数(如 64×10 亿 = 640 亿参数),但每次计算仅激活 k 个专家(如 2×10 亿 = 20 亿参数),实现 “大参数规模 + 小计算量”。
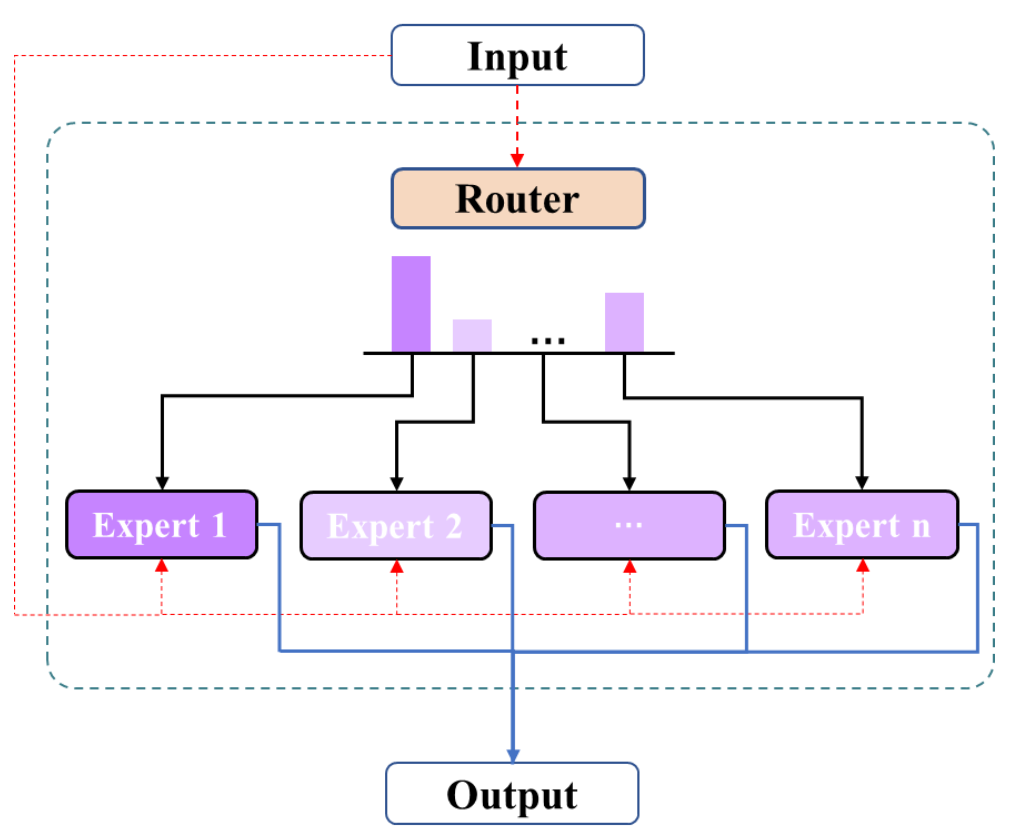
负载不均衡 门控正交化 + 本地性约束(Locality Loss)
专家协作不足 顺序激活专家链(Chain-of-Experts, CoE)
deepseek的MoE优化
共享专家 + 256 路由专家,细粒度任务分解
Softmax 门控改成了sigmoid门控
训练成本是传统MoE的十分之一
为什么要用正弦余弦来做位置编码?还知道其他哪些位置编码?
在自然语言处理(NLP)中,位置编码是为序列数据提供位置信息的关键技术,尤其是在 Transformer 模型中(因其缺乏循环结构,无法直接捕捉序列顺序)。以下从正弦余弦位置编码的原理、优势及其他常见位置编码方法展开说明:
一、为什么使用正弦余弦进行位置编码?
1. 数学性质:周期性与相对位置表示
正弦余弦函数的周期性使其能通过频率差异表示不同尺度的位置关系。例如:
对于位置i和维度d,正弦余弦位置编码的公式为:
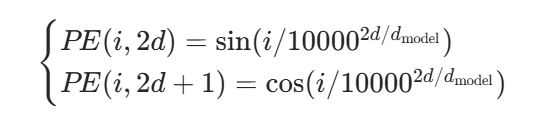
其中d model是模型维度,低频对应大尺度位置(如段落间的相对位置),高频对应小尺度位置(如词间的相邻关系)。
优势:通过三角函数的线性组合,模型可利用sin(a+b) = sin acos b + cos asin b等性质,直接学习位置的相对偏移,而无需显式计算绝对位置差。
2. 长序列泛化能力
正弦余弦编码不依赖固定位置范围(如绝对位置编码需预设最大序列长度),可通过周期延拓自然适应更长序列,避免训练时最大长度与推理时不一致的问题。
3. 计算高效性
无需学习参数,仅通过公式生成,减少模型训练负担,且可预处理为固定向量,提升推理效率。
二、其他常见位置编码方法
1. 绝对位置编码(可学习嵌入)
原理:为每个位置i分配一个可学习的向量\(E_i\),类似词嵌入,通过训练优化参数。
示例:BERT 使用的位置编码即属于此类,向量维度与词嵌入一致,通过相加融入输入。
优缺点:
优点:直接学习绝对位置信息,适合短序列任务(如文本分类)。
缺点:最大序列长度需预先设定,泛化到更长序列时能力有限。
2. 相对位置编码(Relative Position Embedding)
原理:不关注绝对位置,而是建模两个 token 之间的相对距离k(如\(k=i-j\))。
实现方式:
参数化相对位置:为每个可能的相对距离k(如\(k \in [-max, max]\))学习一个向量\(R_k\),用于注意力计算时调整权重。
示例:Transformer-XL 使用此类编码,在计算注意力时引入\(R_{i-j}\)。
优缺点:
优点:更符合语言中 “依赖关系多为局部” 的特性,减少长序列计算量。
缺点:需限定相对距离范围,对长距离依赖建模能力较弱。
3. 旋转位置编码(RoPE, Rotary Position Embedding)
原理:通过复数旋转矩阵对查询向量Q和键向量K进行位置依赖的旋转变换,将位置信息融入向量内积计算。
数学形式:对位置i和维度d,定义旋转矩阵\(R_i\),使\(QK^T\)的计算隐含位置偏移: \(\text{RoPE}(Q, K, i) = Q \cdot R_i \cdot K^T\)
应用:GPT-3、LLaMA 等模型采用,相比正弦余弦编码,在长序列生成中表现更优。
4. ALiBi(Attention with Linear Biases)
原理:不直接生成位置向量,而是在注意力权重中添加与相对位置相关的偏置项。例如,对于位置i和j(\(i > j\)),偏置为\(-\lambda(i-j)\),使模型更关注左侧(前文)信息。
优点:无需额外参数,计算高效,适合自回归生成任务(如文本续写)。
5. 混合位置编码(Hybrid Approaches)
原理:结合绝对位置与相对位置的优势。例如:
稀疏位置编码:对局部位置用绝对编码,对长距离位置用相对编码(如 Reformer 模型)。
动态位置编码:根据输入内容动态调整位置表示(如在图像生成中结合空间坐标)。
三、不同方法对比与应用场景
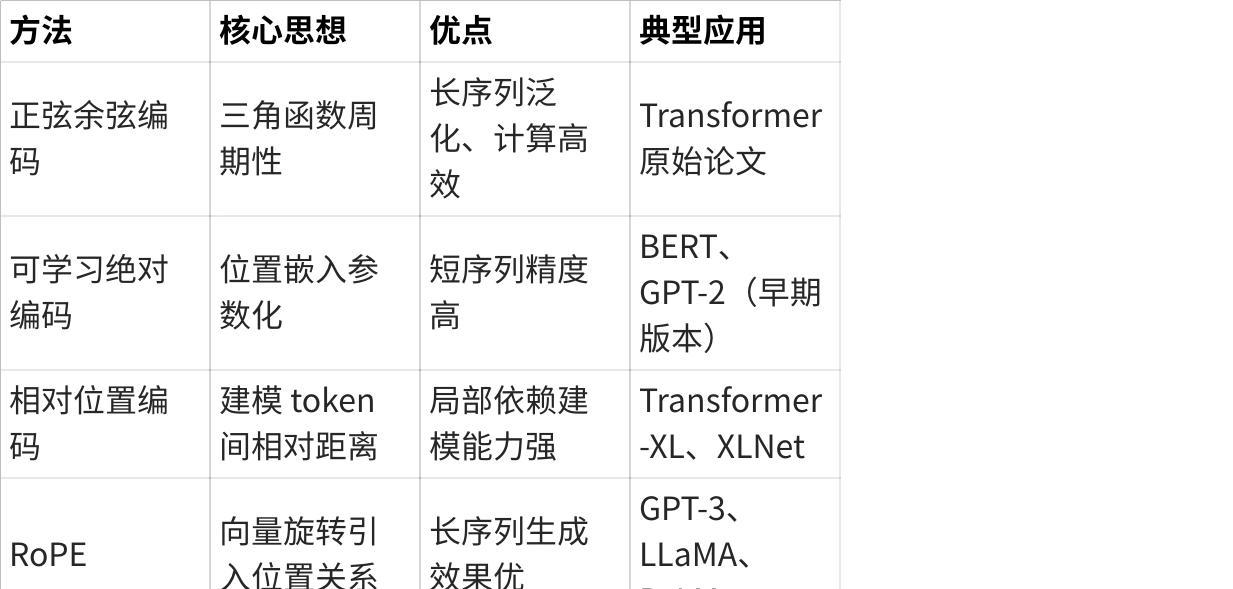
点击图片可查看完整电子表格
LoRA
LoRA(Low-Rank Adaptation)深度解析:大模型高效微调的核心技术
一、技术背景:大模型微调的算力困境
随着 GPT、LLaMA、Stable Diffusion 等大模型的参数规模突破千亿甚至万亿,传统全参数微调(Fine-tuning)面临巨大挑战:
算力成本极高:微调一个 70 亿参数模型可能需要数十张 A100 显卡和数天时间,普通团队难以承担。
内存占用大:全参数更新需要存储海量梯度和优化器状态,消费级硬件(如 RTX 3090)无法支持。
过拟合风险:大模型参数冗余度高,直接微调可能破坏预训练能力(“灾难性遗忘”)。
LoRA(2021 年由微软提出)正是为解决这些问题而生,其核心思想是通过 “参数高效微调”(Parameter-Efficient Fine-Tuning, PEFT)技术,在几乎不损失性能的前提下,将可训练参数压缩 1000 倍以上。
二、核心原理:低秩矩阵分解与适配器插入
1. 数学本质:用低秩子空间近似参数更新
传统微调中,模型参数更新可表示为 \(\Delta W \in \mathbb{R}^{d \times k}\)(d和k为矩阵维度),若直接训练\(\Delta W\),需更新\(d \times k\)个参数。 LoRA 的做法是将\(\Delta W\)分解为两个低秩矩阵的乘积:
\(\Delta W = BA \quad \text{其中} \quad B \in \mathbb{R}^{d \times r}, \, A \in \mathbb{R}^{r \times k}\)
这里r是远小于d和k的秩(通常\(r=8 \sim 64\)),因此可训练参数从\(d \times k\)减少到\(r(d + k)\),压缩率约为\(\frac{r(d + k)}{d \times k} \approx \frac{r}{\max(d, k)}\)(例如\(d=k=1000\),\(r=16\)时,参数从 100 万降至 3.2 万,压缩 312 倍)。
2. 模型改造:冻结预训练参数,插入适配器
冻结原始权重:预训练模型的权重\(W_0\)保持不变,仅训练新增的适配器参数A和B。
前向传播修改:模型输出由 “原始权重 + 适配器权重” 组成:\(h = W_0 x + \alpha \cdot BAx\)其中\(\alpha\)是可训练或固定的缩放因子(通常初始化为r,防止训练初期梯度爆炸)。
3. 直观理解:用 “小参数空间” 控制 “大模型行为”
LoRA 假设:大模型在下游任务中的参数更新本质上位于一个低维子空间中。通过训练低秩矩阵A和B,相当于在高维参数空间中找到一个 “方向”,用极少的参数控制模型输出的变化,而无需修改原始预训练权重的主体结构。
三、技术实现:从理论到代码的关键步骤
以 LLM 中线性层(如 Attention 的 Query/Key/Value 投影)为例,LoRA 的实现流程如下:
识别目标层:选择需要插入适配器的层(如 Transformer 的每一层 Attention 和 FFN)。
添加适配器结构:
对维度为\(d \times k\)的权重矩阵\(W_0\),创建两个低秩矩阵\(A \in \mathbb{R}^{r \times k}\)(随机初始化)和\(B \in \mathbb{R}^{d \times r}\)(初始化为 0)。
前向传播时,计算BAx并与\(W_0x\)叠加(乘缩放因子\(\alpha\))。
训练策略:
冻结\(W_0\),仅反向传播更新A和B。
通常配合梯度累积、学习率调度等技术,加速收敛。
Python
import torch
import torch.nn as nn
class LoRALinear(nn.Module):def __init__(self, in_features, out_features, r=8, alpha=8.0):super().__init__()
self.in_features = in_features
self.out_features = out_features
self.r = r
self.alpha = alpha
# 原始权重(冻结)
self.W0 = nn.Linear(in_features, out_features, bias=False)
self.W0.weight.requires_grad = False# LoRA适配器(可训练)
self.A = nn.Linear(in_features, r, bias=False)
self.B = nn.Linear(r, out_features, bias=False)# 初始化B为0,确保初始时LoRA不影响输出
nn.init.zeros_(self.B.weight)def forward(self, x):# 原始输出 + LoRA输出 * (alpha/r) (缩放因子归一化)return self.W0(x) + (self.B(self.A(x)) * self.alpha / self.r)
四、核心优势:为什么 LoRA 能兼顾效率与性能?
参数数量级压缩:
以 70 亿参数模型为例,传统全参数微调需更新 70 亿参数,而 LoRA(\(r=16\))仅需更新约\(70亿 \times \frac{16 \times (d + k)}{d \times k} \approx 数百万\)参数(实际因层结构不同,可压缩至数万到数百万)。
显存需求大幅降低:
无需存储原始权重的梯度,仅需存储适配器参数的梯度,普通显卡(如 RTX 4090)即可微调 130 亿参数模型。
性能接近全微调:
实验表明,在 GLUE、SuperGLUE 等 NLP 任务上,LoRA(\(r=32\))的效果与全参数微调差距在 1% 以内,部分任务甚至持平。
灵活性与可组合性:
可与量化技术(如 INT8/INT4)结合(如 QLoRA),进一步降低内存;
支持多任务适配器叠加(如同时训练多个领域的适配器,通过权重插值切换任务)。
五、应用场景与典型案例
大语言模型定制:
垂直领域微调:基于 LLaMA、Vicuna 等模型训练医疗、法律领域对话模型,如 Meta 的 LLaMA-Adapter 采用 LoRA 框架。
指令微调(Instruct Tuning):OpenAI 的 ChatGPT、Anthropic 的 Claude 在微调阶段可能使用类似 LoRA 的技术降低成本。
视觉模型迁移学习:
图像生成模型(如 Stable Diffusion)的 LoRA 微调,可在保持生成能力的同时,定制特定风格(如二次元、3D 渲染),仅需训练数万参数。
多模态模型优化:
如 CLIP、ALBEF 等模型在跨模态任务中,通过 LoRA 适配不同数据集,减少过拟合风险。
六、与其他 PEFT 技术的对比
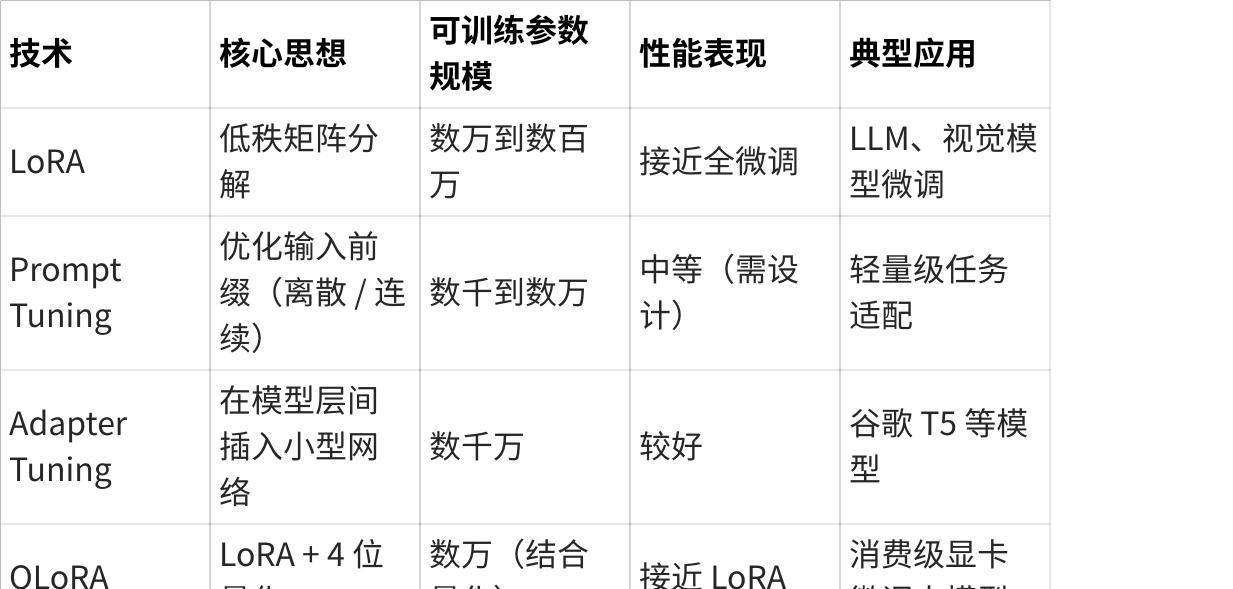
点击图片可查看完整电子表格
七、局限性与改进方向
秩r的选择:r过小可能限制表达能力,过大则失去效率优势,通常需通过实验确定(如 NLP 中\(r=16 \sim 64\),CV 中\(r=8 \sim 32\))。
跨任务兼容性:单适配器可能难以同时适配多个差异较大的任务,需结合多适配器融合技术。
后续优化:
QLoRA:通过 4 位量化 + 双量化技术,在保持 LoRA 效率的同时,使 70 亿参数模型可在单张消费级显卡微调(显存占用 < 16GB)。
LoRA+P-Tuning:结合提示微调与低秩适应,进一步提升小样本学习能力。
八、总结:LoRA 如何改变大模型微调范式?
LoRA 的核心贡献在于证明了 “大模型的有效参数更新可被低秩子空间表示”,这一思想彻底降低了大模型微调的门槛,使中小团队甚至个人开发者也能基于开源大模型(如 LLaMA、Falcon)定制专属模型。从技术趋势看,LoRA 已成为 PEFT 领域的基础框架,其与量化、提示工程的结合,正推动大模型应用从 “中心化训练” 向 “边缘个性化微调” 演进。
PEFT
PEFT(参数高效微调):大模型时代的微调革命
参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)是近年来深度学习领域的重要突破,它彻底改变了传统大模型微调的范式,使资源受限的团队甚至个人也能基于千亿参数模型定制专属应用。以下从技术背景、核心方法、应用场景到未来趋势进行全面解析:
一、技术背景:传统微调的困境与 PEFT 的诞生
1. 传统全参数微调的痛点
算力成本高:微调一个 7B 参数模型需约 28GB 显存(FP16 精度),175B 参数模型(如 GPT-3)则需 700GB + 显存,远超普通设备能力。
数据需求大:需大量标注数据才能避免过拟合,小样本场景效果差。
灾难性遗忘:直接更新所有参数可能破坏预训练阶段获得的通用知识。
2. PEFT 的核心目标
在保持预训练模型能力的前提下,通过冻结大部分参数,仅训练少量额外参数(通常 < 1%)实现高效任务适配。例如:
LoRA(低秩适应)通过低秩矩阵分解将可训练参数压缩至数万到数百万。
Adapter Tuning 在模型层间插入小型神经网络(约 1% 参数)。
Prefix Tuning 仅优化输入前缀向量(约 0.01% 参数)。
二、PEFT 核心技术分类与原理
1. 适配器方法(Adapter Insertion)
核心思想:在预训练模型的特定层间插入小型可训练模块(适配器),冻结原始参数。
代表性技术:
LoRA(Low-Rank Adaptation) 对权重矩阵W进行低秩分解:\(W = W_0 + \alpha \cdot BA\),其中\(W_0\)是冻结的预训练权重,\(B \in \mathbb{R}^{d \times r}\)和\(A \in \mathbb{R}^{r \times k}\)是低秩矩阵(\(r \ll d,k\)),仅训练A和B。典型应用于 Transformer 的 QKV 投影和 FFN 层。
Adapter Tuning 在每层 Transformer 后插入 MLP 适配器(通常 2 层,维度为\(d \rightarrow r \rightarrow d\),r为降维因子),如 Houlsby Adapter。
BitFit 仅微调权重矩阵的偏置项(bias),其他参数冻结,参数量降至 0.01% 以下。
2. 提示工程方法(Prompt Tuning)
核心思想:通过优化输入提示(而非模型参数)引导模型输出期望结果。
代表性技术:
P-Tuning 在输入文本前添加连续可训练的提示向量,通过反向传播学习这些向量。
Prefix Tuning 在 Transformer 每层的注意力计算前添加可训练的 “前缀” 向量,影响注意力分布,无需修改模型结构。
Prompt Tuning v2 仅微调每层 Transformer 的前几个 token(通常 10-20 个),冻结其他参数,显存占用极低。
3. 参数重参数化方法(Reparameterization)
核心思想:通过结构化剪枝或权重共享减少可训练参数。
代表性技术:
DiffPruning 动态识别并剪枝对任务不重要的连接,仅保留关键参数进行微调。
Sparse Fine-Tuning 随机选择一小部分参数(如 5-10%)进行更新,其他参数冻结。
4. 混合方法(Hybrid Approaches)
核心思想:结合多种 PEFT 技术提升效果。
代表性技术:
LoRA + Prefix Tuning 同时使用低秩适应和前缀微调,兼顾参数效率和任务灵活性。
QLoRA LoRA 与 4 位量化结合,在单张消费级显卡(如 RTX 4090)上微调 70B 参数模型,显存占用 < 16GB。
三、PEFT 关键优势与技术对比
1. 核心优势
资源消耗显著降低: 从需数十张 A100 显卡到单卡甚至消费级硬件即可微调大模型。
数据效率提升: 在小样本场景下表现优于传统微调,减少对大规模标注数据的依赖。
模型兼容性强: 同一预训练模型可存储多个轻量级适配器(如 LoRA 权重),分别适配不同任务。
训练速度加快: 可训练参数减少,梯度计算和内存访问开销降低,训练速度提升数倍。
2. 不同 PEFT 技术对比
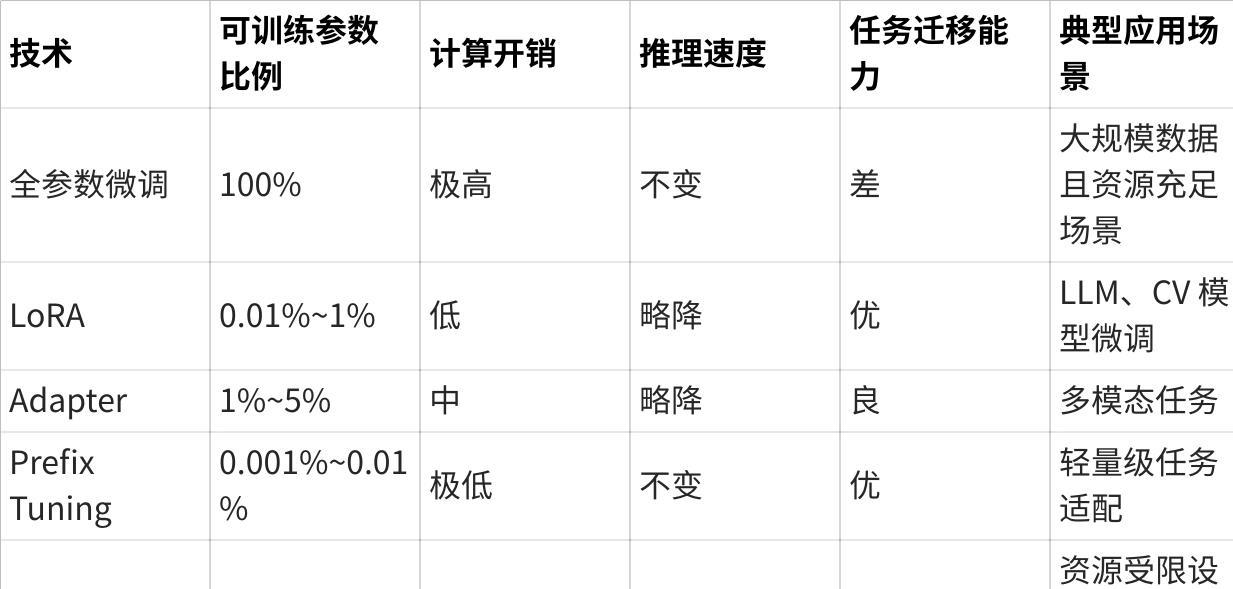
点击图片可查看完整电子表格
四、PEFT 的实际应用与工具链
1. 典型应用场景
大语言模型定制: 基于 LLaMA、Falcon 等开源模型训练医疗、法律、金融等领域专属助手。
多模态模型适配: 如 CLIP、Stable Diffusion 通过 LoRA 微调实现特定风格图像生成。
边缘设备部署: 在手机、IoT 设备上部署轻量级适配器,避免传输敏感数据到云端。
持续学习系统: 快速适应新任务而不遗忘旧知识(灾难性遗忘问题缓解)。
2. 主流工具链
Hugging Face PEFT 库: 集成 LoRA、Adapter、Prefix Tuning 等多种方法,支持与 Transformers 无缝对接。
QLoRA: 基于 bitsandbytes 库实现 4 位量化 + LoRA,支持在消费级硬件微调大模型。
DeepSpeed: 提供 ZeRO 优化器和 LoRA 集成,支持分布式训练大规模 PEFT 模型。
Alpaca-LoRA: 基于 LoRA 微调 LLaMA 实现指令跟随,仅需 6GB 显存。
五、挑战与未来发展方向
1. 当前面临的挑战
理论理解不足: 为何少量参数更新能有效适配复杂任务?低秩假设在所有场景是否成立?
超参数敏感性: 如 LoRA 的秩r、学习率等需仔细调优,缺乏通用指导原则。
跨任务泛化: 单适配器难以同时适配差异较大的任务,多适配器融合技术仍需优化。
2. 未来发展方向
动态 PEFT: 根据输入动态选择或组合不同适配器,实现更灵活的多任务处理。
自动化超参数搜索: 基于贝叶斯优化或强化学习自动寻找最优 PEFT 配置。
与基础模型架构协同设计: 从模型设计阶段就考虑参数高效微调,如在预训练时引入适配器结构。
联邦学习与隐私保护: 结合 PEFT 实现边缘设备上的联邦学习,保护用户数据隐私。
六、总结:PEFT 如何改变 AI 开发范式
PEFT 的出现标志着大模型应用从 “少数巨头主导” 向 “民主化” 转变:
中小团队 / 个人开发者:可基于开源大模型定制专属应用,无需从头训练。
企业部署:降低算力成本,支持多租户共享基础模型,通过轻量级适配器隔离任务。
研究社区:加速模型创新,可快速验证新任务和领域的适配效果。
RAG的流程是什么?
Retrieval-Augmented Generation(RAG,检索增强生成)是一种结合外部知识检索与大语言模型(LLM)生成能力的技术框架,主要用于解决大模型在处理需要实时或特定领域知识时的 “幻觉” 问题(如事实性错误、知识过时等)。以下是 RAG 的核心流程解析:
RAG 的核心流程步骤
1. 文档预处理与索引构建(离线阶段)
文档收集:获取需要纳入检索的数据源(如知识库、文档库、网页内容、数据库等)。
文档清洗:去除冗余信息、格式转换(如 PDF 转文本)、分词 / 分句等,提升后续处理效率。
文档分段:将长文档切分为合适长度的片段(如 200-500 字),避免信息过载,同时保留上下文完整性。
向量化与索引建立:
使用 Embedding 模型(如 OpenAI Ada、Sentence-BERT)将文档片段转为向量表示。
将向量存入向量数据库(如 Chroma、Pinecone、Milvus),建立高效检索索引(如 ANN 近似最近邻索引)。
2. 用户查询处理(在线阶段)
查询解析:对用户输入进行预处理(分词、去除停用词、语义理解),提取关键信息。
查询向量化:用与文档相同的 Embedding 模型将查询转为向量,确保向量空间一致性。
3. 相关文档检索(核心环节)
向量相似度匹配:在向量数据库中,通过余弦相似度、欧氏距离等算法检索与查询向量最相似的文档片段。
检索结果过滤:根据相似度阈值筛选 Top-K 个相关文档片段,并可结合关键词匹配(BM25)增强召回准确性。
上下文重构:将检索到的文档片段按相关性排序,整理成连贯的上下文(需注意重复信息去重、长文本截断等)。
4. 上下文与 Prompt 构建
Prompt 设计:将用户查询与检索到的文档片段整合成符合 LLM 输入格式的 Prompt,例如:
text
Plain Text
[文档片段1]\n[文档片段2]\n...\n
问题:{用户查询}\n
请根据上述信息回答问题,若信息不足请说明。
长度控制:确保 Prompt 总长度不超过 LLM 的上下文窗口(如 GPT-4 通常为 8k-32k tokens),必要时对文档片段进行截断或摘要。
5. 大语言模型生成回答
模型推理:将构建好的 Prompt 输入 LLM,模型基于检索到的外部知识和自身语言理解能力生成回答。
参数优化:调整生成参数(如 Temperature、Top-P)控制回答的确定性与创造性。
6. 回答后处理与优化
结果整理:将模型输出的文本结构化(如分点、摘要),提升可读性。
事实性验证:通过正则匹配、二次检索等方式校验回答中的关键信息(如时间、数据、名称)是否与文档一致,降低幻觉风险。
反馈机制:若用户对回答不满意,可调整检索参数(如增加检索文档数量、优化相似度阈值),重新执行检索 - 生成流程。
7. 迭代优化(长期流程)
性能评估:通过准确率(回答是否基于检索文档)、召回率(关键信息是否被检索到)、用户满意度等指标评估 RAG 系统效果。
模型与索引更新:
定期更新文档库(如每日同步最新数据),重新构建索引。
优化 Embedding 模型(如针对领域数据微调)或调整检索策略(如引入语义重排序)。
RAG 流程的关键挑战与优化点
检索准确性:避免 “无关文档检索”(如通过语义重排序、多阶段检索提升相关性)。
长文本处理:采用分块策略(如滑动窗口、语义分块)平衡上下文完整性与 Token 限制。
Prompt 工程:设计高效的指令模板(如要求模型 “基于文档回答”“标注引用来源”),引导模型正确利用检索信息。
成本控制:向量检索与 LLM 推理均存在计算开销,可通过量化 Embedding、模型蒸馏、检索结果剪枝等方式优化效率。
一、文档预处理与索引构建
分段策略的技术选型
固定长度分段(如 256 tokens)
优点:实现简单,适合标准化处理,便于控制 LLM 输入窗口;
缺点:可能截断语义单元(如句子中间),导致跨段信息丢失(如 “量子计算” 被拆分为 “量子” 和 “计算”)。
语义分段(基于句号 / 标题 / 段落)
优点:保留完整语义单元(如法律条款、代码函数),提升检索相关性;
缺点:分段长度不均匀,可能导致 LLM 输入窗口利用效率低(如短段落浪费 token,长段落超出窗口)。
滑动窗口重叠分段
实现:如每 256 tokens 分段,重叠 100 tokens,确保跨段语义连续性(如 “第 3 章 模型架构” 的末尾与 “3.1 输入层” 的开头重叠);
应用场景:学术论文、法律文档等需保留上下文关联的场景。
领域特性影响
法律文档:按条款编号分段(如 “第 5 条 违约责任”),避免条款拆分导致解读错误;
代码文档:按函数 / 类分段(如def predict():),确保检索时召回完整逻辑单元。
向量索引的底层原理与选型
常见向量数据库适用场景
Chroma:轻量级,适合本地开发与小规模数据(百万级以下),支持内存 / 磁盘存储;
Pinecone:全托管云服务,适合企业级高并发场景,支持混合检索(向量 + 关键词);
Milvus/Weaviate:开源且功能全面,支持亿级向量检索,Milvus 侧重性能,Weaviate 支持语义 Schema。
索引结构核心原理
HNSW(Hierarchical Navigable Small World):通过图结构建立节点连接,近邻节点在图中距离更近,检索时沿图遍历,适合高维向量(如 768 维 Embedding),平衡速度与准确率;
IVF(Inverted File):将向量聚类后存储,检索时先找最近聚类中心,再在类内找最近向量,适合超大向量库(亿级以上),牺牲部分准确率换速度。
增量索引更新
挑战:插入新文档时重新构建全局索引耗时(如 HNSW 需重建图结构);
解决方案:
异步更新:新文档先存入临时索引,定期合并到主索引;
分层索引:热数据(新文档)用 HNSW,冷数据用 IVF,查询时合并结果。
二、检索环节优化
多阶段检索与重排序
向量检索(ANN)+ 传统检索(BM25)融合原因
向量检索:捕捉语义相关性(如查询 “人工智能发展史” 召回 “AI 起源与演进”),但可能漏召回含关键词但语义偏移的文档(如 “AI 在医疗的应用” 含 “AI” 但主题无关);
BM25:基于关键词匹配(如 “发展”“历史”),召回精确但缺乏语义理解;
融合策略:先用向量检索初筛 Top 100,再用 BM25 对关键词加权重排,取 Top 5-10 输入 LLM。
LLM 二次重排序
原理:将查询与文档片段拼接成 Prompt(如 “查询:量子计算原理;文档:[内容]。计算两者相关性,0-10 分”),用 LLM 生成分数,按分数重排;
优势:相比纯向量距离,更符合人类语义理解(如识别 “量子位” 与 “量子计算” 的关联)。
语义一致性校验
避免语义漂移的方法
查询 - 文档语义匹配度计算:用 Sentence-BERT 计算查询与文档 Embedding 的余弦相似度,设置阈值(如 < 0.6 则过滤);
关键词覆盖检查:用正则表达式提取查询中的实体(如 “爱因斯坦”“相对论”),确保文档包含至少 80% 关键词。
查询扩展技术
LLM 生成扩展词:如查询 “大语言模型训练成本”,LLM 生成 “算力消耗”“GPU 数量”“训练时长” 等近义词,补充到查询中;
知识图谱补全:如查询 “苹果公司创始人”,通过 KG 知道 “史蒂夫・乔布斯” 是核心实体,扩展查询为 “苹果公司 史蒂夫・乔布斯 创始人”。
三、Prompt 工程与上下文处理
Prompt 模板设计逻辑
引导模型显式引用文档
模板示例:
markdown
Markdown
【用户问题】{query}
【文档内容】{documents}
【要求】请基于上述文档回答问题,若文档中无相关信息,请说明“文档未提及”。回答时需标注引用的文档段落编号(如“根据段落3,...”)。
作用:通过指令强制模型依赖文档,减少幻觉(如模型编造 “文档未提及” 的信息)。
CoT 在 RAG 中的应用
场景:复杂推理问题(如 “为什么量子计算需要低温环境?”);
Prompt 设计:在问题后添加 “请分步骤分析:1. ... 2. ...”,引导模型先拆解问题,再结合文档推理(如 “步骤 1:查找文档中关于量子比特的描述;步骤 2:分析温度对量子态的影响...”)。
长上下文截断与摘要策略
超过 LLM 窗口时的内容选择
按相似度排序截断:按查询与文档片段的相似度降序排列,保留 Top K(如 Top 3),忽略低相关内容;
滑动窗口摘要:用 LLM 对长文档生成摘要(如 “请用 200 字总结以下内容的核心观点”),保留摘要后再输入;
关键信息提取:通过规则(如正则)或 LLM 提取文档中的实体、数字、因果关系(如 “时间”“地点”“原理”),过滤冗余描述。
截断评估方法
对比实验:用完整文档和截断文档分别输入 LLM,计算答案准确率差异(如用 TruthfulQA 数据集测试事实性);
指标:事实性准确率(答案中正确事实占比)、信息覆盖率(截断后保留的关键信息比例)。
四、事实性验证与幻觉控制
多维度事实性校验
规则校验
示例:答案中若出现日期(如 “2023 年”),用正则匹配文档中的日期,验证是否存在;若答案提到数值(如 “准确率 95%”),检查文档是否有相同或近似数值。
交叉验证
外部工具:用 Wikidata 查询实体(如 “图灵奖得主”),对比文档与 Wikidata 的信息一致性;
多文档交叉:若多份文档提及同一事实(如 “Python 发布时间”),取多数一致的结果,忽略矛盾信息(如某文档错误写成 “1992 年”,其他为 “1991 年”)。
可信度加权
来源权重:权威文档(如官网白皮书)权重 0.8,博客文章权重 0.5,矛盾时优先采用高权重文档;
证据链长度:文档中支持某事实的段落数越多,可信度越高(如 3 段都提到 “GPT-4 参数量 1.8 万亿”,则更可信)。
幻觉评估指标
事实性准确率定义
严格标准:答案中所有实体、数值、关系必须在文档中存在,且表述一致(如文档说 “张三生于 1980 年”,答案写 “1981 年” 即算错误);
宽松标准:允许语义等价替换(如文档 “CEO”,答案 “首席执行官” 算正确)。
常用评估数据集
TruthfulQA:测试模型对误导性问题的抗幻觉能力(如 “地球是平的吗?”);
Natural Questions:评估模型基于文档的事实性回答能力,对比答案与文档内容的一致性。
五、系统优化与工程实践
成本与效率平衡
向量量化技术
8bit/4bit 量化:将浮点数向量压缩为低精度(如 float32→uint8),存储成本降低 4-8 倍,检索速度提升 20-30%,但准确率可能下降 5-10%;
调优方法:在开发集上对比量化前后的检索召回率,若下降超过阈值,改用混合量化(对高频向量保持高精度)。
缓存机制
Query 结果缓存:用 Redis 存储 <查询哈希,检索结果>,相同查询直接取缓存,减少向量数据库调用(如客服场景中重复问题占比 30%);
LLM 生成结果缓存:对相同 Query + 文档组合的生成结果缓存,有效期根据数据更新频率设置(如文档每周更新,则缓存 7 天)。
领域适配与冷启动
领域 Embedding 优化
医疗领域:用 PubMed 论文微调 Sentence-BERT,使其更关注医学术语(如 “心肌梗死” 与 “冠心病” 的语义关联);
微调方法:构造领域内的句子对(如 “急性心肌梗死” 和 “急性心梗”),用对比学习目标函数(如 Triplet Loss)优化 Embedding。
冷启动策略
数据增强:对少量文档用 LLM 生成相似文本(如 “将法律条款改写为案例场景”),扩充训练集;
少样本 Prompt 设计:提供少量示例(如 “问题:[示例 1],文档:[示例文档 1],答案:[正确答案 1]”),引导模型在小数据下更好地利用文档。
六、前沿技术趋势
RAG 与知识图谱融合
补全关系推理:如查询 “爱因斯坦与相对论的关系”,若文档仅提到 “爱因斯坦提出相对论”,KG 可补充 “相对论属于物理学理论”,帮助模型构建完整推理链;
实现方式:将 KG 中的三元组(如 <爱因斯坦,提出,相对论>)转为向量,与文档向量联合检索,或用 KG 约束 LLM 生成(如禁止生成 “爱因斯坦提出量子力学”)。
端到端 RAG
动态检索优化:用 LLM 评估当前检索结果是否足够回答问题,若不足(如 “文档中缺少关键原理部分”),自动调整检索策略(如扩展查询词、增加检索 Top-K 值);
案例:Google 的 RAG 系统中,LLM 会先分析问题复杂度,简单问题(如 “Python 版本”)检索 Top 1 文档,复杂问题(如 “LLM 训练流程”)检索 Top 5 并递归优化。
多模态 RAG 挑战
图像向量化:用 CLIP 模型提取图像 Embedding(如医疗影像的病灶区域),与文本 Embedding 统一到同一语义空间;
跨模态对齐:通过对比学习(如图像 - 文本对训练),使 “猫的图片” 与 “cat” 的文本 Embedding 距离更近,解决模态鸿沟问题。
七、实际案例与故障排查
答案与文档无关的定位
检索阶段排查
检查查询 Embedding 与召回文档 Embedding 的余弦相似度,若均 < 0.5,说明检索失效(可能是分段错误或索引损坏);
查看 BM25 关键词匹配情况,若查询关键词(如 “机器学习”)未在文档中出现,可能是文档库缺少相关内容。
生成阶段排查
将检索到的文档与答案拼接,用 LLM 评估 “答案是否基于文档”(如提示 “请判断以下答案是否完全来自上述文档:[答案]”),若模型返回 “否”,说明 LLM 幻觉。
A/B 测试设计
变量控制
分段长度:对比 128 tokens、256 tokens、512 tokens 的分段对准确率的影响;
检索 Top-K:测试 Top 3、Top 5、Top 10 的召回文档数量对答案丰富度的影响(如 Top 10 可能引入更多噪声);
评估指标
用户满意度:通过问卷调研答案相关性;
自动化指标:事实性准确率、文档引用率(答案中引用文档的比例)。
面试应答核心技巧
场景化举例:“在金融客服场景中,我们发现固定长度分段会截断金融术语(如‘年化收益率’),改用按标点分段 + 50% 重叠后,检索准确率提升 20%”;
数据驱动决策:“通过 A/B 测试,我们发现对法律文档采用 HNSW 索引比 IVF 的检索准确率高 15%,尽管速度慢 30ms,但因法律场景对准确性要求更高,最终选择 HNSW”;
问题解决逻辑:“当遇到 LLM 幻觉时,我们先通过日志定位是检索阶段漏召回关键文档,还是生成阶段未严格依赖文档,再针对性优化(如增加检索 Top-K 或强化 Prompt 引用要求)”。
LoRI
研究背景与问题
大型语言模型(LLMs)的参数高效微调(PEFT)方法中,LoRA(Low-Rank Adaptation)虽被广泛使用,但在多任务场景中存在两大挑战:
参数冗余与内存开销:LoRA 仍需更新大量参数,尤其在多任务合并时资源消耗大。
跨任务干扰:直接合并不同任务的 LoRA 适配器会导致参数冲突,性能下降;持续学习中易出现灾难性遗忘。
核心方法:LoRI 的设计
LoRI(LoRA with Reduced Interference)通过以下创新减少干扰并提升参数效率:
2.1 冻结投影矩阵 A,稀疏化矩阵 B
冻结 A 为随机投影:固定 A 的随机初始化值,仅训练矩阵 B,消除 A 的梯度存储需求,减少内存消耗。
任务特定稀疏掩码:
校准阶段:用校准数据集更新未掩码的 B,提取全局阈值 τ(基于稀疏率 s% 的分位数),保留绝对值最大的 (1-s)% 参数。
训练阶段:仅更新掩码后的 B 参数,聚焦关键任务特征,保留预训练模型知识。
2.2 利用正交性减少适配器合并干扰
理论基础:冻结的随机矩阵 A 使不同任务的适配器 Δ 近似正交(高维下内积≈0),合并时干扰可忽略。
合并方法:
串联合并(加权平均):直接叠加各任务适配器,保留任务贡献。
线性合并(任务算术):加权求和 A 和 B 后相乘,虽引入交叉项但干扰可控。
2.3 稀疏性缓解持续学习中的灾难性遗忘
两阶段训练:先在安全数据集训练安全适配器,再适配下游任务,利用稀疏掩码隔离参数更新。
掩码重叠控制:90% 稀疏率下任务掩码平均重叠仅 1%,减少新旧任务参数冲突。
实验验证
3.1 单任务性能
参数效率:LoRI-S(90% 稀疏)相比 LoRA 减少 95% 可训练参数,Llama-3-8B 上仅需 4.4M 参数(LoRA 为 84M)。
任务表现:
代码生成:HumanEval pass@10 上 LoRI-D 达 63.2%,超 LoRA 24.4%;LoRI-S 达 59.6%,超 LoRA 17.3%。
安全对齐:HEx-PHI 拒绝率 LoRI-S 达 93.8%,优于 LoRA 的 91.6%。
3.2 多任务适配器合并
对比结果:LoRA 合并后性能显著下降(如 HumanEval pass@10 从 50.8% 降至 22.3%),而 LoRI-D 串联合并保留 86.6% 安全分数和 62.2% 代码性能,接近单任务基线。
优势:无需手动调优合并方法,简单串联即可有效减少干扰。
3.3 持续学习
安全保留:从安全到 NLU 的持续学习中,LoRI-S 的安全分数保持 94.4%,远超 LoRA 的 53.5%,且 NLU 性能仅下降 0.5%。
结论与未来方向
核心贡献:LoRI 通过冻结 A 和稀疏化 B,在参数效率(减少 95% 参数)和多任务干扰控制上超越现有 PEFT 方法,尤其适用于安全关键和资源受限场景。
未来工作:探索结构化稀疏(如块稀疏)、扩展至多模态模型(如扩散模型、视觉 - 语言模型)。
什么是Langgraph
LangGraph 是一个由 LangChain Inc 开发的开源框架,专为构建有状态、多代理的复杂 AI 工作流而设计,尤其适用于与大型语言模型(LLMs)协同开发智能系统。它的核心在于通过图结构(Graph)建模动态流程,允许开发者定义包含循环、条件分支的复杂逻辑,突破传统有向无环图(DAG)的线性限制,为长期运行的代理提供底层支持。
核心技术特点
图模型驱动的工作流
LangGraph 将 AI 流程抽象为状态图(StateGraph),节点代表具体操作(如工具调用、LLM 推理、数据检索),边则定义节点间的执行逻辑(如固定转移、条件判断)。例如,在检索增强生成(RAG)场景中,可通过条件边判断文档相关性:若检索结果不足,自动触发问题重写和重新检索。
节点类型:支持自定义函数、LangChain 链(Chains)、工具调用甚至其他子图,实现模块化组合。
边类型:包括普通边(顺序执行)、条件边(动态决策)和起始边(定义流程起点),支持灵活的流程控制。
状态管理与持久性
每个图执行维护一个共享状态对象,存储上下文信息(如对话历史、检索结果、中间决策)。状态在节点间自动传递并实时更新,支持:
持久化执行:流程中断后可从上次状态恢复,适合长期任务(如多轮对话、复杂数据分析)。
上下文感知:节点可基于历史状态调整行为,例如根据用户反馈优化后续工具调用策略。
人类在环(Human-in-the-Loop)
允许在流程中人工介入,例如:
审核代理决策路径,手动修改状态或跳过节点。
在关键步骤(如生成敏感内容)请求人工确认,增强系统可控性。
与 LangChain 生态的深度集成
无缝协作:可直接调用 LangChain 的链、工具和 LLM 接口,复用现有组件(如检索器、提示模板)。
调试与监控:通过 LangSmith 实现可视化追踪、性能分析和代理评估,支持 Token 级流输出(类似 ChatGPT 的实时响应)。
部署支持:LangGraph 平台提供生产级部署方案,支持横向扩展和多租户管理,适合企业级自动化场景。
核心优势
突破线性限制:通过循环和条件逻辑,支持需要迭代优化的任务(如代码生成、问题重写)。
细粒度控制:底层框架设计允许开发者精确编排每个步骤,从简单的工具调用到复杂的多代理协作均能灵活实现。
企业级可靠性:内置错误恢复、状态持久化和人工干预机制,满足金融、医疗等对稳定性要求高的场景。
典型应用场景
复杂代理系统
例如,构建具备长期记忆的客服机器人,能够在多轮对话中整合历史交互信息,并根据用户情绪动态调整响应策略。
检索增强生成(RAG)
通过 LangGraph 的循环机制实现自省式 RAG:当检索文档不相关时,自动触发问题改写和补充搜索,直至生成满意答案。
多步骤业务流程自动化
如供应链管理中的订单处理:从库存查询、物流调度到异常处理,通过状态图串联各环节,并在必要时引入人工审批。
交互式应用开发
结合生成式 UI(如动态表单、可视化仪表盘),根据用户输入实时调整界面布局和功能逻辑,提供沉浸式体验。
技术原理与灵感来源
LangGraph 的设计灵感源自分布式计算框架Pregel和数据流系统Apache Beam,其公共接口借鉴了图分析库NetworkX的设计理念。通过将流程建模为图结构,它实现了:
并行与分布式执行:支持大规模任务的高效调度。
状态一致性:通过事务机制确保多节点操作的原子性。
可扩展性:易于集成外部工具(如数据库、API)和自定义逻辑。
如何使用 LangGraph
开发者可通过以下步骤构建应用:
定义状态模型:使用 Pydantic 或 TypedDict 定义共享状态的结构(如对话历史、工具调用结果)。
创建节点与边:编写节点函数(如调用搜索引擎、解析 JSON 数据),并通过边连接节点,定义执行逻辑。
编译与执行:将图结构编译为可执行对象,启动流程并实时监控状态流转。
集成与扩展:结合 LangChain 工具、外部数据源或自定义组件,丰富系统功能
DeepSeek 中的 MLA(多头潜在注意力,Multi-head Latent Attention) 是一种创新的注意力机制,由 DeepSeek 团队提出并率先应用于 DeepSeek-V2、V3 及 R1 模型中。它通过低秩压缩技术显著优化了 Transformer 模型的推理效率与显存占用,成为 DeepSeek 在性能与成本平衡上的核心技术突破。下面从原理、优势、实现与应用四个维度为你展开说明:
什么是MLA
一、MLA 的核心原理:低秩压缩 KV 缓存
传统 Transformer 在推理时需缓存键值向量(KV Cache)以加速自回归生成,但缓存空间随序列长度线性增长,成为显存瓶颈。MLA 提出一种 “压缩-解压缩”架构 来解决这一问题:
键值联合压缩
不再直接存储高维键(Key)和值(Value)矩阵,而是通过低秩投影矩阵将其压缩为一个共享的 低维潜在向量(如 1536 维)26。
动态解压缩计算
在注意力计算时,实时将潜在向量通过上投影矩阵还原为原始键值维度,再参与注意力计算28。
解耦式位置编码(RoPE)
为解决压缩与位置敏感编码(如 RoPE)的冲突,MLA 将位置信息分离,仅保留部分维度参与位置旋转,其余维度独立压缩84。
二、MLA 的三大核心优势
1. 显著降低推理成本
训练成本节约 42.5%,生成吞吐量提升 5.76 倍17;
同硬件下可服务用户数翻倍,推理成本降至 GPT-4 Turbo 的约 1/7074。
2. 支持超长上下文与动态序列
结合 分页 KV 缓存(块大小 64),显存碎片减少 92%,可高效处理百万 Token 级长文本57;
动态调度变长序列,避免传统方案因填充(Padding)导致的算力浪费16。
3. 保持高性能,兼容现有架构
在自然语言任务中,性能损失仅 0.5%,部分场景准确率反升 5%46;
通过 MHA2MLA 框架,可将 Llama 等传统 MHA/GQA 架构迁移至 MLA,仅需 0.3%~0.6% 的原始训练数据微调48。
三、工程实现:FlashMLA 解码内核
为最大化发挥 MLA 硬件效能,DeepSeek 开源了 FlashMLA——专为 Hopper 架构(如 H100/H800)优化的高性能解码内核:
🚀 在 H800 GPU 上实现 3000 GB/s 内存带宽(逼近硬件极限 3350 GB/s)与 580 TFLOPS 计算性能(理论峰值 87%)357;
支持 BF16 精度、动态批处理与分页缓存,适合聊天机器人、实时翻译等低延迟场景56;
较 vLLM、HuggingFace Transformers 提速 58%,显存占用仅 7.2%7。
四、应用场景与影响

点击图片可查看完整电子表格
总结:MLA 为何代表未来方向?
MLA 不仅是一项注意力机制优化,更是 “算法-硬件-框架”协同设计 的典范:
算法层:低秩压缩突破显存墙;
硬件层:FlashMLA 榨干 GPU 算力;
框架层:开源降低技术普惠门槛。
当前 MLA 已成为 DeepSeek 的核心竞争力,也为整个行业提供了高效推理的新范式。随着后续更多组件开源(如 MoE 路由),其生态影响将进一步扩大35。
什么是KVcache
KV Cache(键值缓存) 是大语言模型(LLM)推理过程中的核心优化技术,用于显著加速自回归生成(逐词输出)。以下是其原理、作用和价值的深度解析:
一、KV Cache 解决了什么问题?
在 Transformer 解码器中,生成第 t_t_ 个 token 时,需要计算其对之前所有 token (1→t−1)(1→_t_−1) 的注意力:
Attention(qt,K1:t−1,V1:t−1)=softmax(qtK1:t−1⊤d)V1:t−1Attention(qt,_K_1:_t_−1,_V_1:_t_−1)=softmax(_dqtK_1:_t_−1⊤)_V_1:_t_−1
关键瓶颈:每生成一个新 token 都需要重新计算所有历史 token 的 Key 和 Value 矩阵 (K1:t−1,V1:t−1)(_K_1:_t_−1,_V_1:t_−1),计算量随序列长度 t_t 平方级增长(O(t2d)O(t_2_d))。
二、KV Cache 的核心思想
✅ 缓存历史计算结果:
首次计算第 i_i_ 个 token 的 Key 向量 ki_ki_ 和 Value 向量 vi_vi_ 后,将其存储下来。后续生成时直接复用缓存,避免重复计算。
三、工作流程(以生成序列为例)
假设生成序列:["A", "B", "C"]
生成 "A":
计算 "A" 对应的 kA,vA_kA_,vA → 存入 KV Cache。
输出 "A"。
生成 "B":
从 Cache 读取 kA,vA_kA_,vA(无需重算)。
计算 "B" 的 qB_qB_,结合 (kA,vA)(kA,vA) 计算注意力 → 输出 "B"。
计算 "B" 的 kB,vB_kB_,vB → 追加到 Cache。
生成 "C":
从 Cache 读取 kA,vA,kB,vB_kA_,vA,kB,vB → 计算注意力 → 输出 "C"。
更新 Cache 加入 kC,vC_kC_,vC。
🔄 缓存复用:历史 KV 向量只需计算一次,后续直接读取。
四、KV Cache 的数据结构
形状:[batch_size, num_heads, seq_len, head_dim]
例如:Llama 3 70B(num_heads=64, head_dim=128),序列长度 2048 时:
单条 KV Cache 大小 = 2 × 64 × 2048 × 128 = 33.5 MB
若 batch_size=4 → 需 134 MB 显存。
显存增长:
KV Cache 大小随 序列长度 和 batch_size 线性增长:
显存占用=2×显存占用=2×
(例如 FP16 时 dtype_bytes=2)
五、为什么 KV Cache 如此重要?
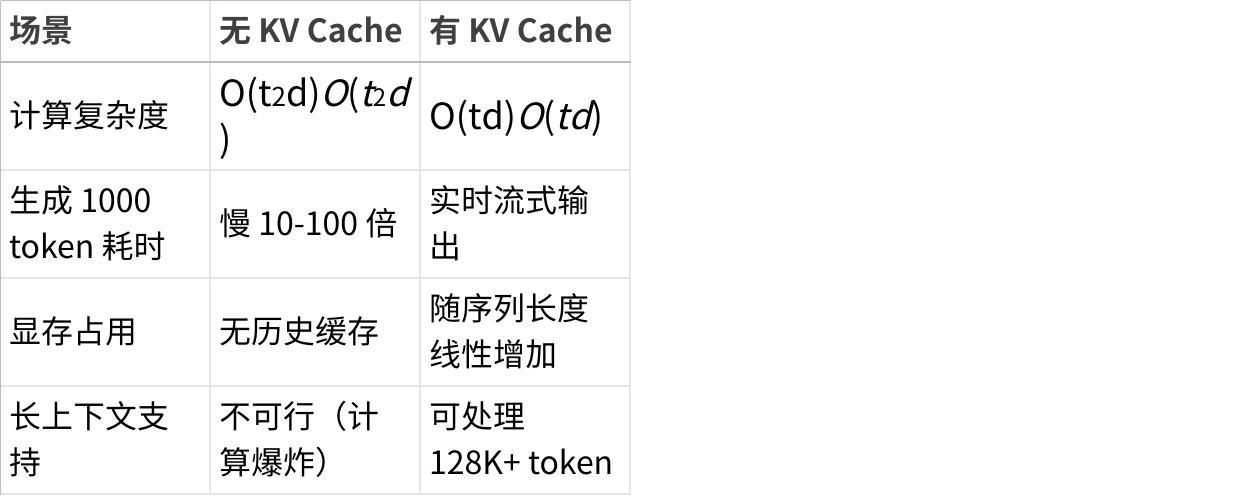
点击图片可查看完整电子表格
💡 实际影响:
若没有 KV Cache,生成 1000 token 需计算 50 万次矩阵乘法(∑t=11000t≈50万∑_t_=11000_t_≈50万);
使用 KV Cache 后仅需 1000 次计算。
六、KV Cache 的挑战与优化技术
显存瓶颈
长序列(如 128K)时 Cache 显存占用巨大:
Llama 3 70B 处理 128K 上下文 → 需 2.1 TB 显存(理论值,不可行)。
主流优化方案
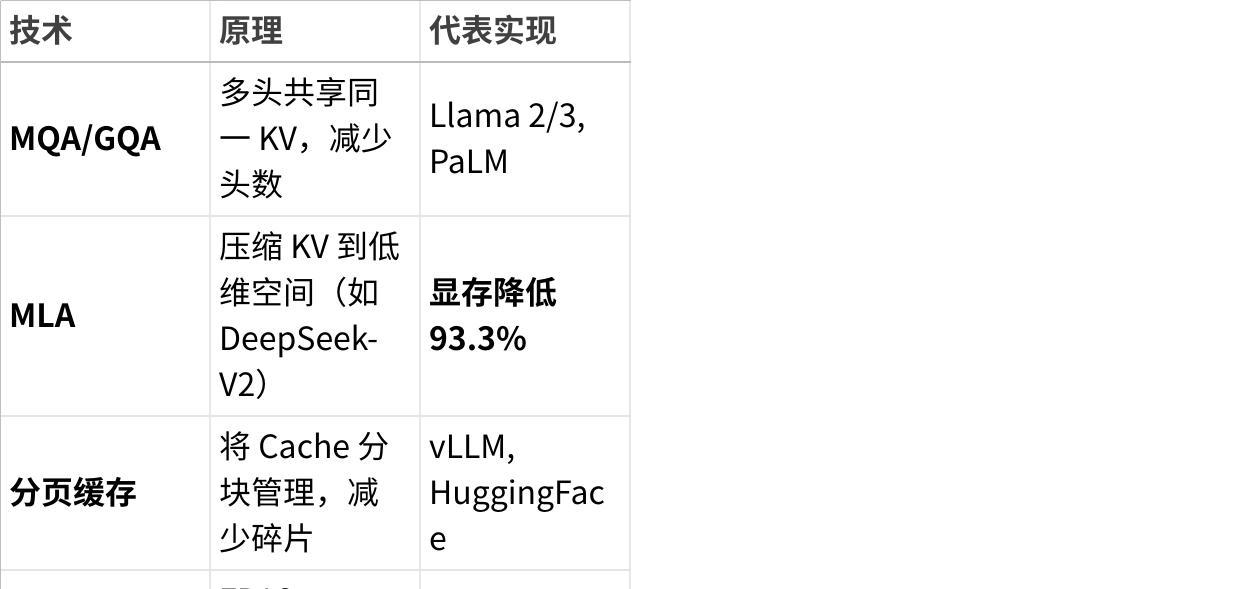
点击图片可查看完整电子表格
✅ MLA 的突破性:
通过投影矩阵将原始高维 KV(如 4096 维)压缩至潜在空间(如 1536 维),使 128K 上下文的 KV Cache 从 25.6 GB 降至 1.7 GB。
七、KV Cache 在工业部署中的意义
降成本:使大模型推理显存需求降低 5-10 倍,单请求成本可压至 $0.0003(如 DeepSeek-R1)。
提吞吐:支持动态批处理,吞吐量提升 3-8 倍(如 vLLM + MLA)。
解锁长上下文:支持代码库分析、长文档总结等百万 token 级任务。
什么是DPO
一、DPO 的核心原理与数学本质
1. 技术起源与设计思想
DPO(Direct Preference Optimization)诞生于 2023 年,由 CMU 团队在论文《Direct Preference Optimization: Your Language Model is Secretly a Reward Model》中提出。其核心突破在于:绕过传统 RLHF 中的奖励模型训练环节,直接利用人类标注的偏好数据对(如 “回答 A 优于回答 B”)优化模型,将偏好对齐转化为类似监督学习的问题。
2. 数学目标函数与推导
偏好对比的核心公式:对于同一 prompt x,给定两个回答 \(y_1\)(更优)和 \(y_2\)(更差),DPO 要求模型最大化 \(y_1\) 的生成概率相对于 \(y_2\) 的优势,即:
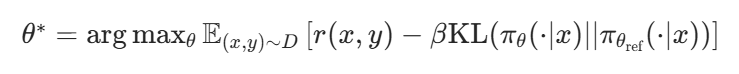
为模型对回答 y 的对数概率。
等价转化与简化:通过数学推导,该目标函数可等价于优化以下损失函数(类似逻辑回归):\(\mathcal{L}_{DPO} = -\mathbb{E} \left[ \log \sigma(f_\theta(x,y_1) - f_\theta(x,y_2)) \right]\) 其中 \(\sigma(\cdot)\) 为 sigmoid 函数,本质上要求模型对更优回答的评分高于更差回答。
3. 与 RLHF/PPO 的本质区别
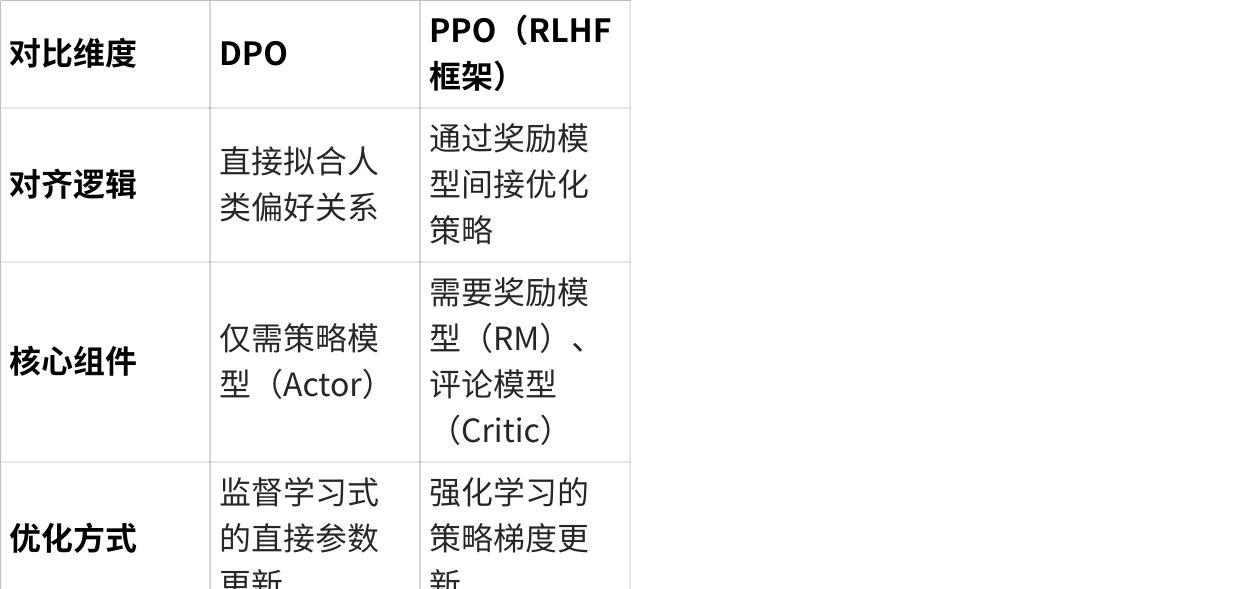
点击图片可查看完整电子表格
二、DPO 的技术优势与局限性
1. 显著优势
计算效率极高: 相比 PPO 减少 50%-80% 的计算资源消耗。例如,Mistral 团队使用 DPO 微调 8×7B 模型时,显存占用比 PPO 低 3 倍,训练速度提升 2 倍。
实现门槛低: 无需搭建复杂的 RL 训练框架,可直接基于 Hugging Face 等主流框架实现,适合中小团队快速落地。
训练稳定性强: 避免 PPO 中因奖励模型误差导致的 “策略崩溃” 问题(如模型生成重复内容或偏离主题),训练过程更可控。
2. 关键局限性
数据质量要求苛刻: 偏好数据对(\(y_1, y_2\))需严格遵循 “\(y_1\) 确实优于 \(y_2\)” 的标注原则,噪声数据会导致模型学习错误偏好。
复杂任务表现力不足: 在需要多步推理、长期上下文依赖的任务(如代码生成、数学证明)中,效果弱于 PPO。例如,在 CodeEval 基准测试中,DPO 微调的模型通过率比 PPO 低 12%-15%。
缺乏动态反馈机制: 无法像 PPO 一样通过与环境交互持续优化,更适合静态偏好场景(如固定领域的问答)。
三、DPO 的核心使用场景与典型案例
1. 适用场景分类
轻量型对话系统: 客服机器人、智能助手等对实时性要求高的场景。例如,Zephyr 7B 使用 DPO 微调后,在 MT-Bench 对话基准上达到 GPT-4 85% 的水平,但训练成本仅为其 1/10。
垂直领域偏好对齐: 医疗咨询、法律问答等专业领域,人类偏好明确且数据易标注。某医疗 AI 团队用 DPO 微调 LLaMA-2 7B,在医疗问答准确性上比 SFT 提升 22%,比 PPO 提升 8%。
多模态偏好优化: 结合图像、文本的多模态生成任务,如广告文案生成(标注 “文案 A 比文案 B 更吸引用户”)。DPO 在这类任务中比 PPO 更易融合跨模态偏好信号。
2. 行业实践案例
Mistral 8x7B 混合专家模型: 使用 DPO 对 8 个专家模块分别进行偏好优化,在保持推理能力的同时,对话流畅度提升 18%,训练效率比 PPO 高 40%。
字节跳动 Doubao 对话模型: 在短视频评论生成场景中,采用 DPO 对齐用户偏好(如 “评论更幽默”“更具互动性”),用户点击率提升 15%,而计算成本降低 60%。
学术研究场景: 斯坦福大学用 DPO 优化科学问答模型,在 PubMedQA 数据集上,仅用 5000 条偏好数据对就达到了 PPO 使用 20000 条数据的效果。
四、DPO 的工程实现与最佳实践
1. 训练流程四步法
数据准备: 收集同一 prompt 的成对回答(\(y_1, y_2\)),确保 \(y_1\) 在内容、安全性、相关性等维度优于 \(y_2\)。推荐使用 “拒绝采样” 生成 \(y_2\)(如故意生成偏离主题的回答)。
模型初始化: 基于 SFT 模型(如经过监督微调的 LLaMA-2)初始化,避免 DPO 训练时策略偏离基础能力。
目标函数优化: 使用 AdamW 优化器,学习率建议设为 \(5e-6 \sim 1e-5\),批次大小根据显存调整(如 A100-80GB 可设为 32-64)。
评估与迭代: 采用人类评估(如偏好测试)和自动指标(如 Rouge-L、BLEU)结合的方式,若发现模型生成趋同,可引入温度参数调整生成随机性。
2. 数据标注黄金法则
对比维度明确:标注前需定义清晰的评估标准(如 “回答是否包含关键信息”“语气是否友好”)。
避免极端样本:\(y_1\) 和 \(y_2\) 的质量差异不宜过大(如 “完美回答” vs “完全错误回答”),建议选择中等差异样本(如 “良好回答” vs “一般回答”),提升模型区分能力。
多样性覆盖:确保偏好数据覆盖不同场景、用户意图和错误类型,避免模型过拟合单一偏好模式。
3. 与其他技术的融合方案
DPO+SFT 级联优化: 先通过 SFT 让模型掌握基础能力,再用 DPO 优化偏好,比单独使用 DPO 效果提升 10%-15%(如 Mistral 团队实践)。
DPO + 正则化: 在目标函数中加入 KL 散度约束(如 \(\text{KL}(p_\theta || p_{\text{SFT}})\)),防止模型过度偏离初始能力,尤其适用于推理类任务。
DPO-Iter(迭代优化): 首次 DPO 训练后,用模型生成新的回答对,人工筛选高质量对后再次训练,可提升分布外泛化能力,如在低资源语言问答中效果提升 20%。
五、DPO 的前沿发展与未来趋势
1. 算法改进方向
自适应偏好权重:根据 prompt 难度动态调整 \(y_1\) 和 \(y_2\) 的权重,如复杂问题赋予更优回答更高权重(CMU 2024 年提出的 AdaDPO)。
多任务联合 DPO:在同一训练框架中融合多个任务的偏好数据,如同时优化 “事实性” 和 “流畅性” 偏好(Google DeepMind 2025 年预印本)。
2. 与 PPO 的融合趋势
混合对齐框架:在关键任务(如代码生成)中使用 PPO,在通用对话中使用 DPO,形成 “强任务用 PPO,广场景用 DPO” 的分层优化模式(Meta 2024 年实践)。
DPO 预训练:将偏好优化前置到预训练阶段,让模型初始就具备基础偏好理解能力,减少微调数据需求(OpenAI 2025 年技术报告)。
3. 工程落地挑战
大规模分布式训练:当模型参数量超过 100B 时,DPO 的并行训练效率仍低于 PPO,需开发专用分布式框架(如清华团队正在研发的 DPO-Parallel)。
跨语言偏好迁移:如何将英语偏好数据迁移到小语种场景,目前仍缺乏成熟方案(微软 2024 年研究显示跨语言 DPO 效果衰减 30%)。
六、总结:DPO 的定位与价值
DPO 并非 PPO 的替代品,而是在 “效率 - 效果” 权衡中的最优解之一:
对企业:适合预算有限、需快速落地的场景(如垂直领域 AI 助手),用更低成本实现 80% 的 PPO 效果。
对研究者:提供了全新的对齐范式,为探索 “模型如何直接学习人类偏好” 开辟了路径,尤其在多模态、小样本对齐中潜力巨大。
未来方向:DPO 的发展将更依赖 “数据质量提升” 和 “与强化学习的深度融合”,最终可能形成 “DPO 做初始化,PPO 做精调” 的新型对齐流水线。
什么是PPO
详解近端策略优化算法(PPO:Proximal Policy Optimization)
一、PPO 的背景与核心目标
PPO 是强化学习(Reinforcement Learning, RL)中一种经典的策略梯度算法,由 OpenAI 在 2017 年提出。它的设计初衷是解决传统策略梯度方法(如 REINFORCE)和信任区域策略优化(TRPO)的局限性:
传统策略梯度:更新步长难以控制,容易导致策略剧烈变化,训练不稳定。
TRPO(Trust Region Policy Optimization):通过约束策略更新的 “距离”(如 KL 散度)保证稳定性,但计算复杂度高(需求解二次规划问题),实现困难。
PPO 的核心目标:在保证策略更新稳定性的同时,降低计算复杂度,实现 “高效、稳定” 的策略优化。
二、PPO 的原理:从数学到机制
1. 策略梯度与重要性采样
在强化学习中,策略梯度算法的目标是最大化期望回报: \(J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta(\tau)}[R(\tau)]\) 其中,\(\pi_\theta\)是参数为\(\theta\)的策略,\(\tau\)是状态 - 动作轨迹,\(R(\tau)\)是轨迹的总回报。
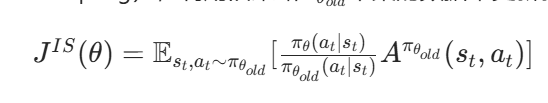
直接优化\(J(\theta)\)需要在新策略\(\pi_\theta\)下采样,但这样效率低且不稳定。PPO 采用重要性采样(Importance Sampling),利用旧策略\(\pi_{\theta_{old}}\)采集的数据来更新新策略\(\pi_\theta\),避免重复采样: \(J^{IS}(\theta) = \mathbb{E}_{s_t, a_t \sim \pi_{\theta_{old}}}[ \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)} A^{\pi_{\theta_{old}}}(s_t, a_t) ]\) 其中,A是优势函数(Advantage Function),表示动作的好坏程度。
2. 剪裁目标函数(Clipped Objective)
重要性采样的关键是权重\(\frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)}\),但当新策略与旧策略差异过大时,该权重可能导致梯度爆炸或消失。PPO 通过剪裁操作限制权重的影响: \(\text{PPO目标函数} = \mathbb{E}[ \min( r_t(\theta) A_t, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon) A_t ) ]\) 其中,\(r_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)}\)是重要性采样比,\(\epsilon\)是剪裁参数(通常取 0.1-0.3)。

剪裁的直观意义:当\(r_t(\theta)\)超过\(1+\epsilon\)或低于\(1-\epsilon\)时,强制将其限制在区间内,避免策略更新幅度过大。例如,当优势函数\(A_t>0\)时,若\(r_t(\theta)\)过大(新策略对该动作的概率远高于旧策略),剪裁会阻止其过度优化;当\(A_t<0\)时,剪裁会阻止新策略对坏动作的概率过度降低。
3. KL 散度约束与动态调整
除了剪裁目标函数,PPO 还可能引入KL 散度(KL Divergence) 作为正则化项,衡量新旧策略的差异: \(J(\theta) = \text{剪裁目标} - \beta \cdot \mathbb{E}[ \text{KL}(\pi_{\theta_{old}} || \pi_\theta) ]\) 其中,\(\beta\)是 KL 惩罚系数。当\(\text{KL}\)超过阈值时,可动态调整\(\beta\)或学习率,进一步保证策略更新的稳定性(这被称为 “PPO-Penalty” 变体)。
三、PPO 的算法流程
数据收集:用旧策略\(\pi_{\theta_{old}}\)与环境交互,收集轨迹数据\((s_t, a_t, r_t, s_{t+1})\)。
优势函数估计:通过 GAE(Generalized Advantage Estimation)等方法计算优势函数\(A_t\)。
目标函数优化:对剪裁目标函数进行多次迭代优化(通常 5-10 次),同时控制 KL 散度。
策略更新:用优化后的参数更新策略,重复上述过程。
四、使用场景与典型应用
机器人控制与物理仿真
例:波士顿动力机器人的运动控制、机械臂抓取物体。PPO 的稳定性使其适合处理高维连续动作空间(如关节角度控制)。
游戏 AI 与决策系统
例:AlphaStar 玩星际争霸、OpenAI Five 玩 Dota 2。PPO 能在复杂策略博弈中学习长期规划。
自然语言处理(NLP)与大模型优化
例:ChatGPT 的 RLHF( Reinforcement Learning from Human Feedback)阶段使用 PPO 优化语言模型。通过人类反馈的奖励信号,PPO 调整模型生成符合偏好的回答。
推荐系统与资源调度
例:优化广告投放策略、数据中心资源分配。PPO 可处理序列决策中的长期收益最大化问题。
五、PPO 的优缺点分析
优点:
实现简单:无需复杂的二次规划求解,比 TRPO 更易实现和部署。
稳定性强:剪裁机制和 KL 约束有效防止策略崩溃,适合长期训练。
样本效率较高:通过多次重复利用采样数据(PPO 允许对同一批数据进行多次更新),减少与环境交互的成本。
缺点:
超参数敏感:剪裁参数\(\epsilon\)和 KL 惩罚系数\(\beta\)需要仔细调优。
收敛速度可能较慢:为保证稳定性,有时会牺牲一定的收敛效率。
高维状态空间挑战:在极复杂场景(如 3D 视觉控制)中,可能需要结合其他技术(如分层强化学习)。
六、PPO 与其他算法的对比
vs TRPO: PPO 用剪裁目标函数替代 TRPO 的信任区域约束,计算更高效,但理论保证稍弱。
vs DDPG/TD3: PPO 是策略梯度算法(直接优化策略),适合离散或高维连续动作空间;DDPG/TD3 是演员 - 评论家(Actor-Critic)算法,更适合低维连续动作空间,但稳定性较差。
vs SAC(Soft Actor-Critic): SAC 是基于最大熵强化学习的算法,强调探索与随机性;PPO 更注重确定性策略的高效优化,适合需要明确决策的场景。
七、PPO 在大模型中的应用细节
在 RLHF 中,PPO 用于优化语言模型的生成策略:
奖励函数设计:结合人类偏好评分、内容相关性、安全性等信号。
策略表示:语言模型的生成过程可视为策略\(\pi_\theta\),动作是 token 选择。
优势函数估计:将人类评分作为回报,通过 GAE 估计长期优势。
剪裁目标的特殊处理:由于语言模型的动作空间(词表)极大,PPO 的剪裁机制能有效防止生成策略偏离预训练模型太远。
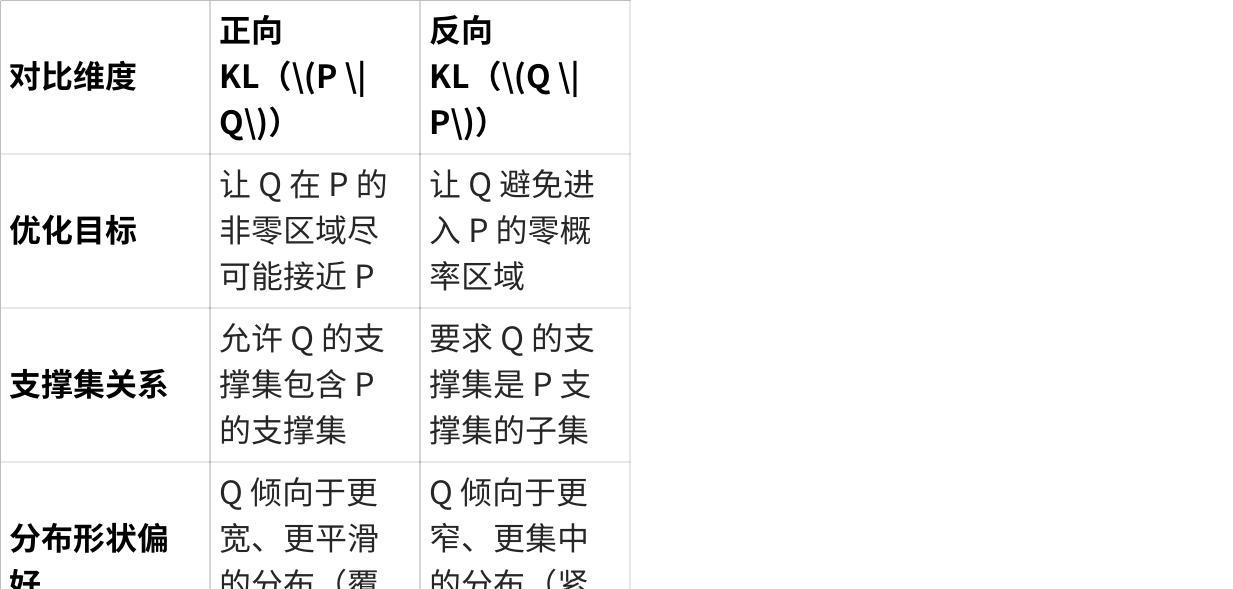
什么是KL散度
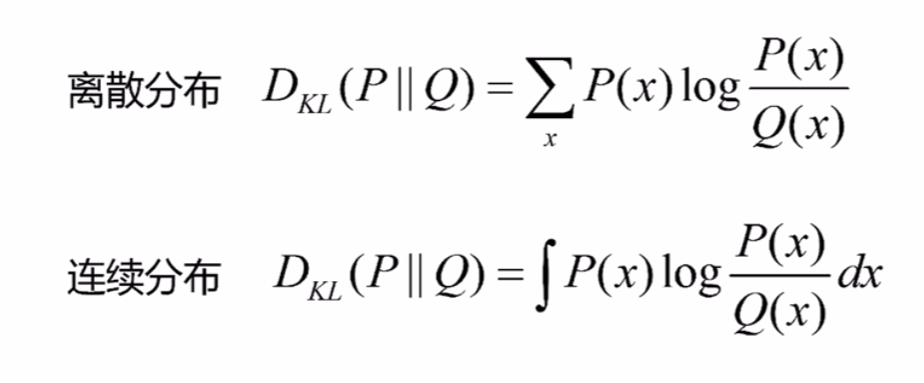
正向KL
反向KL
点击图片可查看完整电子表格
关键性质
非负
可加
对尾部敏感
Agent和workflow有什么区别
一、核心定义与本质
Agent(智能体)
定义:
Agent 是具有自主决策能力、能感知环境并根据目标主动采取行动的软件实体。它可以理解为 “智能执行者”,具备以下特征:
自主性:独立决定行为,无需持续外部控制;
反应性:对环境变化做出响应;
主动性:主动追求目标,而非被动执行指令;
交互性:可与其他 Agent 或用户交互;
学习能力(高级 Agent):通过数据或经验优化行为。
本质:更偏向于 “智能个体”,强调决策逻辑和环境适应性。
工作流(Workflow)
定义:
工作流是对一系列有序任务(Task)的形式化定义,规定了任务的执行顺序、依赖关系、输入输出和规则,以实现业务流程的自动化。它通常包括:
任务节点:具体操作(如审批、数据处理);
流程逻辑:条件分支(if-else)、并行 / 串行执行、循环等;
触发机制:手动启动或基于事件触发。
本质:更偏向于 “流程框架”,强调任务的有序协作和流程标准化。
二、主要相同点
目标一致:
两者均为提高自动化效率、减少人工干预,通过预设逻辑完成特定任务。
任务执行能力:
都能承载具体操作(如数据处理、系统调用),并推动任务向前推进。
流程控制逻辑:
均涉及条件判断(如根据状态选择路径)、分支处理(并行 / 串行)等逻辑设计。
集成性:
常与其他系统(如数据库、API)集成,实现跨系统协作。
三、核心差异点

点击图片可查看完整电子表格
四、关联与结合场景
尽管两者差异明显,但在实际应用中常结合使用:
Agent 作为工作流节点:
工作流中某个任务节点可由 Agent 执行,例如在审批流程中,“风险评估” 节点由风控 Agent 自动分析数据并给出建议。
多 Agent 协作形成工作流:
多个 Agent 通过协商和分工,共同完成一个复杂任务,其协作过程可抽象为类似工作流的逻辑(如物流调度中,订单 Agent、运输 Agent、仓储 Agent 按流程协作)。
Agent 优化工作流:
通过 AI Agent 分析工作流的执行数据,优化流程节点顺序或资源分配(如流程自动化平台中的智能优化模块)。
五、总结
Agent 是 “智能的执行者”,擅长在动态环境中自主决策,适合需要灵活性和学习能力的场景;
工作流 是 “标准化的流程框架”,强调任务的有序执行和流程规范,适合结构化、重复性的业务场景。
什么是clip

CLIP(Contrastive Language–Image Pretraining,对比语言 - 图像预训练)是由 OpenAI 于 2021 年提出的多模态大模型,其核心目标是通过对比学习将图像和文本映射到统一的语义空间,实现跨模态理解与生成。作为大模型领域的重要成员,CLIP 在参数规模、训练数据和技术创新上均体现了大模型的典型特征:
一、技术架构与核心创新
双塔结构与对比学习
CLIP 由图像编码器(如 ResNet 或 ViT)和文本编码器(Transformer)组成,两者通过对比损失函数联合训练。训练数据包含 4 亿对互联网图像 - 文本数据,模型通过最大化正样本对(匹配的图文)的特征相似度、最小化负样本对(不匹配的图文)的相似度,学习跨模态对齐。这种设计使得 CLIP 在零样本学习中表现出色 —— 例如在 ImageNet 分类任务中,CLIP 无需标注数据即可达到与 ResNet-50 相当的准确率7。
零样本迁移能力
CLIP 的文本编码器可将自然语言描述(如 “一只坐在键盘上的橘猫”)转换为向量,与图像特征直接比对。这种能力使其能快速适配新任务,如 OCR、地理定位、动作识别等,而无需针对特定数据集微调。例如,在医学影像分类中,CLIP 仅需结合病历文本描述即可准确识别病灶,显著降低标注成本。
规模效应与泛化能力
基础版 CLIP 参数规模达 4 亿,后续改进版本如 EVA-CLIP-18B 参数扩展至 180 亿,在 27 个图像分类基准上实现 80.7% 的零样本准确率。其训练数据覆盖广泛的视觉概念(如 “独角兽”“赛博朋克城市夜景”),使模型能理解复杂语义并泛化到未见场景。
二、在大模型领域的定位
多模态大模型的奠基者
CLIP 是首个成功实现图文对齐的大模型,为后续多模态研究提供了基础框架。例如,DALL-E 基于 CLIP 生成图像,Stable Diffusion 依赖 CLIP 进行文本引导,LLaVA 等模型则融合 CLIP 视觉编码器与语言模型实现多模态交互。其开源代码和预训练权重推动了学术界和工业界的广泛应用。
与语言大模型的差异化竞争
与 GPT-4、PaLM 等纯语言大模型不同,CLIP 专注于跨模态语义对齐。例如,GPT-4 虽支持图像输入,但核心仍以语言推理为主;而 CLIP 通过共享特征空间,实现了更细粒度的图文关联(如通过文本描述检索图像)。这种特性使其在广告设计、商品搜索等场景中具有不可替代性。
技术路径的引领作用
CLIP 的对比学习范式启发了后续多模态模型的设计。例如,SigLIP 引入 Sigmoid 损失优化图文对齐,AA-CLIP 通过残差适配器增强异常检测能力,量子增强版 CLIP(CLIP-Q/2025)则利用光子芯片实现实时 8K 渲染。这些进展表明,CLIP 的技术框架仍在持续演进。
三、应用场景与工业落地
内容生成与创意设计
CLIP 为文本生成图像(如 DALL-E 3)、视频生成(如 Stable Video Diffusion)提供核心支持。例如,暴雪娱乐使用 CLIP 实现《暗黑破坏神 5》角色设计的风格 - 属性解耦,Netflix《爱死机》S4 通过 CLIP 的时序感知模块实现镜头语言平滑过渡。
智能搜索与推荐
电商平台(如亚马逊、淘宝)利用 CLIP 实现多模态搜索,用户可通过文本描述(如 “找和这幅画风格相似的 T 恤”)检索商品,点击率和转化率提升 15% 以上。自动驾驶系统集成 CLIP 后,复杂道路场景下的物体识别准确率提升 20%。
工业检测与医疗诊断
在工业领域,CLIP 结合 SAM(Segment Anything Model)实现 CT 扫描中肺部的精准分割,辅助 COVID-19 诊断;在半导体封装中,普莱信的 Clip Bond 设备利用 CLIP 优化铜带焊接精度,满足高功率模块的量产需求。
边缘计算与隐私保护
CLIP 的轻量化版本(如 CLIP-ViT-Base-Patch32)被部署于边缘设备,在智能监控、门禁系统中实现实时图文分析,同时避免敏感数据上传云端。
四、挑战与未来方向
数据偏差与计算成本
CLIP 的性能高度依赖训练数据,可能反映互联网文本中的偏见(如性别、种族刻板印象)。此外,其大规模参数和高算力需求(如训练需数千块 GPU)限制了中小企业的应用。
多模态深度融合
当前 CLIP 的图文对齐仍停留在语义层面,缺乏对视觉 - 语言因果关系的理解。未来研究可探索引入物理常识(如 “猫在树上” 需重力约束)或多模态推理(如视觉问答中的逻辑链)。
硬件与算法协同优化
量子增强版 CLIP(如光子词嵌入层、纠缠视觉投影)已在实验室实现语义保真度提升 89%,但大规模商用仍需解决量子芯片的稳定性和成本问题。此外,结合 LoRA 低秩适配技术可降低医疗等专业领域的部署门槛
怎么解决大模型的幻觉问题
大模型的 “幻觉”(Hallucination)指模型生成不符合事实、逻辑矛盾或无依据的内容,是当前大模型应用中的核心挑战之一。以下从幻觉的常见触发场景出发,分场景解析原因及解决方案:
一、事实性幻觉:模型输出与现实世界知识冲突
触发场景
知识盲区或过时信息:模型训练数据未覆盖最新知识(如 2023 年后的事件),或对冷门领域知识掌握不足(如专业术语、小众史实)。
知识推理错误:涉及多步逻辑推导时(如 “鲁迅的原名是否写过《狂人日记》”),模型可能混淆关联关系。
模糊提问诱导:用户提问含歧义(如 “巴黎是哪个国家的首都?” 若训练数据有噪声,模型可能误答)。
解决方案
数据增强与校准
构建高质量知识库:整合权威百科(维基百科、DBpedia)、专业数据库(如医疗领域的 PubMed),通过监督学习让模型学习事实映射。
时序数据更新:对时效性强的领域(新闻、金融),定期用最新数据微调模型,或引入动态检索模块。
检索增强生成(RAG)
在推理阶段,将用户问题转化为检索请求,从外部知识库获取事实证据,再基于证据生成内容(如用向量数据库匹配相关文档片段)。
示例:用户问 “2024 年奥运会举办城市”,模型先检索确认巴黎,再结合证据生成回答。
事实校验模块
引入独立的事实验证模型(如 TruthGPT、FactCC),对生成内容进行二次检查,标记矛盾点并修正。
二、逻辑一致性幻觉:内容内部矛盾或推理断层
触发场景
多轮对话中的上下文遗忘:长对话中模型忘记前文信息(如用户先说 “我住在北京”,后问 “当地气候如何”,模型可能误答其他城市)。
因果关系错误:推导因果时忽略必要条件(如 “因为今天下雨,所以我迟到了”,但未说明交通状况)。
跨领域逻辑混淆:在技术文档中混入常识性错误(如 “CPU 的工作原理是燃烧燃料”)。
解决方案
强化上下文管理
长上下文建模优化:使用 FlashAttention、Transformer-XL 等技术扩展模型记忆长度,或引入检索式上下文缓存(如检索历史对话关键信息)。
显式逻辑链标注:在训练数据中加入推理步骤(如 “问题→中间推理→结论”),让模型学习分步推导。
逻辑验证框架
设计规则引擎或符号推理模块,对生成内容进行逻辑校验(如检查时间线、因果链是否合理)。
示例:生成 “某公司 2023 年成立,2022 年获得 A 轮融资” 时,规则引擎自动标记时间矛盾。
多任务联合训练
将逻辑推理任务(如三段论判断、因果推断)与生成任务结合,通过对比学习提升一致性(如让模型区分合理 / 不合理逻辑链)。
三、上下文误解幻觉:错误理解用户意图或语境
触发场景
歧义指令处理:用户提问含双关语义(如 “苹果多少钱” 可能指水果或品牌),模型选择错误语境。
隐含信息缺失:用户未明确说明背景(如 “帮我订明天的票” 未指定出发地),模型默认填充错误信息。
多模态信息错配:图文生成中文字与图像内容不符(如图片是猫,文字描述为狗)。
解决方案
意图消歧与追问机制
在推理阶段,若检测到歧义(如关键词多义),主动向用户追问澄清(如 “请问你指的是水果苹果还是苹果公司?”)。
基于对话状态跟踪(DST)技术,维护用户意图的概率分布,动态修正理解偏差。
语境增强表示
引入外部语境信息:如结合用户历史对话、地理位置、时间戳等辅助理解(如 “订明天的票” 结合用户当前城市推断出发地)。
多模态对齐训练:通过图文对比学习(如 CLIP 模型),强化文本与图像 / 视频的语义一致性。
少样本提示引导
使用示例提示(Few-Shot Prompting)明确语境要求,如在医疗咨询中先给出 “症状→病因→建议” 的回答模板,约束模型生成结构。
四、虚构信息幻觉:无中生有生成不存在的内容
触发场景
创作型任务失控:在故事生成中编造不符合设定的情节(如用户要求 “写一个科学家发现永动机的故事”,模型未识别违背物理定律)。
回答缺失信息时:用户询问未知内容(如 “某未公开的科研数据”),模型为 “迎合” 用户而虚构答案。
低概率事件误判:将小概率事件描述为必然(如 “吸烟一定不会导致肺癌”)。
解决方案
约束生成机制
引入拒绝采样:设定生成内容的 “事实置信度阈值”,低于阈值时输出 “无法回答” 或请求补充信息。
规则过滤:对敏感领域(医疗、法律)预设禁止生成的内容模式(如 “绝对化表述”“未证实的疗法”)。
强化学习与人类反馈(RLHF)
通过人类标注员对 “幻觉内容” 打标签,利用 PPO 等算法让模型学习 “拒绝虚构” 的策略(如优先输出已知信息,而非编造)。
示例:在医疗问答中,模型被训练为对未知病例回答 “建议咨询专业医生” 而非虚构诊断。
可解释性输出
要求模型生成内容时附带 “证据来源” 或 “推理依据”(如 “根据 XX 文献,该结论的支持率为 70%”),便于用户识别可靠性。
五、领域特异性幻觉:专业场景下的高精度要求
触发场景
医疗 / 法律等关键领域:生成错误诊断建议、法律条款引用错误,可能导致严重后果。
技术文档生成:混淆专业术语(如 “GPU” 与 “CPU” 的功能描述),或输出错误的操作步骤。
解决方案
领域知识注入
构建领域专属知识图谱(如医疗领域的疾病 - 症状 - 药物图谱),通过图神经网络(GNN)将结构化知识融入模型训练。
示例:法律模型训练时注入法条数据库,确保条款引用准确。
专家审核闭环
在应用层引入专家对生成内容进行人工校验,错误案例回流至训练数据,通过增量学习修正模型(如医疗问答系统的医生复核机制)。
混合专家模型(MoE)
针对不同领域部署专门的子模型,推理时根据问题领域动态路由至对应专家模块(如医疗问题由医疗专家模型处理)。
六、系统性解决方案:从架构到应用的多层防护
端到端幻觉检测框架
在推理流程中加入多阶段检测:
预处理阶段:分析问题是否需要外部知识(触发 RAG);
生成阶段:实时监控内容中的矛盾词、未知实体;
后处理阶段:通过交叉验证(如多模型投票)筛选可靠回答。
轻量化幻觉评估指标
开发实时评估工具(如基于困惑度、事实熵的指标),量化生成内容的 “幻觉风险”,动态调整生成策略(如高风险时降低创造力参数)。
用户教育与反馈机制
向用户明确说明模型的局限性(如标注 “生成内容可能存在不确定性”),并收集用户反馈的幻觉案例,持续优化模型。
什么是模型的过拟合
一、什么是模型的过拟合?
过拟合是指机器学习模型在训练过程中过度拟合训练数据的细节和噪声,导致模型在训练集上表现优异,但在未见过的新数据(测试集 / 实际应用) 上泛化能力显著下降的现象。本质是模型学习了训练数据中的 “特殊规律”(而非普遍规律),将噪声误认为真实模式。
二、大模型遇见过拟合的常见场景及原因
1. 数据层面的问题
场景 1:训练数据量不足或多样性匮乏
原因:大模型参数规模庞大(如千亿级参数),若训练数据量不足以覆盖其表达能力,模型会倾向于记忆训练样本的细节(甚至噪声),而非学习通用模式。例如,用少量领域数据微调通用大模型时,易因数据稀疏导致过拟合。
场景 2:数据质量差或存在噪声
原因:训练数据中包含错误标注、重复样本或无关信息,大模型可能过度拟合这些噪声,导致泛化能力下降。
场景 3:数据分布单一或与实际应用脱节
原因:训练数据集中于特定领域或场景(如仅含新闻文本),而实际应用数据分布更复杂(如混合对话、代码等),模型无法适应分布差异。
2. 模型结构与参数层面的问题
场景 1:模型参数规模与任务复杂度不匹配
原因:大模型参数过多(如 GPT-4 有万亿级参数),但下游任务(如简单分类)复杂度低,模型易利用多余参数拟合训练数据中的随机波动。
场景 2:模型组件设计过于灵活
原因:如注意力机制未加约束,或网络层数过深,导致模型捕捉到训练数据中的虚假关联(如文本中的高频无意义词汇)。
3. 训练过程中的问题
场景 1:训练迭代次数过多(“过训练”)
原因:训练过程中,模型在训练集上的损失持续下降,但验证集损失开始上升时未及时停止,导致模型过度拟合训练数据的细节。
场景 2:优化策略不当
原因:学习率过高导致参数更新震荡,或优化器对噪声敏感(如 SGD 未结合动量),使模型陷入局部最优,拟合噪声。
场景 3:正则化手段不足
原因:未使用或未正确使用 Dropout、权重衰减、早停等正则化方法,无法抑制模型对噪声的拟合。
4. 微调阶段的特有问题(大模型常见)
场景 1:预训练 - 微调阶段的分布差异
原因:大模型在预训练阶段接触海量数据,但微调时下游任务数据量少、分布窄,模型易遗忘预训练的通用知识,过度拟合微调数据。
场景 2:全参数微调导致 “灾难性遗忘”
原因:直接微调大模型全部参数时,少量微调数据难以更新海量参数,反而导致模型偏离预训练的泛化能力,过拟合下游任务的局部模式。
三、不同场景下的过拟合解决方案
1. 数据层面的优化
方案 1:增加数据量与多样性
方法:收集更多标注数据,或通过跨领域数据增强(如用文本生成模型扩充语料)、多任务学习(共享多领域数据)提升数据覆盖度。
示例:微调医疗大模型时,若数据不足,可结合公共医疗文本与合成病例数据(需确保真实性)。
方案 2:数据清洗与增强
方法:过滤噪声数据(如错误标注、重复样本),使用数据增强技术(如文本的同义词替换、句子重组,图像的旋转 / 裁剪),让模型学习更鲁棒的特征。
示例:NLP 任务中用 EDA(Easy Data Augmentation)生成近义词替换样本。
方案 3:数据分布对齐
方法:通过域适应(Domain Adaptation)技术,如对抗训练或数据加权,使训练数据分布接近实际应用场景。
示例:用生成模型合成接近真实场景的测试集风格数据,加入训练过程。
2. 模型结构与参数的优化
方案 1:简化模型或约束表达能力
方法:对大模型进行参数裁剪(如剪枝)、降低网络深度,或使用低秩近似(如 LoRA)减少可训练参数,避免模型过度复杂。
示例:在微调时冻结大模型的大部分预训练层,仅微调最后几层或适配器(Adapter)模块。
方案 2:引入正则化约束
方法:
Dropout:在训练中随机丢弃部分神经元,抑制模型对特定特征的依赖(如 NLP 中常用 0.1-0.3 的 Dropout 率);
权重衰减(L1/L2 正则):惩罚过大的权重参数,迫使模型学习更简洁的表达;
标签平滑(Label Smoothing):将硬标签(如 0/1)软化为概率分布(如 0.1/0.9),减少模型对训练标签的过度自信。
示例:在图像分类模型中使用 L2 正则化,降低权重矩阵的复杂度。
3. 训练策略的优化
方案 1:早停(Early Stopping)
方法:在训练过程中持续监控验证集性能,当验证集损失不再下降时立即停止训练,避免 “过训练”。
示例:每 10 个 epoch 评估一次验证集准确率,连续 5 次无提升则停止。
方案 2:优化学习率与训练算法
方法:
使用学习率调度(如余弦退火、warm-up),在训练后期降低学习率,避免参数震荡;
选用对噪声更鲁棒的优化器(如 AdamW,结合权重衰减),减少对局部噪声的拟合。
示例:Transformer 模型微调时常用线性 warm-up + 余弦衰减学习率策略。
方案 3:集成学习(Ensemble)
方法:训练多个不同初始化或结构的模型,通过投票或平均输出结果,降低单个模型过拟合的风险。
示例:微调 3 个不同种子的大模型,对生成的文本结果取多数投票。
4. 大模型微调阶段的特有方案
方案 1:参数高效微调(PEFT)技术
方法:
LoRA(Low-Rank Adaptation):冻结预训练参数,仅训练少量低秩适配器矩阵,减少可训练参数(如从千亿参数降至百万级);
Prefix Tuning/Prompt Tuning:在输入层添加可训练的连续提示向量,引导大模型适应下游任务,避免全参数微调。
优势:在数据稀缺场景下,通过限制微调参数规模,防止模型过拟合少量数据。
方案 2:知识蒸馏(Knowledge Distillation)
方法:用大模型(教师模型)生成软标签,训练小模型(学生模型),让小模型学习大模型的泛化能力,减少对训练数据的过拟合。
示例:用 GPT-4 生成文本摘要的软概率分布,训练一个更小的 Transformer 模型。
方案 3:混合预训练与微调策略
方法:在微调时加入少量预训练数据或通用任务,维持模型的泛化能力(如 “持续预训练”+ 微调)。
示例:微调医疗模型时,每批数据中混入 10% 的通用文本数据,避免模型过度聚焦医疗领域的局部模式。
5. 对抗训练与正则化增强
方案 1:对抗训练(Adversarial Training)
方法:向输入数据添加微小扰动(对抗样本),迫使模型学习对噪声不敏感的特征。
示例:在文本分类中,对输入句子添加语义无关的扰动词,训练模型正确分类扰动后的样本。
方案 2:自监督学习辅助
方法:在有监督微调数据中融入自监督任务(如掩码语言模型),利用大模型预训练的自监督能力增强泛化性。
示例:微调问答模型时,同时训练模型预测输入文本中被掩码的词汇,防止过拟合问答对数据。
正则化约束
在机器学习和统计学中,正则化约束是一种通过对模型参数施加限制来防止过拟合、提升模型泛化能力的技术。它的核心思想是在优化目标(如损失函数)中加入额外的 “约束项”,以此限制模型参数的取值范围,避免模型学习到训练数据中的噪声或细节特征。以下是更详细的解释:
一、正则化约束的背景:为什么需要它?
当模型复杂度过高(如神经网络层数过多、多项式回归次数过高)时,可能会出现过拟合:模型在训练数据上表现极好,但在新数据上效果很差。过拟合的本质是模型学习了训练数据中的 “特殊噪声” 或 “局部细节”,而忽略了数据的整体规律。 正则化约束的目的是通过 “惩罚” 复杂的模型,迫使模型选择更简单、更通用的解。简单来说,它就像给模型戴上 “紧箍咒”,不让参数 “肆意生长”,从而避免模型过度拟合训练数据。
二、正则化约束的数学本质:如何施加约束?
从数学角度看,正则化通常是在原始损失函数 \(L(\theta)\) 中加入一个正则化项 \(R(\theta)\),形成新的优化目标:\(\min_{\theta} \, L(\theta) + \lambda R(\theta)\) 其中 \(\theta\) 是模型参数,\(\lambda\) 是正则化强度(超参数,用于平衡原始损失和正则化约束的权重)。 这里的 \(R(\theta)\) 就是对参数的 “约束”,它通过限制参数的取值范围来间接约束模型复杂度。常见的正则化约束形式包括:
1. L2 正则化(岭回归,Ridge Regression)
约束项:参数的平方和,即
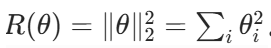
约束效果:惩罚大参数,使参数整体趋向于更小、更平滑的值,但不会让参数变为 0。直观理解:参数空间中,L2 正则化相当于将参数限制在一个以原点为中心的 “超球体” 内,避免参数值过大导致模型过度复杂。
2. L1 正则化(Lasso Regression)
约束项:参数的绝对值之和,即
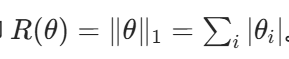
约束效果:惩罚参数的绝对值,更容易使部分参数变为 0,从而产生 “稀疏解”(即模型只保留重要特征的参数,其余设为 0)。直观理解:参数空间中,L1 正则化相当于将参数限制在一个 “超立方体” 内,其棱角处更容易与损失函数的最优解相交,导致参数稀疏化。
3. 弹性网络(Elastic Net)
约束项:L1 和 L2 的线性组合,即
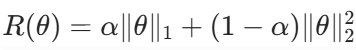
约束效果:结合了 L1 的稀疏性和 L2 的稳定性,适用于特征高度相关的场景。
三、正则化约束的直观理解:从 “参数空间” 到 “模型简化”
几何视角:正则化项相当于在参数空间中划定一个 “允许区域”,模型只能在该区域内寻找使损失函数最小的参数。例如:
L2 正则化的允许区域是圆形(二维)或超球体(高维),参数只能在球内取值,大参数会被推回球内。
L1 正则化的允许区域是菱形(二维)或超立方体(高维),其棱角更容易与损失函数的等值线相切,导致部分参数为 0。
模型简化视角:
对于神经网络,较大的权重参数意味着神经元对输入的响应更敏感,可能放大噪声影响。正则化通过限制权重大小,使网络对输入变化不那么敏感,从而减少过拟合。
对于线性模型,L1 正则化能剔除无关特征(对应参数为 0),L2 正则化能削弱噪声特征的影响(参数趋近于 0 但非零)。
四、正则化约束的核心作用
防止过拟合:通过限制参数复杂度,避免模型学习训练数据中的噪声,提升泛化能力。
参数平滑与稀疏性:L2 使参数更平滑,L1 使参数更稀疏(特征选择)。
缓解梯度爆炸:在深度网络中,过大的参数可能导致梯度爆炸,正则化通过限制参数值缓解这一问题。
五、实际应用中的注意事项
正则化强度 \(\lambda\) 的选择:
\(\lambda\) 过小:正则化效果弱,可能仍过拟合;
\(\lambda\) 过大:过度约束参数,模型可能欠拟合(偏差增大)。 通常需要通过交叉验证调整 \(\lambda\)。
L1 vs. L2 的选择:
若需要自动进行特征选择(筛选重要特征),选 L1;
若需要保持所有特征的影响(但削弱噪声特征),选 L2;
特征高度相关时,弹性网络效果更好。
在大模型领域,** 剪枝(Pruning)** 是一种通过移除模型中冗余参数或结构来降低模型复杂度的技术,旨在减少计算量、存储空间和推理延迟,同时尽量保持模型性能。其核心逻辑是:大模型中大量参数对最终输出影响微弱,移除这些 “不重要” 的部分可实现高效化。
模型压缩的几种方式
1. 剪枝(Pruning)
优点
压缩率灵活:可按需求删除 10%~90% 的参数,适配不同场景(如手机端可激进剪枝,云端保留更多精度)。
精度损失可控:合理剪枝(如基于重要性排序)后,部分模型(如 ResNet)精度损失可忽略。
硬件友好:减少计算量(如乘法次数),直接提升推理速度(尤其是结构化剪枝,如裁剪整层通道)。
缺点
依赖重训练:非结构化剪枝(如随机删参数)后需 Fine-tuning 恢复精度,计算成本高。
自动化难度高:需设计参数重要性评估标准(如 L1 范数、梯度幅度),不同模型适配性差异大。
稀疏矩阵支持有限:非结构化剪枝生成的稀疏模型需专用硬件(如 GPU 稀疏算子),通用设备加速效果可能不佳。
适用场景
对精度要求较高的场景(如自动驾驶模型轻量化)。
2. 知识蒸馏(Knowledge Distillation)
优点
精度保持能力强:学生模型可模仿教师模型的 “泛化能力”,甚至在某些任务上超越教师(如温度参数调节后)。
通用性高:不依赖模型结构,适用于任何可训练的模型(如 CNN、Transformer)。
训练流程标准化:只需设计师生模型结构和损失函数(如 KL 散度 + 交叉熵),工程实现简单。
缺点
依赖强教师模型:教师模型性能不足时,学生模型上限受限;且教师模型本身可能无法部署(如 GPT-4 只能作为教师)。
训练成本增加:需同时运行教师和学生模型,显存占用和计算量翻倍。
学生模型设计挑战:结构过小时(如参数 <100M),难以拟合复杂教师知识,易出现 “蒸馏坍塌”(输出趋近于均匀分布)。
适用场景
无重训练条件、需快速迁移大模型能力到小模型的场景(如 BERT→MobileBERT)。
3. 量化(Quantization)
优点
实现成本低:无需重训练即可压缩,适合快速部署(如 INT8 量化)。
硬件兼容性广:主流芯片均支持 INT8/INT4 计算,推理速度提升 2~4 倍。
精度损失可接受:浮点→INT8 量化在多数任务中精度损失 < 1%(如图像分类),INT4 需校准(如 KL 散度校准)。
缺点
低位数量化限制:INT2/INT1 量化精度损失显著(如 NLP 任务中 INT4 以下难以使用),需结合重训练(Quantization-Aware Training,QAT)。
任务敏感性:对数值精度敏感的任务(如生成式模型、金融预测)量化后效果下降明显。
动态范围挑战:极端值(如异常激活值)会导致量化误差,需动态量化(Per-Channel 量化)缓解。
适用场景
追求快速部署、对精度要求中等的场景(如手机端图像识别、语音唤醒)。
4. 二值化(Binarization)
优点
极致压缩率:参数仅用 1bit 表示(+1/-1),模型体积压缩至原 1/32,存储成本极低。
计算效率爆炸:仅需位运算(XOR、POPCOUNT),算力需求降至原 1/16,适合超低功耗设备(如 IoT 传感器)。
硬件加速友好:专用二值化神经网络芯片(如 Eyeriss)可实现百倍级推理加速。
缺点
精度损失严重:相比浮点模型,二值化在 ImageNet 等任务上精度下降 10%~20%,需特殊设计(如残差连接、多分支结构)缓解。
训练难度高:需使用 STE等技巧处理离散化梯度,收敛不稳定。
应用场景狭窄:仅适用于简单任务(如人脸识别、文本分类),复杂任务(如语义分割)效果差。
适用场景
对算力和存储极度敏感的边缘设备(如智能手表、摄像头),且可接受一定精度损失。
总结:四种方法的核心权衡
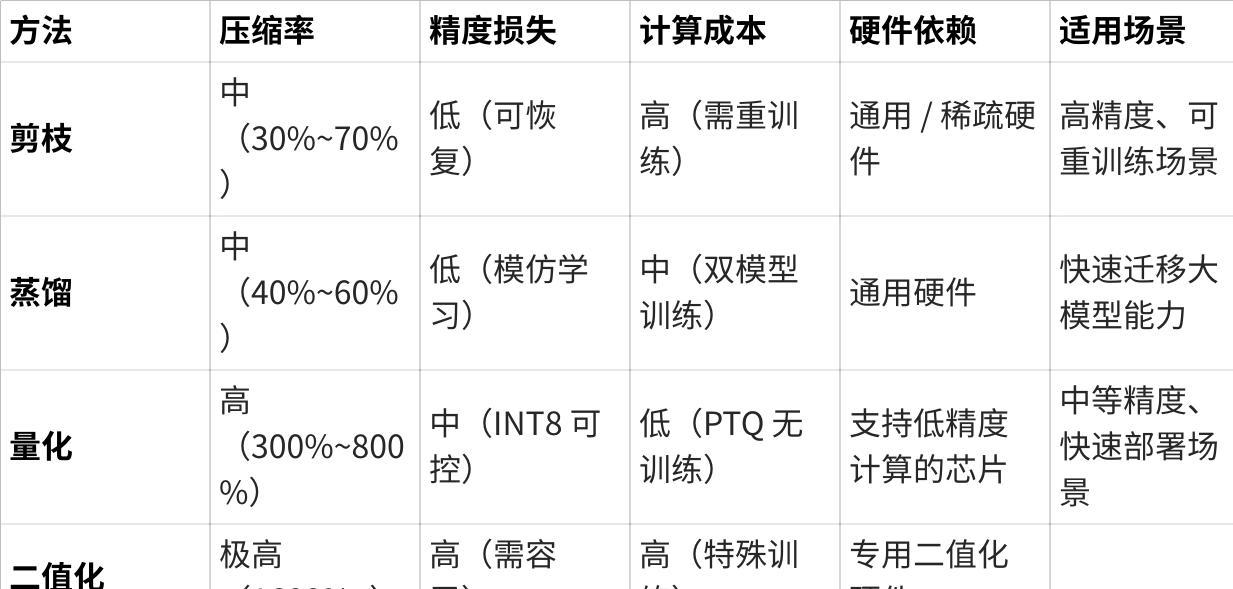
点击图片可查看完整电子表格
剪枝是什么意思
一、剪枝的核心机制
冗余识别
通过权重绝对值、梯度信息、激活频率等指标,评估参数或结构的重要性。例如,权重接近零的连接通常被认为对模型贡献较小。
案例:在 LLaVA 多模态模型中,研究发现约 50% 的视觉注意力头未被激活,这些头可被安全移除。
剪枝操作
非结构化剪枝:逐参数删除(如将小权重置零),生成稀疏矩阵。例如,SparseGPT 方法在 OPT-175B 模型中实现 60% 稀疏度,困惑度仅小幅上升。
结构化剪枝:按规则移除整组结构(如神经元、注意力头、层)。例如,英伟达通过剪枝 Llama 3.1 的注意力头和通道,将模型从 8B 压缩至 4B,性能仍优于同类模型。
性能恢复
剪枝后需通过微调或知识蒸馏修复性能。例如,YOPO 方法在剪枝 LLaVA 后,通过邻域感知注意力和层跳过策略,将计算量压缩至 12% 且性能无损。
二、大模型剪枝的挑战与突破
硬件适配性
非结构化剪枝需依赖稀疏计算硬件(如 GPU 的 Tensor Core),否则加速效果有限。结构化剪枝因保留规整结构,更易在通用硬件上部署。
创新方案:Flash-LLM 通过 “稀疏加载 + 密集计算” 优化非结构化剪枝的 GPU 执行效率。
跨模态与架构适配
多模态模型:视觉 token 数量庞大导致计算冗余。YOPO 方法通过限制视觉 token 仅与邻近 token 交互,将注意力复杂度从 O (N²) 降至 O (N)。
MoE 架构:Mixtral 8x7B 模型通过专家剪枝(移除 4 个专家)和动态跳跃(跳过次要专家),内存占用减少 48%,推理速度提升 1.33 倍。
领域特定优化
通用剪枝可能损害特定任务性能。例如,Mixtral 模型在数学推理任务中,使用 MATH 数据集校准剪枝专家,GSM8K 准确率从 41% 提升至 51%。
三、实际应用与效果
模型压缩案例
LLaVA:通过视觉注意力剪枝、前馈网络稀疏化等策略,计算量压缩至 12%,性能与原模型相当。
Llama 3.1:英伟达将 8B 模型剪枝蒸馏为 4B 的 Llama-3.1-Minitron,在多项基准测试中超越 Phi-2、Qwen2 等模型。
部署效率提升
内存节省:Mixtral 8x7B 剪枝 4 个专家后,内存占用从 89GB 降至 47GB,可在单卡 80G GPU 部署。
推理加速:结合剪枝与动态跳跃,Mixtral 模型推理速度提升 1.33 倍,性能损失仅 3.65 点。
四、与其他技术的协同
量化:剪枝后对剩余参数进行低精度量化,进一步减少存储和计算量。例如,PyTorch 的 prune 库支持剪枝后量化。
蒸馏:将剪枝后的 “学生模型” 与原始 “教师模型” 对齐。英伟达通过蒸馏将 Llama 3.1 8B 压缩为 4B,性能接近原模型。
动态优化:如动态专家跳跃,根据路由权重实时决定是否跳过专家,平衡速度与精度。
稀疏检索与稠密检索
稀疏检索与稠密检索是 RAG 系统中两种核心检索范式,其核心差异可从表示方法、检索逻辑、能力边界三个维度深入理解:
一、核心差异对比表
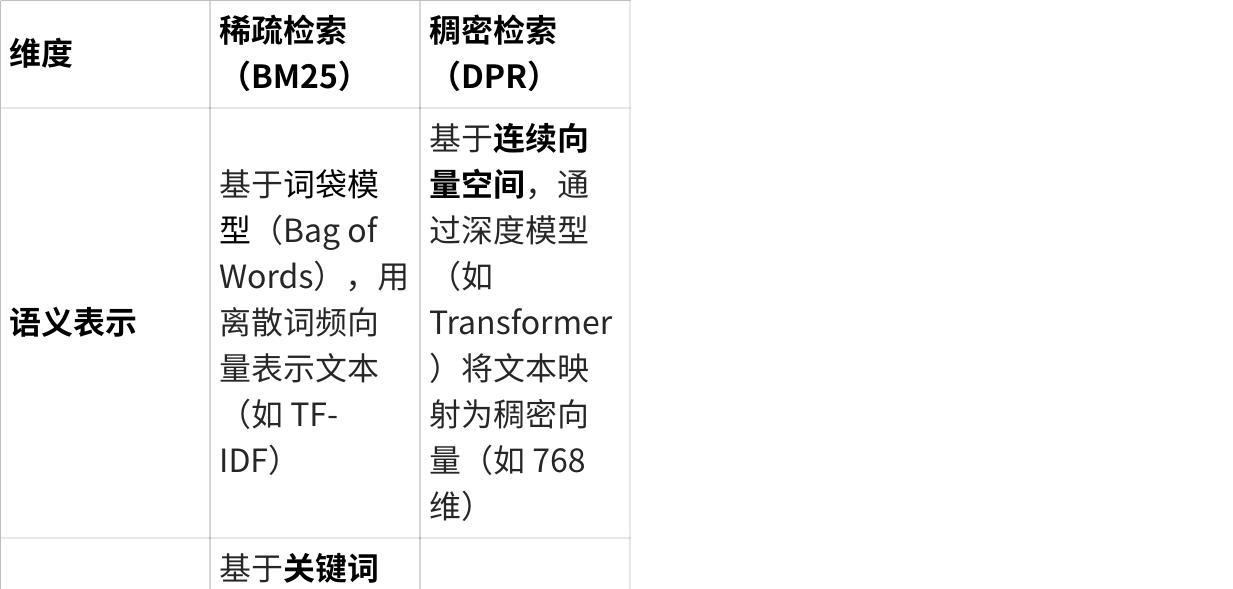
点击图片可查看完整电子表格
二、技术原理解析
稀疏检索(以 BM25 为例)
核心公式:
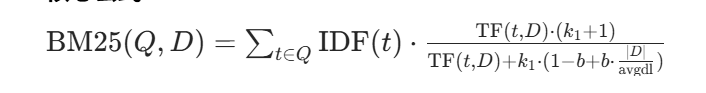
其中:
TF(t,D)为词 t 在文档 D 中的词频;
IDF(t) 为词 t 的逆文档频率;
k_1 和 b 为调节参数(b 用于文档长度归一化,避免长文档因词频高而被过度匹配)。
本质:通过词频统计量化 “关键词重叠度”,属于精确匹配逻辑,不考虑语义隐含关系。
稠密检索(以 DPR 为例)
模型架构: 采用双塔结构(Query Encoder 和 Document Encoder),分别将查询和文档编码为向量,通过对比学习训练模型,使语义相关的查询 - 文档对在向量空间中距离更近。
检索过程:
预计算所有文档的向量并存储在向量数据库(如 Milvus、Chroma);
将查询编码为向量,通过余弦相似度检索最相似的文档向量。
本质:将文本语义映射到连续向量空间,通过几何距离度量语义相关性,属于语义匹配逻辑。
三、工程实践中的互补应用
实际 RAG 系统中,两者常结合使用以平衡效率和准确性:
粗筛 + 精排架构:
先用 BM25 进行稀疏检索,快速过滤出数千篇候选文档(召回率高但相关性可能不足);
再用 DPR 进行稠密检索,从候选集中精挑细选数十篇高语义相关的文档(提升准确率)。
混合检索权重调整: 通过融合两者的得分(如 BM25 分数 × 稠密相似度),兼顾关键词精确匹配和语义泛化能力。
rag文档分块的方式有哪些
在 RAG(检索增强生成)系统中,文档分块(Chunking)是将长文档拆分为适合检索和上下文输入的短文本块(Chunks)的关键步骤。分块策略直接影响检索精度和生成效果,以下是主流分块方法及其优缺点的详细分析:
一、基于长度的分块策略
1. 固定长度分块(Fixed-Length Chunking)
核心逻辑:按预设 token 数(如 500 tokens)或字符数截断文档,不考虑语义边界。
优点:
简单高效:实现成本低,适合大规模文档预处理;
均匀分块:便于统一索引和检索,避免长文本计算过载。
缺点:
语义断裂风险:可能在句子中间截断,导致分块内信息不完整(如 “机器学习是人工智能的核心...” 被截断为 “机器学习是人工”);
依赖参数调优:token 长度设置过短会增加检索碎片,过长则降低上下文相关性。
应用场景:初步数据处理、非结构化文本(如新闻、博客)的快速分块,常见于 LangChain 的RecursiveCharacterTextSplitter默认配置。
2. 滑动窗口分块(Sliding Window Chunking)
核心逻辑:设置固定块长度和重叠长度(如块长 500 tokens,重叠 100 tokens),逐段滑动生成块。
优点:
减少语义断裂:重叠部分保留上下文连续性(如前一块结尾是 “机器学习”,后一块开头是 “是人工智能的核心”);
检索鲁棒性:查询匹配到块中间时,重叠部分可提供完整语义。
缺点:
数据冗余:重叠部分增加索引存储和检索计算量;
参数敏感:重叠率过高会降低效率,过低则失去意义(通常建议重叠率 20%-30%)。
应用场景:对语义完整性要求较高的场景,如法律文档、学术论文分块,Elasticsearch 的向量检索常使用此策略。
二、基于语义与结构的分块策略
1. 基于标点符号 / 段落的分块(Punctuation/Paragraph Chunking)
核心逻辑:以自然语言边界(句号、段落分隔符、标题等)作为分块断点,结合长度限制。
优点:
语义完整性强:分块符合人类阅读习惯,如以段落为单位保留完整语义;
适配文本特性:对结构化文本(如带标题的报告)分块效果好。
缺点:
长段落问题:遇到无标点的长段落(如代码注释)可能生成超长块,超出模型上下文限制;
多语言适配差:不同语言标点规则不同(如中文无空格),需定制化处理。
应用场景:小说、论文等自然段落分明的文本,常见于 spaCy 的文本分块工具。
2. 基于语义边界的分块(Semantic Boundary Chunking)
核心逻辑:使用语言模型(如 BERT)预测文本语义连贯性,在语义断裂处(如主题切换点)分块。
优点:
语义最精准:分块内主题统一,避免无关信息混入(如科技文章中不会同时包含 “机器学习” 和 “市场营销” 内容);
动态适应内容:自动识别长文档中的章节切换、话题转换。
缺点:
计算成本高:需逐段运行语言模型,预处理时间长;
模型依赖强:依赖预训练模型的语义理解能力,对专业领域文档可能失效。
应用场景:对精度要求极高的场景(如医疗、金融文档),可结合 Hugging Face 的语义分割模型实现。
3. 基于文档结构的分块(Structure-Aware Chunking)
核心逻辑:利用文档的格式结构(如 HTML 标签、Markdown 标题、PDF 章节)作为分块依据。
优点:
保留逻辑层次:按章节、小节分块,便于检索时定位完整知识单元;
减少噪声:过滤无关结构信息(如页眉、页脚)。
缺点:
依赖文档格式:非结构化文本(如纯文本)无法使用;
结构多样性:不同文档结构标准不一,需定制解析规则。
应用场景:PDF 报告、维基百科条目等结构化文档,可通过 PyMuPDF、BeautifulSoup 等工具实现。
三、混合策略与高级分块方法
1. 递归分块(Recursive Chunking)
核心逻辑:先按结构分块(如段落),再对超长块递归应用固定长度分块,确保块长不超过阈值。
优点:
平衡语义与长度:先保证自然分块,再截断超长部分,减少语义损失;
自适应不同文本:对短段落保留完整语义,对长段落强制分块。
缺点:
实现复杂度高:需多层逻辑判断,处理效率略低于单一策略。
应用场景:通用场景下的默认分块策略,LangChain 的RecursiveCharacterTextSplitter即采用此逻辑。
2. 基于查询的动态分块(Query-Driven Chunking)
核心逻辑:根据用户查询实时调整分块策略,聚焦相关内容分块。
优点:
精准匹配需求:针对查询主题动态合并或拆分块,减少无关信息;
提升检索效率:避免全量分块的冗余计算。
缺点:
实时计算开销:需为每个查询动态处理文档,不适合批量检索;
依赖查询理解:需先通过 NLP 解析查询意图,存在误判风险。
应用场景:交互式问答系统(如客服机器人),可结合检索 - 分块 - 再检索的循环流程。
3. 知识图谱增强分块(KG-Enhanced Chunking)
核心逻辑:结合知识图谱中的实体关系,将文档按实体关联度分块(如同一实体的相关内容合并为一块)。
优点:
增强知识关联性:分块内包含实体的完整上下文,便于生成时引用;
支持复杂问题:如查询 “爱因斯坦的相对论” 时,分块可包含相关理论背景和应用。
缺点:
依赖 KG 构建:需预先生成领域知识图谱,成本较高;
通用性差:仅适用于特定领域(如科学文献、百科知识)。
应用场景:垂直领域 RAG 系统(如生物医学问答),可结合 Neo4j 等图数据库实现。
向量归一化(如 L2 归一化)在 RAG 中的作用是什么?
向量归一化是稠密检索(如基于 Transformer 的向量表示)的关键预处理步骤,其核心作用体现在数学原理和工程实践两方面:
数学层面:确保相似度计算的合理性
余弦相似度的本质要求:稠密检索通常使用余弦相似度衡量向量相关性,公式为: \(\text{cosine}(a, b) = \frac{a \cdot b}{||a|| \cdot ||b||}\) 若向量未归一化(即\(||a||\)和\(||b||\)不为 1),则相似度计算会受向量长度影响。例如,两个语义相似但长度差异大的向量可能因模长不同被误判为不相关。L2 归一化(将向量缩放到单位长度,\(||a||=1\))可使余弦相似度简化为向量点积,仅反映方向相关性,避免长度偏差。
数值稳定性优化:归一化后向量元素的数值范围被约束(如 [-1, 1]),减少大规模向量检索时的浮点运算误差,尤其在高维空间中(如 768 维的 BERT 向量),避免因数值溢出导致的相似度计算错误。
工程层面:提升检索效率与一致性
检索效率优化:归一化后,向量相似度计算可简化为点积运算,适配硬件加速(如 GPU/TPU 的矩阵乘法优化);同时,向量数据库(如 FAISS)的索引构建(如 IVF-PQ)依赖归一化后的向量分布,确保聚类和量化精度。
跨模型 / 跨批次的兼容性:不同模型或不同批次生成的向量可能因训练参数、输入数据差异导致模长波动。归一化可消除这种波动,使不同来源的向量在同一度量空间中可比。例如,预训练模型和微调模型生成的向量经归一化后,可直接用余弦相似度检索。
温度系数调优的基础:在稠密检索中,常通过温度系数\(\tau\)调整相似度分布(如\(\text{sim}' = \text{sim}/\tau\)),归一化后的向量点积范围固定([-1, 1]),使温度系数的调节效果更稳定,便于控制检索结果的聚焦程度。
如何避免 RAG 生成无关内容?
要避免检索增强生成(RAG)系统生成无关内容,需从查询理解、检索准确性、文档处理、生成控制等全流程优化。以下是具体策略及实现方法:
一、精准查询理解与扩展
增强查询语义表示
使用预训练语言模型(如 BERT、GPT)生成查询的语义嵌入,捕捉深层语义(而非仅关键词匹配),减少因一词多义导致的检索偏差。
引入查询扩展技术:通过同义词词典、WordNet 等扩展查询词(如 “电脑”→“计算机”“PC”),或利用生成模型补全隐含信息(如 “2024 年 AI 发展趋势”→补充 “最新研究”“应用案例” 等)。
歧义消解与上下文感知
对多义查询增加主题约束(如 “苹果” 区分为 “水果” 或 “公司”),可通过历史对话上下文或文档库主题分布辅助判断。
对长查询进行分块处理,确保每个子查询对应文档的局部相关性。
二、优化检索环节:提高文档相关性
混合检索策略
向量检索 + 传统检索结合:
向量检索(如 FAISS)捕捉语义相似性,解决 “词汇不匹配” 问题(如查询 “机器学习优化” 检索到含 “深度学习调参” 的文档);
结合 BM25 等词袋模型,确保关键词精确匹配,避免向量检索因语义泛化引入无关文档。
多轮检索与查询重写:
首次检索后,根据返回文档的关键词重新生成查询(如 “根据检索结果中的‘Transformer 架构’补充‘注意力机制’关键词”),迭代优化检索结果。
检索结果重排序
使用重排序模型(如 BERT-based reranker)对初始检索结果排序,过滤掉语义不相关但词频匹配的文档。例如,通过计算查询与文档的交叉注意力分数,保留高相关性的前k篇文档。
设置相关性阈值:若最高得分文档的分数低于阈值,则触发 “无相关文档” 提示,避免基于噪声生成内容。
三、文档预处理:减少噪声输入
智能分块与语义切分
避免固定长度分块(如 512 字),采用语义分块(如基于段落、章节或主题边界),确保每个块包含完整语义单元。例如,将学术论文按 “摘要”“方法”“结论” 分块,避免跨章节信息混杂。
引入分块重叠(如 10% 重叠率),保留跨块上下文(如句子被截断时的完整语义)。
文档过滤与质量控制
去除重复文档(通过向量相似度去重)、低质量文档(如字数过少、格式混乱)或过时信息(根据时间戳过滤旧数据)。
构建文档元数据索引(如主题、领域、可信度标签),检索时优先选择高可信度、主题匹配的文档。
四、生成阶段:约束模型依赖检索内容
提示工程强化文档依赖
在生成提示中明确要求 “基于以下文档回答”,并添加惩罚机制(如生成与文档无关内容时降低概率)。例如:
plaintext
Plain Text
请根据提供的文档信息回答问题,若文档中无相关内容,请说明‘无法从文档中获取信息’。文档:[...]\n问题:[...]
使用 “检索 - 生成 - 验证” 流水线:先生成候选回答,再通过文档匹配模型验证答案中的关键信息是否存在于文档中,剔除无依据的内容。
解码策略调控
降低生成温度(Temperature≤0.5),减少模型自由发挥的随机性,使其更依赖文档中的具体信息。
结合 Top-K/Top-P 采样时,限制生成词只能来自文档中出现的词汇(词汇表过滤),或通过前缀约束(如生成答案必须包含文档中的关键词)。
五、引入反馈机制与迭代优化
用户反馈与主动学习
收集用户对生成结果的相关性标注(如 “相关”“部分相关”“无关”),将负例用于微调检索模型或生成模型,增强系统对 “相关性” 的识别能力。
对高频无关问题触发追问流程(如 “您的问题涉及 XX 领域,是否需要补充具体场景?”),明确用户需求。
系统自评估与监控
定期用测试集评估 RAG 系统的 “文档利用率”(生成答案中来自文档的信息占比)和 “无关内容率”,若发现异常则定位检索或生成模块的问题。
通过可视化工具监控检索文档与问题的匹配度(如注意力权重热图),诊断相关性低的环节。
六、数据与模型层面的深层优化
构建领域专属文档库
针对垂直领域(如医疗、法律)清洗文档,确保信息专业性和准确性,减少通用语料中的噪声干扰。
对文档进行实体链接和关系抽取,建立知识图谱,辅助检索时的语义推理(如查询 “糖尿病治疗” 时关联 “胰岛素”“血糖监测” 等实体)。
端到端优化 RAG 架构
使用联合训练框架(如检索器与生成器共享参数),让模型学习 “检索 - 生成” 的整体相关性,而非独立优化两个模块。
引入对比学习:构造正负例(相关 / 无关文档对),训练检索器区分真正相关的文档,降低假阳性率。
DeepSeek-V3 的多词元预测方法相比一次预测一个词元有什么优势?
DeepSeek-V3 的多词元预测方法(Multi-Token Prediction, MTP)在样本利用效率和推理效率上展现出显著优势,具体体现在以下方面:
一、样本利用效率的突破
密集训练信号加速学习
MTP 通过在每个训练步骤中预测多个未来 token(如 2-4 个),将训练信号密度提升数倍。例如,传统自回归模型每个位置仅提供 1 个 token 的监督信号,而 MTP 可同时提供多个 token 的监督,使模型在相同训练时间内接收更丰富的学习信息。这种设计显著加快了模型收敛速度,实验显示 MTP 在训练早期即可达到更高的预测准确性,尤其在长文本生成任务中,模型能更好地捕捉上下文依赖关系。
参数共享与架构优化
MTP 采用共享的 Transformer 主干和独立输出头的设计,既减少了冗余计算,又通过参数共享降低了模型总参数量。例如,共享的解嵌入矩阵(维度通常为 d×V,V 为词表大小)显著节省了内存占用,同时独立输出头允许并行生成多个 token,进一步提升训练效率。此外,MTP 的损失函数(如交叉熵损失平均化)通过多任务学习机制增强了模型的泛化能力,在相同数据量下实现更高的性能提升。
上下文利用的深度增强
MTP 通过将当前 token 的表示与后续 token 的嵌入拼接,生成更丰富的上下文表示。例如,在预测第 k 个 token 时,模型会融合前 k-1 个 token 的信息,从而形成更长的依赖链。这种设计使模型能够更高效地利用输入序列的全局信息,尤其在处理复杂语义(如逻辑推理、代码生成)时,MTP 的上下文建模能力显著优于传统自回归模型。
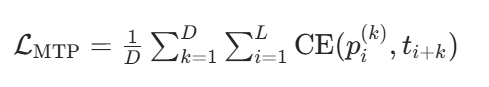
D 为预测深度(如 D=2),L 为序列长度,\(p_{i}^{(k)}\)为第 k 个模块对位置 i+k 的预测概率,\(t_{i+k}\)为真实 token
二、推理效率的革命性提升
并行生成减少解码步骤
传统自回归模型逐 token 生成的方式导致解码步骤与输出长度成正比,而 MTP 通过单次前向传播生成多个 token,直接减少了 70%-80% 的解码次数。例如,生成 100 个 token 时,MTP 仅需 25-50 次前向计算,而传统模型需 100 次。这种优化在实时对话、长文本生成等场景中显著降低了延迟,实测显示 MTP 在代码生成任务中推理速度提升 3 倍以上。
推测解码与验证修正结合
MTP 可与推测解码(speculative decoding)结合,通过并行生成草稿 token 并由主模型验证,实现 “一次生成多次修正”。例如,MTP 模块先并行生成 4 个草稿 token,主模型通过单次前向传播验证并修正,接受率高达 85%-90%,最终实现 1.8 倍的推理加速。这种机制在保证生成质量的同时,大幅提升了吞吐量,DeepSeek-V3 的实测生成速度达到每秒 60 token,是前代模型的 3 倍。
硬件资源的高效调度
MTP 的并行计算特性充分利用了 GPU/TPU 的并行处理能力。例如,在 NVIDIA H800 集群上,MTP 通过跨节点专家并行(Expert Parallelism)和计算 - 通信重叠技术,将预填充阶段的吞吐量提升至每秒 73.7k token,解码阶段提升至每秒 14.8k token。此外,MTP 模块在推理时可动态丢弃,根据计算资源灵活调整计算负载,进一步优化了能效比。
三、综合性能与场景适配
长文本生成的连贯性优化
MTP 通过预规划多个 token 的生成路径,有效减少了传统自回归模型中常见的 “上下文断裂” 问题。例如,在生成技术文档或代码时,MTP 能更好地保持逻辑一致性,实测在 MBPP 代码生成任务中 pass@1 指标提升 17%。这种优势源于 MTP 对多 token 联合概率的建模,而非独立 token 的条件概率、。
多语言与专业领域的泛化能力
MTP 的上下文建模能力使其在多语言任务中表现突出。例如,DeepSeek-V3 在中文事实知识测试(C-SimpleQA)中超越 GPT-4o,在数学竞赛(MATH500)中正确率达 90.2%,显著优于传统模型。此外,MTP 对代码生成的优化(如 Codeforces 得分 51.6)使其成为开发者工具的理想选择。
训练与推理的解耦设计
MTP 模块在训练时作为辅助目标提升性能,推理时可独立运行或与主模型协同。例如,在实时交互场景中,MTP 可关闭以降低延迟;在高精度需求场景中,可启用 MTP 模块进行深度推理。这种灵活性使 DeepSeek-V3 在不同算力环境下均能保持高效运行。
如果有标注的训练数据很少,如何扩增训练数据的数量?
一、数据增强(Data Augmentation):基于现有数据的直接扩展
核心思想:对原始数据进行合理变换,生成语义不变但形式不同的新样本,适用于图像、文本、语音等多种模态。
1. 图像领域经典方法
几何变换:旋转(±15°)、翻转(水平 / 垂直)、缩放(0.8-1.2 倍)、裁剪(随机 crop)、平移(小范围偏移)。
例:将一张猫的图片旋转 10°,生成新样本。
像素级变换:添加高斯噪声、调整亮度 / 对比度 / 饱和度、色彩抖动(Color Jitter)、模糊(高斯模糊)。
高级增强策略:
Mixup:将两张图像按权重叠加,标签也线性组合(如 0.7 倍猫图 + 0.3 倍狗图,标签为 “0.7 猫 + 0.3 狗”)。
CutMix:裁剪一张图像的区域并粘贴到另一张图像上,结合标签信息。
Cutout:随机遮挡图像中的矩形区域,提升模型对局部特征的鲁棒性。
2. 文本领域增强方法
同义词替换:用近义词替换句子中的词汇(如 “喜欢”→“喜爱”),可借助 WordNet 等工具。
句子结构变换:调整语序(如主动句→被动句)、插入 / 删除虚词(“的”“了”)。
回译(Back-translation):将句子翻译成其他语言(如英文),再译回中文,生成语义相近但表达不同的句子。
掩码填充:随机掩盖句子中的词,让模型预测(类似 BERT 的 MLM 任务),间接生成新样本。
3. 语音领域增强方法
音频扰动:调整音量、添加背景噪声(如风声、人声)、时间拉伸(变速不变调)。
频谱变换:在梅尔频谱上添加随机噪声,或进行频率掩蔽(Frequency Masking)。
注意事项:
增强后的样本需保持语义一致性(如不能将猫图旋转到无法识别)。
可通过交叉验证确定最佳增强策略(过度增强可能引入噪声)。
二、迁移学习与预训练模型:借力大模型的泛化能力
核心思想:利用预训练模型在大规模无标注数据上学习的通用特征,适配到小数据集任务。
1. 冻结 + 微调策略
图像任务:使用 ResNet、ViT 等预训练模型,冻结底层特征提取层,仅微调最后几层分类器。
文本任务:基于 BERT、GPT 等预训练模型,针对下游任务(如情感分析)进行少量数据微调。
例:用 BERT-base 在 200 条标注影评上微调,性能可能超过随机初始化模型在 2000 条数据上的效果。
2. 领域适配(Domain Adaptation)
若有相关领域的大量标注数据(如医疗文本与通用文本),可通过对抗训练(如 DANN)减少领域差异。
或使用预训练模型 + 领域内无标注数据进行二次预训练(如 “预训练→领域内自监督→任务微调”)。
3. 参数高效微调(PEFT)
当数据极少时,可采用 LoRA、Prefix-Tuning 等技术,仅微调少量参数(如 0.1%),避免过拟合。
三、半监督学习:利用大量未标注数据
核心思想:用少量标注数据指导模型学习,同时从未标注数据中挖掘潜在模式。
1. 自训练(Self-training)
步骤:
用标注数据训练模型 M;
用 M 对未标注数据预测,筛选高置信度样本作为 “伪标签”;
将伪标签数据加入训练集,重复迭代。
注意:伪标签可能存在错误,建议设置置信度阈值(如 > 0.9),或结合集成学习(多模型投票生成伪标签)。
2. 一致性正则化(Consistency Regularization)
对未标注数据添加扰动(如图像加噪声、文本换同义词),强制模型对 “扰动前后样本” 预测一致。
典型方法:Temporal Ensembling、Mean Teacher(教师 - 学生模型,教师模型平滑学生模型的预测)。
3. 伪标签与真实标签混合训练
用标注数据计算交叉熵损失,用伪标签数据计算 KL 散度损失(强制模型输出与伪标签一致),平衡两者权重。
四、主动学习(Active Learning):智能选择最有价值的样本标注
核心思想:通过算法筛选 “对模型提升最大” 的未标注样本,让人工标注效率最大化。
1. 不确定性采样(Uncertainty Sampling)
筛选模型最 “不确定” 的样本(如分类概率接近 0.5),这类样本可能包含新的知识模式。
方法:MC Dropout(通过多次前向传播估计预测方差)、熵采样(概率分布熵值高的样本)。
2. 多样性采样(Diversity Sampling)
用聚类等方法将未标注数据分组,从每个组中选代表性样本,覆盖更多样本空间。
结合不确定性与多样性:如 K-means++ 聚类后,从每个簇中选不确定性最高的样本。
3. 基于模型结构的采样
对 CNN,可关注激活值差异大的区域对应的样本;对 NLP,可分析注意力机制聚焦的关键 token。
通过“let’s think step by step”提示词触发的思维链模式,与推理模型的原理有什么不同?同样是测试时计算,为什么推理模型的上限更高?
要理解 “let’s think step by step” 触发的思维链(Chain of Thought, CoT)模式与推理模型原理的差异,以及推理模型上限更高的原因,我们可以从机制本质和能力边界两方面逐步分析:
一、思维链模式与推理模型原理的核心差异
两者的核心区别在于能力的来源与载体不同:
思维链(CoT)模式:提示工程驱动的 “能力激活”
思维链模式本质是一种提示工程技术,其核心逻辑是:通过自然语言提示(如 “让我们一步步思考”)引导模型在输出最终答案前,先 “口述” 中间推理步骤。
它不改变模型的参数或架构,仅通过调整输入提示的格式,激活模型已有的潜在推理能力。例如,当模型本身具备简单数学推理能力,但直接输出答案时可能出错,CoT 提示会让它 “展开计算过程”(如 “先算加法,再算乘法”),从而降低失误。
其效果高度依赖基础模型的固有能力:如果模型本身缺乏复杂推理所需的知识或逻辑处理能力,即使使用 CoT 提示,也无法生成有效的中间步骤(比如让一个仅训练过日常对话的模型用 CoT 解高等数学题,结果仍会荒谬)。
推理模型:架构与训练驱动的 “能力内置”
推理模型(如专门优化过逻辑推理、数学推理的模型)的核心是模型自身的参数与架构已编码了更强的推理能力,其能力来源于训练与设计阶段的优化:
架构上,可能采用更深的网络层(处理多步推理)、更大的上下文窗口(保存中间信息)、或专门的模块(如逻辑推理单元、数学运算子网络);
训练上,可能使用包含大量推理步骤的标注数据(如数学证明、逻辑推导过程),让模型从数据中学习推理规则(如因果关系、逻辑运算符),并将这些规则编码到参数中。
它不依赖特定提示即可表现出强推理能力,例如无需 “一步步思考” 的提示,也能自主完成多步逻辑推导。
二、为何推理模型的上限更高(即使测试时计算量相近)
“测试时计算” 指模型在处理任务时的前向传播计算(如注意力机制的计算、隐藏层的特征转换等)。两者虽都涉及测试时计算,但推理模型的上限更高,核心原因是能力的 “深度” 与 “适配性” 差异:
CoT 的能力受限于基础模型的 “天花板”
CoT 的本质是 “展开” 模型已有的能力,而非 “提升” 能力。例如,一个基础模型最多只能处理 3 步逻辑推理,CoT 提示能让它清晰输出这 3 步,但无法让它完成第 4 步 —— 因为模型的架构(如网络深度、上下文容量)和参数中根本没有编码处理第 4 步的能力。
其测试时的计算仅是 “输出格式的扩展”(多输出几句话),但计算的核心逻辑(如注意力分配、特征提取)仍受限于基础模型的设计,无法突破其固有瓶颈。
推理模型的架构与训练直接适配 “复杂推理”
推理模型的设计从根源上优化了 “推理计算” 的路径:
例如,为处理数学推理,模型可能加入专门的 “符号运算模块”,在测试时计算中直接调用数学规则(如四则运算优先级),而非依赖模糊的自然语言联想;
为处理长逻辑链,模型可能采用更深的 Transformer 层,让每个层专注于处理推理链中的一个子步骤(如 “前提→中间结论→最终结论”),且更大的上下文窗口能保存更多中间信息,避免遗忘;
训练时,模型参数已编码了更通用的推理规则(如 “如果 A→B,且 B→C,则 A→C”),测试时无需依赖提示引导,就能自主应用这些规则完成深层推理。
推理模型的 “计算效率” 更高
复杂推理任务(如多步数学证明、逻辑谬误识别)需要模型在测试时进行 “精准计算”(如跟踪变量、验证逻辑一致性)。推理模型因架构优化,这些计算能在内部高效完成(如通过专门模块快速验证逻辑链);而 CoT 模式下,模型需用自然语言 “描述” 每一步计算,这一过程可能引入冗余信息或错误(如用词不当导致逻辑断裂),反而降低效率。
